Extendible Hashing for DBMS
1.0.0
การใช้งานระดับต่ำของการแฮชแบบขยายได้สำหรับระบบฐานข้อมูล
วิธีการนี้ใช้ไดเร็กทอรีและบัคเก็ตเพื่อแฮชข้อมูล และเป็นที่รู้จักอย่างกว้างขวางในเรื่องความยืดหยุ่นและประสิทธิภาพในเวลาในการคำนวณ
ตัวอย่างเช่น คุณมีสารบัญนี้:
| บัตรประจำตัวประชาชน | ชื่อ | นามสกุล | เมือง |
|---|---|---|---|
| 26 | มาเรีย | โคโรนิส | ฮ่องกง |
| 14 | คริสโตโฟรอส | ไกทานิส | โตเกียว |
| 16 | มาเรียนนา | คาร์วูนาริ | ไมอามี่ |
| 12 | ธีโอฟิลอส | นิโคโลปูลอส | ลอนดอน |
| 10 | ไอโอซิฟ | สวิงโกส | โตเกียว |
| 21 | ธีโอฟิลอส | มิชาส | เอเธนส์ |
| 17 | จอร์จอส | กลิ่นปาก | มิวนิค |
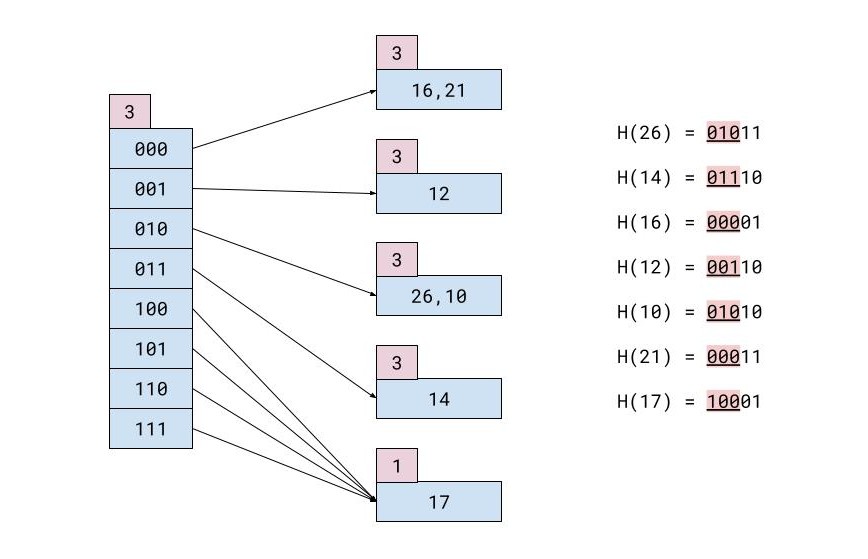
หากแต่ละบล็อกของหน่วยความจำสามารถบันทึกได้เพียง 2 รายการ ไฟล์แฮชหลังจากการแทรกทั้งหมดจะมีลักษณะดังนี้:
โปรแกรมสามารถรันด้วยฟังก์ชันหลักที่แตกต่างกันสองฟังก์ชัน อันแรกนี้จะแทรกบันทึกจำนวนมากในไฟล์ และอันที่สองจะสร้างและแทรกบันทึกลงในไฟล์ที่แตกต่างกันสามไฟล์พร้อมกัน
test_main1:
make main1
./build/runner
ทดสอบ_main2:
make main2
./build/runner