audiolm pytorch
2.2.3
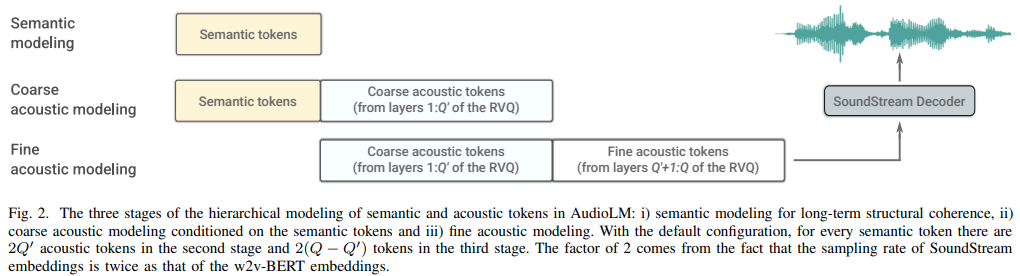
การใช้ AudioLM ซึ่งเป็นแนวทางการสร้างแบบจำลองภาษาเพื่อสร้างเสียงจากการวิจัยของ Google ใน Pytorch
นอกจากนี้ยังขยายการทำงานในการปรับสภาพด้วยคำแนะนำแบบไม่มีตัวแยกประเภทด้วย T5 ซึ่งช่วยให้ผู้ใช้สามารถแปลงข้อความเป็นเสียงหรือ TTS ที่ไม่มีในรายงานได้ ใช่ หมายความว่าสามารถฝึก VALL-E ได้จากพื้นที่เก็บข้อมูลนี้ โดยพื้นฐานแล้วมันเหมือนกัน
กรุณาเข้าร่วมหากคุณสนใจที่จะทำซ้ำงานนี้ในที่สาธารณะ
ขณะนี้พื้นที่เก็บข้อมูลนี้ยังมี SoundStream เวอร์ชันลิขสิทธิ์ของ MIT อีกด้วย นอกจากนี้ยังเข้ากันได้กับ EnCodec ซึ่งได้รับอนุญาตจาก MIT ในขณะที่เขียนอีกด้วย
อัปเดต: AudioLM ใช้เพื่อ 'แก้ไข' การสร้างเพลงใน MusicLM ใหม่เป็นหลัก
ต่อไปคลิปหนังเรื่องนี้คงไม่มีความหมายอีกต่อไป คุณจะแจ้งให้ AI แทน
Stability.ai สำหรับการสนับสนุนการทำงานและการวิจัยปัญญาประดิษฐ์ที่ทันสมัยแบบโอเพ่นซอร์ส
- Huggingface สำหรับการเร่งความเร็วที่น่าทึ่งและไลบรารีหม้อแปลง
MetaAI สำหรับ Fairseq และใบอนุญาตแบบเสรีนิยม
@eonglints และ Joseph ที่ให้คำแนะนำและความเชี่ยวชาญอย่างมืออาชีพตลอดจนดึงคำขอ!
@djqualia, @yigityu, @inspirit และ @BlackFox1197 สำหรับความช่วยเหลือในการดีบักสตรีมเสียง
Allen และ LW การเขียนโปรแกรมเพื่อตรวจสอบโค้ดและส่งการแก้ไขข้อบกพร่อง!
Ilya สำหรับการค้นหาปัญหาเกี่ยวกับการลดขนาดการเลือกปฏิบัติแบบหลายสเกล และสำหรับการปรับปรุงเครื่องฝึกสตรีมเสียง
Andrey สำหรับการระบุการสูญเสียที่หายไปในสตรีมเสียงและแนะนำฉันผ่านไฮเปอร์พารามิเตอร์เมลสเปกโตรแกรมที่เหมาะสม
Alejandro และ Ilya สำหรับการแบ่งปันผลลัพธ์ของพวกเขาด้วยสตรีมเสียงการฝึกอบรม และสำหรับการทำงานผ่านปัญหาบางประการเกี่ยวกับการฝังตำแหน่งความสนใจในท้องถิ่น
การเขียนโปรแกรม LW เพื่อเพิ่มความเข้ากันได้ของ Encodec!
การเขียนโปรแกรม LW เพื่อค้นหาปัญหาเกี่ยวกับการจัดการโทเค็น EOS เมื่อสุ่มตัวอย่างจาก FineTransformer !
@YoungloLee สำหรับการระบุจุดบกพร่องใหญ่ในการบิดเชิงสาเหตุ 1d สำหรับสตรีมเสียงที่เกี่ยวข้องกับการเสริมที่ไม่คำนึงถึงความก้าวหน้า!
