soundstorm pytorch
0.5.0
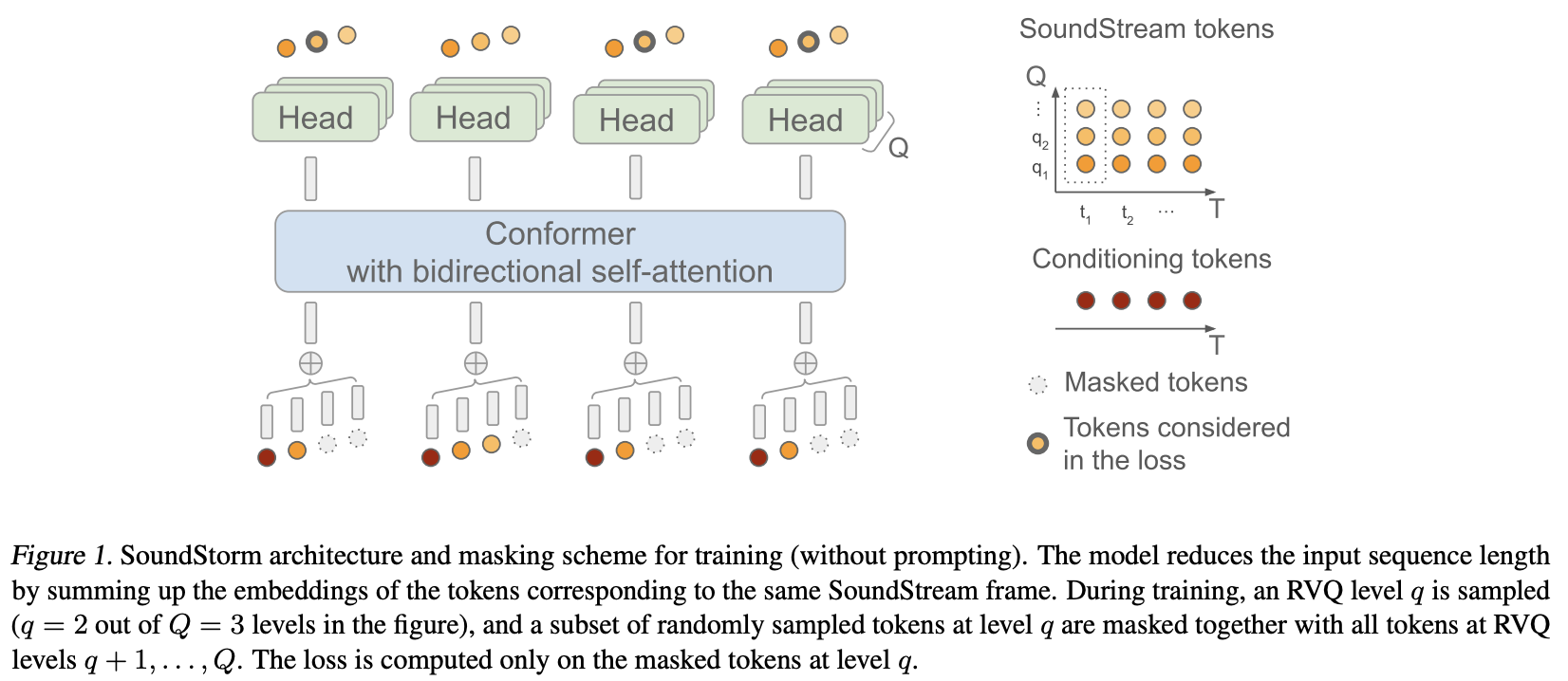
การใช้งาน SoundStorm การสร้างเสียงคู่ขนานที่มีประสิทธิภาพจาก Google Deepmind ใน Pytorch
โดยทั่วไปแล้ว พวกเขาใช้ MaskGiT กับโค้ดเวกเตอร์เชิงปริมาณที่เหลือจาก Soundstream สถาปัตยกรรมหม้อแปลงที่พวกเขาเลือกใช้นั้นเป็นสถาปัตยกรรมที่เหมาะกับโดเมนเสียงที่ชื่อว่า Conformer
หน้าโครงการ
ความมั่นคงและ ? Huggingface สำหรับการสนับสนุนอันใจดีของพวกเขาในการทำงานและการวิจัยปัญญาประดิษฐ์ที่ล้ำหน้าแบบโอเพ่นซอร์ส
Lucas Newman สำหรับการสนับสนุนมากมาย รวมถึงโค้ดการฝึกอบรมเบื้องต้น ตรรกะการแจ้งเตือนแบบอะคูสติก การถอดรหัสควอไลเซอร์ต่อระดับ!
- เร่งความเร็วในการจัดหาโซลูชันที่ง่ายและทรงพลังสำหรับการฝึกอบรม
Einops สำหรับสิ่งที่เป็นนามธรรมที่ขาดไม่ได้ซึ่งทำให้การสร้างโครงข่ายประสาทเทียมเป็นเรื่องสนุก ง่าย และยกระดับคุณภาพ
Steven Hillis สำหรับการส่งกลยุทธ์การปิดบังที่ถูกต้องและสำหรับการตรวจสอบว่าพื้นที่เก็บข้อมูลใช้งานได้!
