cnn svm
1.0.0
โปรเจ็กต์นี้ได้รับแรงบันดาลใจจากการเรียนรู้เชิงลึกของ Y. Tang โดยใช้ Linear Support Vector Machines (2013)
บทความฉบับเต็มเกี่ยวกับโครงการนี้สามารถอ่านได้ที่ arXiv.org
โครงข่ายประสาทเทียมแบบหมุน (CNN) มีความคล้ายคลึงกับโครงข่ายประสาทเทียม "ธรรมดา" ในแง่ที่ว่ามันประกอบด้วยเลเยอร์ที่ซ่อนอยู่ซึ่งประกอบด้วยเซลล์ประสาทที่มีพารามิเตอร์ "เรียนรู้ได้" เซลล์ประสาทเหล่านี้รับอินพุต ดำเนินการดอทโปรดัค แล้วตามด้วยความไม่เชิงเส้น เครือข่ายทั้งหมดแสดงการจับคู่ระหว่างพิกเซลรูปภาพดิบกับคะแนนชั้นเรียน ตามอัตภาพ ฟังก์ชัน Softmax เป็นตัวแยกประเภทที่ใช้ในเลเยอร์สุดท้ายของเครือข่ายนี้ อย่างไรก็ตาม มีการศึกษาวิจัย (Alalshekmubarak and Smith, 2013; Agarap, 2017; Tang, 2013) ที่ดำเนินการเพื่อท้าทายบรรทัดฐานนี้ การศึกษาที่อ้างถึงได้แนะนำการใช้เครื่องเวกเตอร์ที่รองรับเชิงเส้น (SVM) ในสถาปัตยกรรมเครือข่ายประสาทเทียม โครงการนี้เป็นอีกหนึ่งหัวข้อที่ได้รับแรงบันดาลใจจาก (Tang, 2013) ข้อมูลเชิงประจักษ์แสดงให้เห็นว่าโมเดล CNN-SVM สามารถบรรลุความแม่นยำในการทดสอบที่ ~99.04% โดยใช้ชุดข้อมูล MNIST (LeCun, Cortes และ Burges, 2010) ในทางกลับกัน CNN-Softmax สามารถบรรลุความแม่นยำในการทดสอบที่ ~99.23% โดยใช้ชุดข้อมูลเดียวกัน ทั้งสองรุ่นยังได้รับการทดสอบกับชุดข้อมูล Fashion-MNIST ที่เพิ่งเผยแพร่เมื่อเร็วๆ นี้ (Xiao, Rasul และ Vollgraf, 2017) ซึ่งคาดว่าจะเป็นชุดข้อมูลการจำแนกประเภทภาพที่ยากกว่า MNIST (Zalandoresearch, 2017) ซึ่งพิสูจน์แล้วว่าเป็นเช่นนั้น เนื่องจาก CNN-SVM มีความแม่นยำในการทดสอบที่ ~90.72% ในขณะที่ CNN-Softmax มีความแม่นยำในการทดสอบอยู่ที่ ~91.86% ผลลัพธ์ดังกล่าวอาจได้รับการปรับปรุงหากใช้เทคนิคการประมวลผลข้อมูลล่วงหน้ากับชุดข้อมูล และหากแบบจำลอง CNN พื้นฐานค่อนข้างซับซ้อนกว่าที่ใช้ในการศึกษานี้
ขั้นแรก โคลนโครงการ
git clone https://github.com/AFAgarap/cnn-svm.git/ รัน setup.sh เพื่อให้แน่ใจว่าไลบรารีที่จำเป็นต้องมีได้รับการติดตั้งในสภาพแวดล้อม
sudo chmod +x setup.sh
./setup.shพารามิเตอร์ของโปรแกรม
usage: main.py [-h] -m MODEL -d DATASET [-p PENALTY_PARAMETER] -c
CHECKPOINT_PATH -l LOG_PATH
CNN & CNN-SVM for Image Classification
optional arguments:
-h, --help show this help message and exit
Arguments:
-m MODEL, --model MODEL
[1] CNN-Softmax, [2] CNN-SVM
-d DATASET, --dataset DATASET
path of the MNIST dataset
-p PENALTY_PARAMETER, --penalty_parameter PENALTY_PARAMETER
the SVM C penalty parameter
-c CHECKPOINT_PATH, --checkpoint_path CHECKPOINT_PATH
path where to save the trained model
-l LOG_PATH, --log_path LOG_PATH