เฮย์เดนสำหรับการชี้ให้เห็นความแตกต่างบางประการในตัวแบ่งแยกหลายระดับสำหรับ Soundstream
$ pip install audiolm-pytorchมีสองตัวเลือกสำหรับตัวแปลงสัญญาณประสาท หากคุณต้องการใช้ Encodec 24kHz ที่ได้รับการฝึกมาแล้ว เพียงสร้างออบเจ็กต์ Encodec ดังนี้:
from audiolm_pytorch import EncodecWrapper
encodec = EncodecWrapper ()
# Now you can use the encodec variable in the same way you'd use the soundstream variables below. มิฉะนั้น เพื่อให้ตรงตามต้นฉบับมากขึ้น คุณสามารถใช้ SoundStream ได้ ขั้นแรก SoundStream จะต้องได้รับการฝึกอบรมเกี่ยวกับคลังข้อมูลเสียงขนาดใหญ่
from audiolm_pytorch import SoundStream , SoundStreamTrainer
soundstream = SoundStream (
codebook_size = 4096 ,
rq_num_quantizers = 8 ,
rq_groups = 2 , # this paper proposes using multi-headed residual vector quantization - https://arxiv.org/abs/2305.02765
use_lookup_free_quantizer = True , # whether to use residual lookup free quantization - there are now reports of successful usage of this unpublished technique
use_finite_scalar_quantizer = False , # whether to use residual finite scalar quantization
attn_window_size = 128 , # local attention receptive field at bottleneck
attn_depth = 2 # 2 local attention transformer blocks - the soundstream folks were not experts with attention, so i took the liberty to add some. encodec went with lstms, but attention should be better
)
trainer = SoundStreamTrainer (
soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 4 ,
grad_accum_every = 8 , # effective batch size of 32
data_max_length_seconds = 2 , # train on 2 second audio
num_train_steps = 1_000_000
). cuda ()
trainer . train ()
# after a lot of training, you can test the autoencoding as so
soundstream . eval () # your soundstream must be in eval mode, to avoid having the residual dropout of the residual VQ necessary for training
audio = torch . randn ( 10080 ). cuda ()
recons = soundstream ( audio , return_recons_only = True ) # (1, 10080) - 1 channel จากนั้น SoundStream ที่ผ่านการฝึกอบรมของคุณจะสามารถใช้เป็นโทเค็นไนเซอร์ทั่วไปสำหรับเสียงได้
audio = torch . randn ( 1 , 512 * 320 )
codes = soundstream . tokenize ( audio )
# you can now train anything with the codebook ids
recon_audio_from_codes = soundstream . decode_from_codebook_indices ( codes )
# sanity check
assert torch . allclose (
recon_audio_from_codes ,
soundstream ( audio , return_recons_only = True )
) คุณยังสามารถใช้สตรีมเสียงเฉพาะสำหรับ AudioLM และ MusicLM ได้โดยการนำเข้า AudioLMSoundStream และ MusicLMSoundStream ตามลำดับ
from audiolm_pytorch import AudioLMSoundStream , MusicLMSoundStream
soundstream = AudioLMSoundStream (...) # say you want the hyperparameters as in Audio LM paper
# rest is the same as above ในเวอร์ชัน 0.17.0 ตอนนี้คุณสามารถเรียกใช้เมธอดคลาสบน SoundStream เพื่อโหลดจากไฟล์จุดตรวจสอบ โดยไม่ต้องจำการกำหนดค่าของคุณ
from audiolm_pytorch import SoundStream
soundstream = SoundStream . init_and_load_from ( './path/to/checkpoint.pt' ) หากต้องการใช้การติดตามน้ำหนักและอคติ ขั้นแรกให้ตั้งค่า use_wandb_tracking = True บน SoundStreamTrainer จากนั้นให้ทำดังต่อไปนี้
trainer = SoundStreamTrainer (
soundstream ,
...,
use_wandb_tracking = True
)
# wrap .train() with contextmanager, specifying project and run name
with trainer . wandb_tracker ( project = 'soundstream' , run = 'baseline' ):
trainer . train () จากนั้นจำเป็นต้องฝึกอบรมหม้อแปลงสามตัวแยกกัน ( SemanticTransformer , CoarseTransformer , FineTransformer )
อดีต. SemanticTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
# hubert checkpoints can be downloaded at
# https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
flash_attn = True
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () อดีต. CoarseTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SoundStream , CoarseTransformer , CoarseTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
