lion pytorch
0.2.3
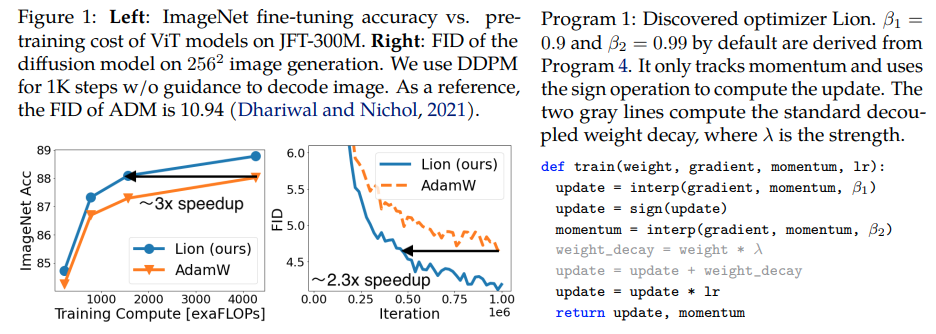
Lion, Evo L ved S i gn M o me n tum เครื่องมือเพิ่มประสิทธิภาพใหม่ที่ค้นพบโดย Google Brain ซึ่งอ้างว่าดีกว่า Adam(w) ใน Pytorch นี่เป็นสำเนาที่เกือบจะคัดลอกมาจากที่นี่ โดยมีการแก้ไขเล็กน้อยเล็กน้อย
มันง่ายมาก เราอาจจะทำให้ทุกคนเข้าถึงและใช้มันโดยเร็วที่สุดเพื่อฝึกโมเดลที่ยอดเยี่ยม ถ้ามันใช้งานได้จริง ?
อัตราการเรียนรู้และน้ำหนักที่ลดลง: ผู้เขียนเขียนในส่วนที่ 5 - Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. ค่าเริ่มต้น ค่าสูงสุด และค่าสิ้นสุดในตารางอัตราการเรียนรู้ควรเปลี่ยน พร้อมกัน ด้วยอัตราส่วนเดียวกันเมื่อเปรียบเทียบกับ AdamW ซึ่งเห็นได้จากนักวิจัย
ตารางอัตราการเรียนรู้: ผู้เขียนใช้ตารางอัตราการเรียนรู้เดียวกันกับ AdamW ในรายงาน อย่างไรก็ตาม พวกเขาสังเกตเห็นกำไรที่มากขึ้นเมื่อใช้ตารางการสลายตัวของโคไซน์เพื่อฝึก ViT เมื่อเปรียบเทียบกับตารางรากที่สองซึ่งกันและกัน
β1 และ β2: ผู้เขียนเขียนในส่วนที่ 5 - The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. เช่นเดียวกับวิธีที่ผู้คนลด β2 เป็น 0.99 หรือเล็กกว่านั้น และเพิ่ม ε เป็น 1e-6 ใน AdamW เพื่อปรับปรุงเสถียรภาพ การใช้ β1=0.95, β2=0.98 ใน Lion ยังมีประโยชน์ในการบรรเทาความไม่มั่นคงในระหว่างการฝึกอบรม ตามที่ผู้เขียนแนะนำ สิ่งนี้ได้รับการยืนยันจากนักวิจัย
อัปเดต: ดูเหมือนว่าจะใช้งานได้กับการสร้างแบบจำลองภาษาอัตโนมัติแบบถดถอย enwik8 ในพื้นที่ของฉัน
อัปเดต 2: การทดลอง ดูเหมือนจะแย่กว่าอดัมมากหากอัตราการเรียนรู้คงที่
อัปเดต 3: หารอัตราการเรียนรู้ด้วย 3 เห็นผลตั้งแต่เนิ่นๆ ดีกว่าอดัม บางทีอดัมอาจถูกปลดจากบัลลังก์ หลังจากผ่านไปเกือบทศวรรษ
อัปเดต 4: การใช้กฎทั่วไปเกี่ยวกับอัตราการเรียนรู้ที่น้อยลง 10 เท่าจากรายงานส่งผลให้การดำเนินการแย่ที่สุด ดังนั้นฉันเดาว่ามันยังต้องใช้เวลาในการปรับแต่งเล็กน้อย
สรุปการอัปเดตก่อนหน้านี้: ดังที่แสดงในการทดลอง Lion ที่มีอัตราการเรียนรู้น้อยกว่า 3 เท่าเอาชนะ Adam ยังคงต้องใช้เวลาในการปรับแต่งเล็กน้อยเนื่องจากอัตราการเรียนรู้ที่น้อยลง 10 เท่านำไปสู่ผลลัพธ์ที่แย่ลง
อัปเดต 5: จนถึงขณะนี้ได้ยินผลลัพธ์เชิงบวกทั้งหมดสำหรับการสร้างแบบจำลองภาษาเมื่อทำถูกต้อง ยังได้ยินผลลัพธ์เชิงบวกสำหรับการฝึกแปลงข้อความเป็นรูปภาพที่สำคัญ แม้ว่าจะต้องใช้เวลาปรับแต่งเล็กน้อยก็ตาม ผลลัพธ์เชิงลบดูเหมือนจะมีปัญหาและสถาปัตยกรรมที่อยู่นอกเหนือสิ่งที่ได้รับการประเมินในรายงาน - RL, เครือข่ายฟีดฟอร์เวิร์ด, สถาปัตยกรรมไฮบริดแปลก ๆ ที่มี LSTM + การโน้มน้าวใจ เป็นต้น ข้อมูลเกร็ดเล็กเกร็ดน้อยเชิงลบยังยืนยันว่าเทคนิคนี้มีความไวต่อขนาดแบตช์ จำนวนข้อมูล / การเพิ่ม . ตกลงว่าตารางอัตราการเรียนรู้ที่เหมาะสมที่สุดคืออะไร และคูลดาวน์ส่งผลต่อผลลัพธ์หรือไม่ สิ่งที่น่าสนใจอีกอย่างคือให้ผลลัพธ์เชิงบวกที่ open-clip ซึ่งกลายเป็นลบเมื่อขนาดของโมเดลถูกขยายขนาด (แต่อาจแก้ไขได้)
อัปเดต 6: ปัญหาการเปิดคลิปได้รับการแก้ไขโดยผู้เขียน โดยการตั้งค่าอุณหภูมิเริ่มต้นให้สูงขึ้น
อัปเดต 7: จะแนะนำเครื่องมือเพิ่มประสิทธิภาพนี้ในการตั้งค่าขนาดแบตช์สูง (64 หรือสูงกว่า) เท่านั้น
$ pip ติดตั้ง lion-pytorch
หรือใช้ conda:
$ conda ติดตั้ง lion-pytorch
# โมเดลของเล่นนำเข้าไฟฉายจากไฟฉายนำเข้า nnmodel = nn.Linear(10, 1)# import Lion และยกตัวอย่างด้วยพารามิเตอร์จาก lion_pytorch import Lionopt = Lion(model.parameters(), lr=1e-4, Weight_decay=1e-2)# ไปข้างหน้าและ Reversesloss = model (torch.randn (10)) loss.backward () # เครื่องมือเพิ่มประสิทธิภาพ stepopt.step () opt.zero_grad ()
หากต้องการใช้เคอร์เนลแบบหลอมละลายเพื่ออัปเดตพารามิเตอร์ ก่อนอื่น pip install triton -U --pre จากนั้น
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # ตั้งค่านี้เป็น True เพื่อใช้เคอร์เนล cuda ด้วย Triton lang (Tillet et al))
Stability.ai สำหรับการสนับสนุนการทำงานและการวิจัยปัญญาประดิษฐ์ที่ทันสมัยแบบโอเพ่นซอร์ส
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {Chen, Xiangning และ Liang, Chen และ Huang, Da และ Real, เอสเตบันและหวัง, ไคหยวนและหลิว, เหยาและฟาม, เฮ่วและตง, ซวนยี่และลือง, ถังและ Hsieh, Cho-Jui และ Lu, Yifeng และ Le, Quoc V.},title = {Symbolic Discovery of Optimization Algorithms},publisher = {arXiv},year = {2023}} @article{Tillet2019TritonAI,title = {Triton: ภาษาระดับกลางและคอมไพเลอร์สำหรับการคำนวณโครงข่ายประสาทเทียมแบบเรียงต่อกัน},ผู้เขียน = {Philippe Tillet และ H. Kung และ D. Cox},journal = {การดำเนินการของ ACM SIGPLAN International Workshop ครั้งที่ 3 บนเครื่อง ภาษาการเรียนรู้และการเขียนโปรแกรม},ปี = {2019}} @misc{Schaipp2024,ผู้เขียน = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {เครื่องมือเพิ่มประสิทธิภาพที่ระมัดระวัง: การปรับปรุงการฝึกอบรมด้วยโค้ดเพียงบรรทัดเดียว},ผู้เขียน = {Kaizhao Liang และ Lizhang Chen และ Bo Liu และ Qiang Liu},ปี = {2024},url = {https://api .semanticscholar.org/CorpusID:274234738}} 

