yoloface
1.0.0
YOLOv3 (คุณดูเพียงครั้งเดียว) เป็นอัลกอริธึมการตรวจจับวัตถุแบบเรียลไทม์ที่ล้ำสมัย โมเดลที่เผยแพร่สามารถจดจำวัตถุที่แตกต่างกัน 80 รายการในรูปภาพและวิดีโอ สำหรับรายละเอียดเพิ่มเติม คุณสามารถดูเอกสารนี้ได้
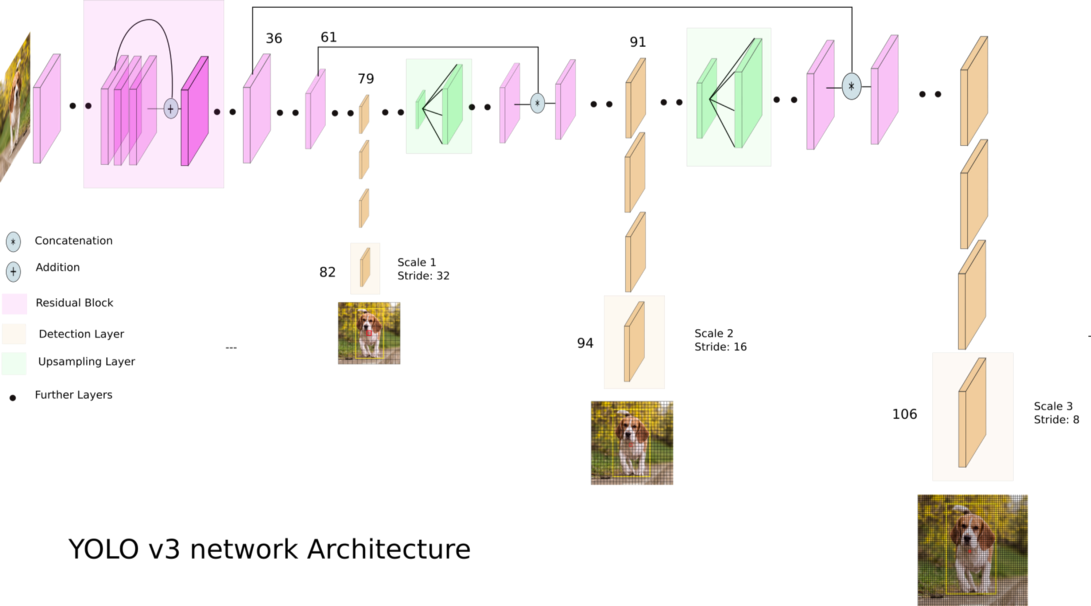
เครดิต: Ayoosh Kathuria
โมดูล OpenCV dnn รองรับการอนุมานรันบนโมเดลการเรียนรู้เชิงลึกที่ได้รับการฝึกอบรมล่วงหน้าจากเฟรมเวิร์กยอดนิยม เช่น TensorFlow, Torch, Darknet และ Caffe
การพัฒนาสำหรับโปรเจ็กต์นี้จะถูกแยกออกจากกันในสภาพแวดล้อมเสมือน Python สิ่งนี้ทำให้เราสามารถทดลองกับการขึ้นต่อกันในเวอร์ชันต่างๆ ได้
มีหลายวิธีในการติดตั้ง virtual environment (virtualenv) ดู Python Virtual Environments: A Primer guide สำหรับแพลตฟอร์มที่แตกต่างกัน แต่นี่คือสองสามวิธี:
$ pip install virtualenv$ pip install --upgrade virtualenvสร้างสภาพแวดล้อมเสมือน Python 3.6 สำหรับโปรเจ็กต์นี้และเปิดใช้งาน virtualenv:
$ virtualenv -p python3.6 yoloface
$ source ./yoloface/bin/activateถัดไป ติดตั้งการขึ้นต่อกันสำหรับโปรเจ็กต์นี้:
$ pip install -r requirements.txt$ git clone https://github.com/sthanhng/yoloface สำหรับการตรวจจับใบหน้า คุณควรดาวน์โหลดไฟล์น้ำหนัก YOLOv3 ที่ได้รับการฝึกล่วงหน้า ซึ่งฝึกฝนในชุดข้อมูล WIDER FACE: A Face Detection Benchmark จากลิงก์นี้ และวางไว้ในไดเร็กทอรี model-weights/
รันคำสั่งต่อไปนี้:
อินพุตรูปภาพ
$ python yoloface.py --image samples/outside_000001.jpg --output-dir outputs/อินพุตวิดีโอ
$ python yoloface.py --video samples/subway.mp4 --output-dir outputs/เว็บแคม
$ python yoloface.py --src 1 --output-dir outputs/
โครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT - ดูไฟล์ LICENSE.md สำหรับรายละเอียดเพิ่มเติม