coarse_transformer = CoarseTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
codebook_size = 1024 ,
num_coarse_quantizers = 3 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = CoarseTransformerTrainer (
transformer = coarse_transformer ,
codec = soundstream ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train () อดีต. FineTransformer
import torch
from audiolm_pytorch import SoundStream , FineTransformer , FineTransformerTrainer
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
fine_transformer = FineTransformer (
num_coarse_quantizers = 3 ,
num_fine_quantizers = 5 ,
codebook_size = 1024 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = FineTransformerTrainer (
transformer = fine_transformer ,
codec = soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()กันหมดแล้วครับ
from audiolm_pytorch import AudioLM
audiolm = AudioLM (
wav2vec = wav2vec ,
codec = soundstream ,
semantic_transformer = semantic_transformer ,
coarse_transformer = coarse_transformer ,
fine_transformer = fine_transformer
)
generated_wav = audiolm ( batch_size = 1 )
# or with priming
generated_wav_with_prime = audiolm ( prime_wave = torch . randn ( 1 , 320 * 8 ))
# or with text condition, if given
generated_wav_with_text_condition = audiolm ( text = [ 'chirping of birds and the distant echos of bells' ])อัปเดต: ดูเหมือนว่าจะใช้งานได้หากได้รับ 'VALL-E'
อดีต. หม้อแปลงความหมาย
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = 500 ,
dim = 1024 ,
depth = 6 ,
has_condition = True , # this will have to be set to True
cond_as_self_attn_prefix = True # whether to condition as prefix to self attention, instead of cross attention, as was done in 'VALL-E' paper
). cuda ()
# mock text audio dataset (as an example)
# you will have to extend your own from `Dataset`, and return an audio tensor as well as a string (the audio description) in any order (the framework will autodetect and route it into the transformer)
from torch . utils . data import Dataset
class MockTextAudioDataset ( Dataset ):
def __init__ ( self , length = 100 , audio_length = 320 * 32 ):
super (). __init__ ()
self . audio_length = audio_length
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
mock_audio = torch . randn ( self . audio_length )
mock_caption = 'audio caption'
return mock_caption , mock_audio
dataset = MockTextAudioDataset ()
# instantiate semantic transformer trainer and train
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
dataset = dataset ,
batch_size = 4 ,
grad_accum_every = 8 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()
# after much training above
sample = trainer . generate ( text = [ 'sound of rain drops on the rooftops' ], batch_size = 1 , max_length = 2 ) # (1, < 128) - may terminate early if it detects [eos] เพราะคลาสเทรนเนอร์ทั้งหมดใช้ ? ตัวเร่งความเร็ว คุณสามารถฝึก multi gpu ได้อย่างง่ายดายโดยใช้คำสั่ง accelerate เช่นนั้น
ที่รากโครงการ
$ accelerate configจากนั้นในไดเร็กทอรีเดียวกัน
$ accelerate launch train . py CoarseTransformer ที่สมบูรณ์
ใช้ fairseq vq-wav2vec สำหรับการฝัง
เพิ่มเครื่องปรับอากาศ
เพิ่มคำแนะนำลักษณนามฟรี
เพิ่มความเป็นเอกลักษณ์ติดต่อกันสำหรับ
รวมความสามารถในการใช้คุณลักษณะระดับกลางของ Hubert เป็นโทเค็นเชิงความหมายที่แนะนำโดย onglints
รองรับเสียงที่มีความยาวผันแปรได้ และนำโทเค็น eos เข้ามา
ตรวจสอบให้แน่ใจว่าทำงานต่อเนื่องกันไม่ซ้ำกันกับหม้อแปลงไฟฟ้าหยาบ
ค่อนข้างพิมพ์การสูญเสียผู้เลือกปฏิบัติทั้งหมดเพื่อบันทึก
จัดการเมื่อสร้างโทเค็นความหมาย การบันทึกครั้งล่าสุดอาจไม่จำเป็นต้องเป็นครั้งสุดท้ายในลำดับที่ได้รับการประมวลผลต่อเนื่องกันที่ไม่ซ้ำกัน
โค้ดสุ่มตัวอย่างที่สมบูรณ์สำหรับทั้ง Coarse และ Fine Transformers ซึ่งจะยุ่งยาก
ตรวจสอบให้แน่ใจว่าการอนุมานแบบเต็มโดยมีหรือไม่มีการพร้อมท์ทำงานในคลาส AudioLM
