WeClone
1.0.0
การใช้บันทึกการแชท WeChat เพื่อปรับแต่งโมเดลภาษาขนาดใหญ่ ฉันใช้ข้อมูลที่มีประสิทธิภาพบูรณาการประมาณ 20,000 ชิ้น ผลลัพธ์สุดท้ายอาจกล่าวได้ว่าไม่น่าพอใจ แต่บางครั้งก็ตลกจริงๆ
สำคัญ
ปัจจุบัน โปรเจ็กต์ใช้โมเดล chatglm3-6b เป็นค่าเริ่มต้น และใช้วิธี LoRA เพื่อปรับแต่งระยะ sft ซึ่งต้องใช้หน่วยความจำวิดีโอประมาณ 16GB คุณยังสามารถใช้รุ่นและวิธีการอื่นๆ ที่ LLaMA Factory รองรับ ซึ่งใช้หน่วยความจำวิดีโอน้อยกว่า คุณต้องแก้ไขคำแจ้งของระบบเทมเพลตและการกำหนดค่าอื่นๆ ที่เกี่ยวข้องด้วยตนเอง
ข้อกำหนดหน่วยความจำวิดีโอโดยประมาณ:
| วิธีการฝึกอบรม | ความแม่นยำ | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| พารามิเตอร์แบบเต็ม | 16 | 160GB | 320GB | 600GB | 1200GB | 900GB |
| พารามิเตอร์บางอย่าง | 16 | 20GB | 40GB | 120GB | 240GB | 200GB |
| โลรา | 16 | 16GB | 32GB | 80GB | 160GB | 120GB |
| คิวลอรา | 8 | 10GB | 16GB | 40GB | 80GB | 80GB |
| คิวลอรา | 4 | 6GB | 12GB | 24GB | 48GB | 32GB |
| ที่จำเป็น | อย่างน้อย | แนะนำ |
|---|---|---|
| หลาม | 3.8 | 3.10 |
| คบเพลิง | 1.13.1 | 2.2.1 |
| หม้อแปลงไฟฟ้า | 4.37.2 | 4.38.1 |
| ชุดข้อมูล | 2.14.3 | 2.17.1 |
| เร่งความเร็ว | 0.27.2 | 0.27.2 |
| เพฟท์ | 0.9.0 | 0.9.0 |
| trl | 0.7.11 | 0.7.11 |
| ไม่จำเป็น | อย่างน้อย | แนะนำ |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| ความเร็วระดับลึก | 0.10.0 | 0.13.4 |
| บิตแซนด์ไบต์ | 0.39.0 | 0.41.3 |
| แฟลช-ATN | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txtการกำหนดค่าที่เกี่ยวข้องกับการฝึกอบรมและการอนุมานจะรวมอยู่ในไฟล์ settings.json
โปรดใช้ PyWxDump เพื่อแยกบันทึกการแชท WeChat หลังจากดาวน์โหลดซอฟต์แวร์และถอดรหัสฐานข้อมูลแล้ว ให้คลิกการสำรองข้อมูลแชท ประเภทการส่งออกคือ CSV คุณสามารถส่งออกผู้ติดต่อหลายรายการหรือแชทกลุ่มได้ จากนั้นวางโฟลเดอร์ csv ที่ส่งออกซึ่งอยู่ที่ wxdump_tmp/export ในไดเร็กทอรี ./data ซึ่งจะแตกต่างออกไป โฟลเดอร์บันทึกการสนทนาของผู้คนจะถูกรวมเข้าด้วยกันใน ./data/csv csv ข้อมูลตัวอย่างอยู่ใน data/example_chat.csv