path where to save the TensorBoard logs จากนั้นไปที่ไดเร็กทอรีของที่เก็บและรันโมดูล main.py ตามพารามิเตอร์ที่ต้องการ
cd cnn-svm
python3 main.py --model 2 --dataset ./MNIST_data --penalty_parameter 1 --checkpoint_path ./checkpoint --log_path ./logsไฮเปอร์พารามิเตอร์ที่ใช้ในโปรเจ็กต์นี้ถูกกำหนดด้วยตนเอง ไม่ใช่ผ่านการเพิ่มประสิทธิภาพ
| ไฮเปอร์พารามิเตอร์ | CNN-Softmax | ซีเอ็นเอ็น-SVM |
|---|---|---|
| ขนาดชุด | 128 | 128 |
| อัตราการเรียนรู้ | 1e-3 | 1e-3 |
| ขั้นตอน | 10,000 | 10,000 |
| เอสวีเอ็ม ซี | ไม่มี | 1 |
การทดลองดำเนินการบนคอมพิวเตอร์แล็ปท็อปที่ใช้ Intel Core(TM) i5-6300HQ CPU @ 2.30GHz x 4, DDR3 RAM ขนาด 16GB และ NVIDIA GeForce GTX 960M 4GB DDR5 GPU
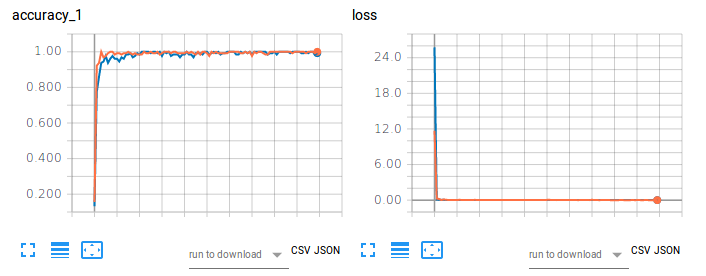
รูปที่ 1 ความแม่นยำในการฝึกอบรม (ซ้าย) และการสูญเสีย (ขวา) ของ CNN-Softmax และ CNN-SVM ในการจัดหมวดหมู่ภาพโดยใช้ MNIST
แผนสีส้มหมายถึงความแม่นยำในการฝึกและการสูญเสียของ CNN-Softmax โดยมีความแม่นยำในการทดสอบ 99.22999739646912% ในทางกลับกัน แผนภาพสีน้ำเงินหมายถึงความแม่นยำในการฝึกและการสูญเสียของ CNN-SVM โดยมีความแม่นยำในการทดสอบ 99.04000163078308% ผลลัพธ์ไม่ได้ยืนยันการค้นพบของ Tang (2017) สำหรับการจำแนกตัวเลขที่เขียนด้วยลายมือของ MNIST นี่อาจเป็นผลมาจากการที่ไม่มีการประมวลผลข้อมูลล่วงหน้าหรือการลดขนาดบนชุดข้อมูลสำหรับโปรเจ็กต์นี้
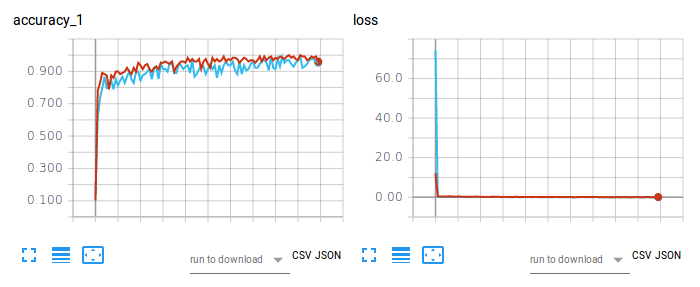
รูปที่ 2 ความแม่นยำในการฝึกอบรม (ซ้าย) และการสูญเสีย (ขวา) ของ CNN-Softmax และ CNN-SVM ในการจัดหมวดหมู่ภาพโดยใช้ Fashion-MNIST
แผนสีแดงหมายถึงความแม่นยำในการฝึกและการสูญเสียของ CNN-Softmax โดยมีความแม่นยำในการทดสอบ 91.86000227928162% ในทางกลับกัน แผนภาพสีฟ้าอ่อนหมายถึงความแม่นยำในการฝึกและการสูญเสียของ CNN-SVM โดยมีความแม่นยำในการทดสอบ 90.71999788284302% ผลลัพธ์ของ CNN-Softmax ยืนยันการค้นพบโดย zalandoresearch ใน Fashion-MNIST
หากต้องการอ้างอิงบทความนี้ โปรดใช้รายการ BibTex ต่อไปนี้:
@article{agarap2017architecture,
title={An Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification},
author={Agarap, Abien Fred},
journal={arXiv preprint arXiv:1712.03541},
year={2017}
}
หากต้องการอ้างอิงพื้นที่เก็บข้อมูล/ซอฟต์แวร์ โปรดใช้รายการ BibTex ต่อไปนี้:
@misc{abien_fred_agarap_2017_1098369,
author = {Abien Fred Agarap},
title = {AFAgarap/cnn-svm v0.1.0-alpha},
month = dec,
year = 2017,
doi = {10.5281/zenodo.1098369},
url = {https://doi.org/10.5281/zenodo.1098369}
}
Copyright 2017-2020 Abien Fred Agarap
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