กรอกรหัสการฝึกอบรมเต็มรูปแบบสำหรับสตรีมเสียง ดูแลการฝึกอบรมผู้เลือกปฏิบัติ
เพิ่มการลงโทษการไล่ระดับที่มีประสิทธิภาพสำหรับผู้แยกแยะสำหรับสตรีมเสียง
ต่อสาย hz ตัวอย่างจากชุดข้อมูลเสียง -> หม้อแปลง และมีการสุ่มตัวอย่างใหม่อย่างเหมาะสมในระหว่างการฝึกอบรม - ลองคิดดูว่าจะอนุญาตให้ชุดข้อมูลมีไฟล์เสียงที่แตกต่างกันหรือบังคับใช้ตัวอย่าง hz เดียวกันหรือไม่
รหัสการฝึกอบรมหม้อแปลงเต็มรูปแบบสำหรับหม้อแปลงทั้งสามตัว
refactor ดังนั้น semantic Transformer จึงมี wrapper ที่จะจัดการการต่อเนื่องที่ไม่ซ้ำกันรวมถึง wav ถึง hubert หรือ vq-wav2vec
เพียงแค่ไม่ดูแลโทเค็น eos ด้วยตนเองในด้านการกระตุ้น (ความหมายสำหรับหม้อแปลงหยาบ, หยาบสำหรับหม้อแปลงละเอียด)
เพิ่มการออกกลางคันที่มีโครงสร้างจากการปกปิดสาเหตุที่ลืมได้ ดีกว่าการออกกลางคันแบบเดิมมาก
หาวิธีระงับการบันทึกใน fairseq
ยืนยันว่าหม้อแปลงทั้งสามตัวที่ส่งผ่านไปยัง audiolm นั้นเข้ากันได้
อนุญาตให้มีการฝังตำแหน่งสัมพัทธ์เฉพาะในหม้อแปลงปรับละเอียดโดยอิงตามตำแหน่งการจับคู่สัมบูรณ์ของควอนไทเซอร์ระหว่างหยาบและละเอียด
อนุญาตให้จัดกลุ่ม vq ที่เหลือในสตรีมเสียง (ใช้ GroupedResidualVQ จาก vector-quantize-pytorch lib) จาก hifi-codec
เพิ่มความสนใจแบบแฟลชด้วย NoPE
ยอมรับไพรม์เวฟใน AudioLM เป็นเส้นทางไปยังไฟล์เสียง และสุ่มตัวอย่างอัตโนมัติสำหรับซีแมนติกและอะคูสติก
เพิ่มการแคชคีย์ / ค่าให้กับหม้อแปลงทั้งหมด เพื่อเร่งการอนุมาน
ออกแบบหม้อแปลงไฟฟ้าหยาบและละเอียดแบบลำดับชั้น
ตรวจสอบการถอดรหัสข้อมูลจำเพาะ ทดสอบครั้งแรกใน x-transformers จากนั้นจึงย้ายพอร์ต หากมี
ทำซ้ำการฝังตำแหน่งต่อหน้ากลุ่มใน vq ที่เหลือ
ทดสอบด้วยการสังเคราะห์เสียงพูดสำหรับผู้เริ่มต้น
เครื่องมือ cli บางอย่างเช่น audiolm generate <wav.file | text> และบันทึกไฟล์ wav ที่สร้างขึ้นไปยังไดเร็กทอรีในเครื่อง
ส่งคืนรายการคลื่นในกรณีของเสียงที่มีความยาวผันแปรได้
เพียงดูแลกรณีขอบในการฝึกอบรมข้อความหม้อแปลงหยาบ โดยที่คลื่นดิบจะถูกสุ่มตัวอย่างใหม่ในความถี่ที่ต่างกัน กำหนดเส้นทางโดยอัตโนมัติตามความยาว
@inproceedings { Borsos2022AudioLMAL ,
title = { AudioLM: a Language Modeling Approach to Audio Generation } ,
author = { Zal{'a}n Borsos and Rapha{"e}l Marinier and Damien Vincent and Eugene Kharitonov and Olivier Pietquin and Matthew Sharifi and Olivier Teboul and David Grangier and Marco Tagliasacchi and Neil Zeghidour } ,
year = { 2022 }
} @misc { https://doi.org/10.48550/arxiv.2107.03312 ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco } ,
publisher = { arXiv } ,
url = { https://arxiv.org/abs/2107.03312 } ,
year = { 2021 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @article { Ho2022ClassifierFreeDG ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.12598 }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/rivershavewings }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Liu2022FCMFC ,
title = { FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners } ,
author = { Hao Liu and Xinyang Geng and Lisa Lee and Igor Mordatch and Sergey Levine and Sharan Narang and P. Abbeel } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13432 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Li2021LocalViTBL ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and K. Zhang and Jie Cao and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2104.05707 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @article { Hu2017SqueezeandExcitationN ,
title = { Squeeze-and-Excitation Networks } ,
author = { Jie Hu and Li Shen and Gang Sun } ,
journal = { 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
year = { 2017 } ,
pages = { 7132-7141 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @article { Kazemnejad2023TheIO ,
title = { The Impact of Positional Encoding on Length Generalization in Transformers } ,
author = { Amirhossein Kazemnejad and Inkit Padhi and Karthikeyan Natesan Ramamurthy and Payel Das and Siva Reddy } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.19466 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

