rotary embedding torch
0.8.6
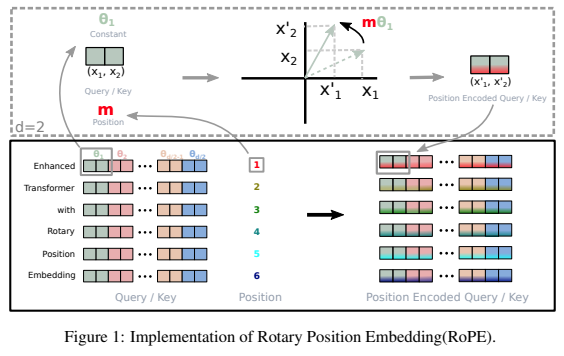
ไลบรารีแบบสแตนด์อโลนสำหรับการเพิ่มการฝังแบบหมุนให้กับหม้อแปลงใน Pytorch หลังจากประสบความสำเร็จในการเข้ารหัสตำแหน่งแบบสัมพัทธ์ โดยเฉพาะอย่างยิ่ง จะทำให้การหมุนข้อมูลลงในแกนใดๆ ของเทนเซอร์เป็นเรื่องง่ายและมีประสิทธิภาพ ไม่ว่าจะเป็นตำแหน่งคงที่หรือแบบเรียนรู้ก็ตาม ไลบรารีนี้จะให้ผลลัพธ์ที่ทันสมัยสำหรับการฝังตำแหน่งโดยมีค่าใช้จ่ายเพียงเล็กน้อย
สัญชาตญาณของฉันยังบอกฉันว่ามีบางอย่างเพิ่มเติมเกี่ยวกับการหมุนที่สามารถใช้ประโยชน์ได้ในโครงข่ายประสาทเทียม
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usualหากคุณทำตามขั้นตอนทั้งหมดข้างต้นอย่างถูกต้อง คุณจะเห็นพัฒนาการที่ดีขึ้นอย่างมากระหว่างการฝึก
เมื่อจัดการกับคีย์ / ค่าแคชในการอนุมาน ตำแหน่งแบบสอบถามจะต้องชดเชยด้วย key_value_seq_length - query_seq_length
เพื่อให้ง่ายขึ้น ให้ใช้เมธอด rotate_queries_with_cached_keys
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )คุณสามารถทำได้ด้วยตนเองเช่นกัน
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])เพื่อให้ง่ายต่อการใช้งานการฝังตำแหน่งสัมพัทธ์ตามแนวแกน n มิติ เช่น หม้อแปลงวิดีโอ
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k ) ในบทความนี้ พวกเขาสามารถแก้ไขปัญหาการประมาณค่าความยาวด้วยการฝังแบบหมุนได้โดยการทำให้มันสลายตัวคล้ายกับ ALiBi พวกเขาตั้งชื่อเทคนิคนี้ว่า XPos และคุณสามารถใช้งานได้โดยตั้งค่า use_xpos = True ในการเริ่มต้น
สามารถใช้กับหม้อแปลงแบบออโต้รีเกรสซีฟเท่านั้น
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )เอกสาร MetaAI นี้เสนอการปรับแต่งอย่างละเอียดในการประมาณค่าตำแหน่งลำดับเพื่อขยายไปสู่ความยาวบริบทที่ยาวขึ้นสำหรับโมเดลที่ได้รับการฝึกล่วงหน้า พวกเขาแสดงให้เห็นว่าสิ่งนี้ทำงานได้ดีกว่าการปรับแต่งตำแหน่งลำดับเดียวกันแบบละเอียดแต่ขยายออกไปอีกมาก
คุณสามารถใช้สิ่งนี้ได้โดยการตั้ง interpolate_factor ในการเริ่มต้นเป็นค่าที่มากกว่า 1. (เช่น หากโมเดลที่ได้รับการฝึกล่วงหน้าได้รับการฝึกในปี 2048 การตั้งค่า interpolate_factor = 2. จะทำให้สามารถปรับละเอียดเป็น 2048 x 2. = 4096 )
อัปเดต: มีคนในชุมชนรายงานว่ามันทำงานได้ไม่ดี โปรดส่งอีเมลถึงฉันหากคุณเห็นผลลัพธ์ที่เป็นบวกหรือลบ
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