Lucas Newman สำหรับการฝึก Soundstorm ที่ทำงานขนาดเล็กโดยพื้นฐานด้วยแบบจำลองในที่เก็บข้อมูลหลายแห่ง ซึ่งแสดงให้เห็นว่าทุกอย่างใช้งานได้ตั้งแต่ต้นจนจบ โมเดลประกอบด้วย SoundStream, Text-to-Semantic T5 และสุดท้ายคือตัวแปลง SoundStorm ที่นี่
@ Jiang-Stan สำหรับการระบุจุดบกพร่องที่สำคัญในการ demasking ซ้ำ!
$ pip install soundstorm-pytorch import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
model = SoundStorm (
conformer ,
steps = 18 , # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# get your pre-encoded codebook ids from the soundstream from a lot of raw audio
codes = torch . randint ( 0 , 1024 , ( 2 , 1024 , 12 )) # (batch, seq, num residual VQ)
# do the below in a loop for a ton of data
loss , _ = model ( codes )
loss . backward ()
# model can now generate in 18 steps. ~2 seconds sounds reasonable
generated = model . generate ( 1024 , batch_size = 2 ) # (2, 1024) หากต้องการฝึกเสียง Raw โดยตรง คุณจะต้องส่ง SoundStream ที่ได้รับการฝึกมาแล้วไปยัง SoundStorm คุณสามารถฝึก SoundStream ของคุณเองได้ที่ audiolm-pytorch
import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper , Conformer , SoundStream
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
soundstream = SoundStream (
codebook_size = 1024 ,
rq_num_quantizers = 12 ,
attn_window_size = 128 ,
attn_depth = 2
)
model = SoundStorm (
conformer ,
soundstream = soundstream # pass in the soundstream
)
# find as much audio you'd like the model to learn
audio = torch . randn ( 2 , 10080 )
# course it through the model and take a gazillion tiny steps
loss , _ = model ( audio )
loss . backward ()
# and now you can generate state-of-the-art speech
generated_audio = model . generate ( seconds = 30 , batch_size = 2 ) # generate 30 seconds of audio (it will calculate the length in seconds based off the sampling frequency and cumulative downsamples in the soundstream passed in above) การแปลงข้อความเป็นคำพูดที่สมบูรณ์จะขึ้นอยู่กับตัวแปลงตัวเข้ารหัส / ตัวถอดรหัส TextToSemantic ที่ได้รับการฝึกอบรม จากนั้นคุณจะโหลดตุ้มน้ำหนักและส่งผ่านไปยัง SoundStorm เป็น spear_tts_text_to_semantic
นี่เป็นงานที่อยู่ระหว่างดำเนินการ เนื่องจาก spear-tts-pytorch มีเฉพาะสถาปัตยกรรมโมเดลที่สมบูรณ์เท่านั้น และไม่ใช่ตรรกะ pretraining + pseudo-labeling + backtranslation
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic (
dim = 512 ,
source_depth = 12 ,
target_depth = 12 ,
num_text_token_ids = 50000 ,
num_semantic_token_ids = 20000 ,
use_openai_tokenizer = True
)
# load the trained text-to-semantic transformer
text_to_semantic . load ( '/path/to/trained/model.pt' )
# pass it into the soundstorm
model = SoundStorm (
conformer ,
soundstream = soundstream ,
spear_tts_text_to_semantic = text_to_semantic
). cuda ()
# and now you can generate state-of-the-art speech
generated_speech = model . generate (
texts = [
'the rain in spain stays mainly in the plain' ,
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - raw waveform decoded from soundstream บูรณาการกระแสเสียง
เมื่อสร้างและสามารถกำหนดความยาวได้เป็นวินาที (ใช้ความถี่ในการสุ่มตัวอย่าง ฯลฯ )
ตรวจสอบให้แน่ใจว่ารองรับ rvq ที่จัดกลุ่มแล้ว เชื่อมต่อการฝังเข้าด้วยกันแทนที่จะรวมข้ามมิติกลุ่ม
เพียงคัดลอกคอนฟอร์เมอร์ไปและทำซ้ำการฝังตำแหน่งสัมพัทธ์ของชอว์ด้วยการฝังแบบหมุน ไม่มีใครใช้ชอว์อีกต่อไป
ความสนใจแฟลชเริ่มต้นเป็นจริง
ลบ batchnorm และใช้ layernorm แต่หลังจากหวด (เช่นเดียวกับในกระดาษ normformer)
ผู้ฝึกสอนที่มีความเร่ง - ขอบคุณ @lucasnewman
อนุญาตให้มีการฝึกอบรมและการสร้างลำดับความยาวผันแปรโดยส่งผ่าน mask ไป forward และ generate
ตัวเลือกในการส่งคืนรายการไฟล์เสียงเมื่อสร้าง
เปลี่ยนเป็นเครื่องมือบรรทัดคำสั่ง
เพิ่มความสนใจแบบข้ามและการปรับสภาพเลเยอร์นอร์มแบบปรับได้
@misc { borsos2023soundstorm ,
title = { SoundStorm: Efficient Parallel Audio Generation } ,
author = { Zalán Borsos and Matt Sharifi and Damien Vincent and Eugene Kharitonov and Neil Zeghidour and Marco Tagliasacchi } ,
year = { 2023 } ,
eprint = { 2305.09636 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