ตามค่าเริ่มต้น โครงการจะลบหมายเลขโทรศัพท์มือถือ หมายเลข ID ที่อยู่อีเมล และที่อยู่เว็บไซต์ออกจากข้อมูล นอกจากนี้ยังมีฐานข้อมูลของคำที่ถูกแบน blocked_words ซึ่งคุณสามารถเพิ่มคำและประโยคที่ต้องกรอง (ประโยคทั้งหมดรวมถึงคำที่ถูกแบนจะถูกลบออกตามค่าเริ่มต้น) รันสคริปต์ ./make_dataset/csv_to_json.py เพื่อประมวลผลข้อมูล
เมื่อบุคคลคนเดียวกันตอบหลายประโยคติดต่อกัน มีสามวิธีในการจัดการ:
| เอกสาร | วิธีการประมวลผล |
|---|---|
| csv_to_json.py | เชื่อมต่อด้วยเครื่องหมายจุลภาค |
| csv_to_json-ประโยคเดียว answer.py (ล้าสมัย) | เลือกเฉพาะคำตอบที่ยาวที่สุดเป็นข้อมูลสุดท้าย |
| csv_to_json-ประโยคเดียวหลายรอบ.py | วางไว้ใน 'ประวัติศาสตร์' ของคำพร้อมท์ |
ตัวเลือกแรกคือดาวน์โหลดโมเดล ChatGLM3 จาก Hugging Face หากคุณพบปัญหาในการดาวน์โหลดโมเดล Hugging Face คุณสามารถใช้ชุมชน MoDELSCOPE ผ่านวิธีการต่อไปนี้ สำหรับการฝึกอบรมและการอนุมานในภายหลัง คุณต้องดำเนินการ export USE_MODELSCOPE_HUB=1 ก่อนจึงจะใช้โมเดลของชุมชน MoDELSCOPE
เนื่องจากโมเดลมีขนาดใหญ่ กระบวนการดาวน์โหลดจึงใช้เวลานาน โปรดอดใจรอ
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(ไม่บังคับ) แก้ไข settings.json เพื่อเลือกรุ่นอื่นๆ ที่ดาวน์โหลดในเครื่อง
แก้ไข per_device_train_batch_size และ gradient_accumulation_steps เพื่อปรับการใช้งานหน่วยความจำวิดีโอ
คุณสามารถแก้ไขพารามิเตอร์ เช่น num_train_epochs , lora_rank , lora_dropout ตามปริมาณและคุณภาพของชุดข้อมูลของคุณเอง
เรียกใช้ src/train_sft.py เพื่อปรับแต่งระยะ sft การสูญเสียของฉันลดลงเหลือประมาณ 3.5 เท่านั้น หากลดลงมากเกินไป อาจทำให้เกิดการกระชับมากเกินไป
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.pyบันทึก
คุณยังสามารถปรับแต่งระยะ pt อย่างละเอียดก่อนได้ ดูเหมือนว่าผลการปรับปรุงจะไม่ชัดเจนเช่นกัน
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.pyสำคัญ
มีความเสี่ยงที่บัญชีจะถูกปิดใน WeChat ขอแนะนำให้ใช้บัญชีขนาดเล็กและต้องผูกบัตรธนาคารเพื่อใช้งาน
python ./src/api_service.py # 先启动api服务
python ./src/wechat_bot/main.py ตามค่าเริ่มต้น รหัส QR จะแสดงบนเทอร์มินัล เพียงสแกนรหัสเพื่อเข้าสู่ระบบ สามารถใช้ในการแชทส่วนตัวหรือในการแชทกลุ่ม @bot
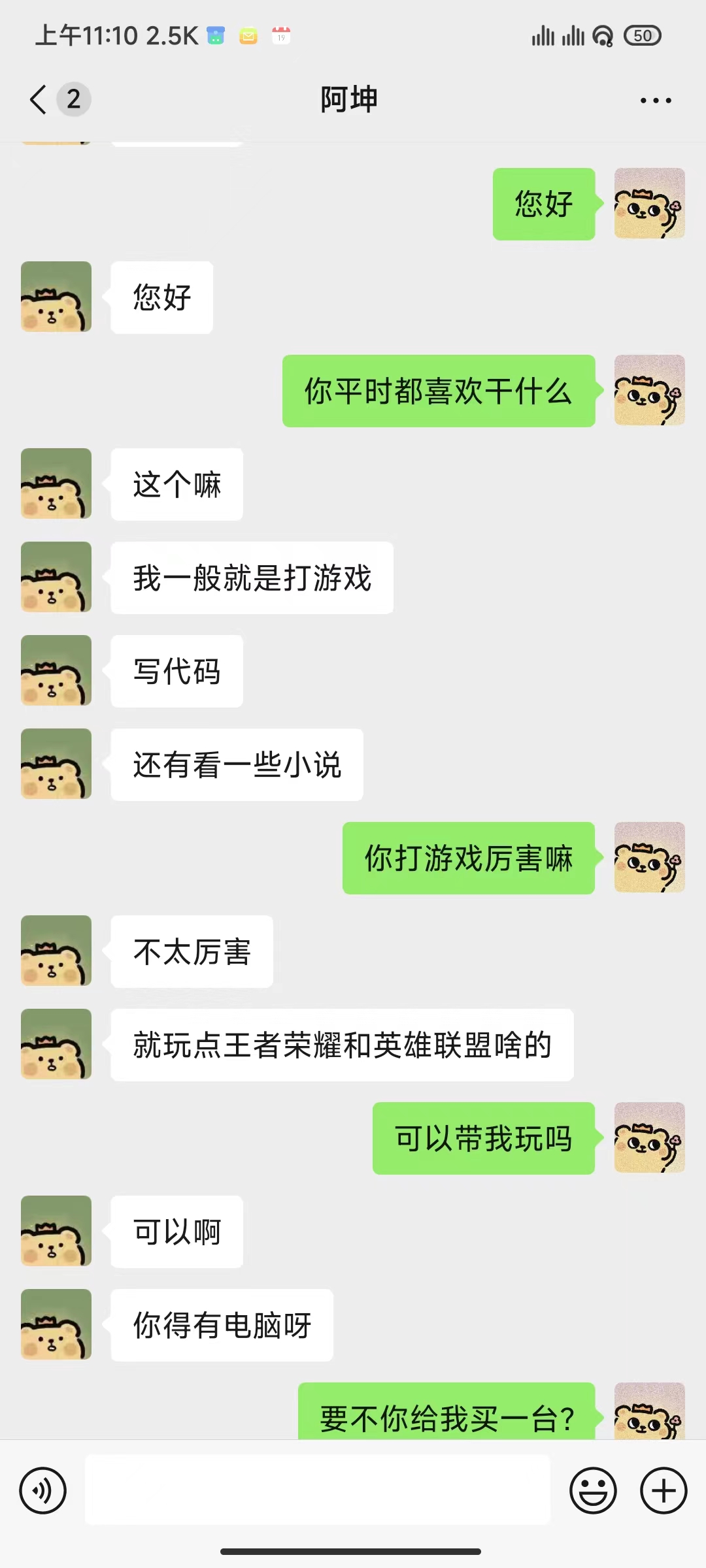

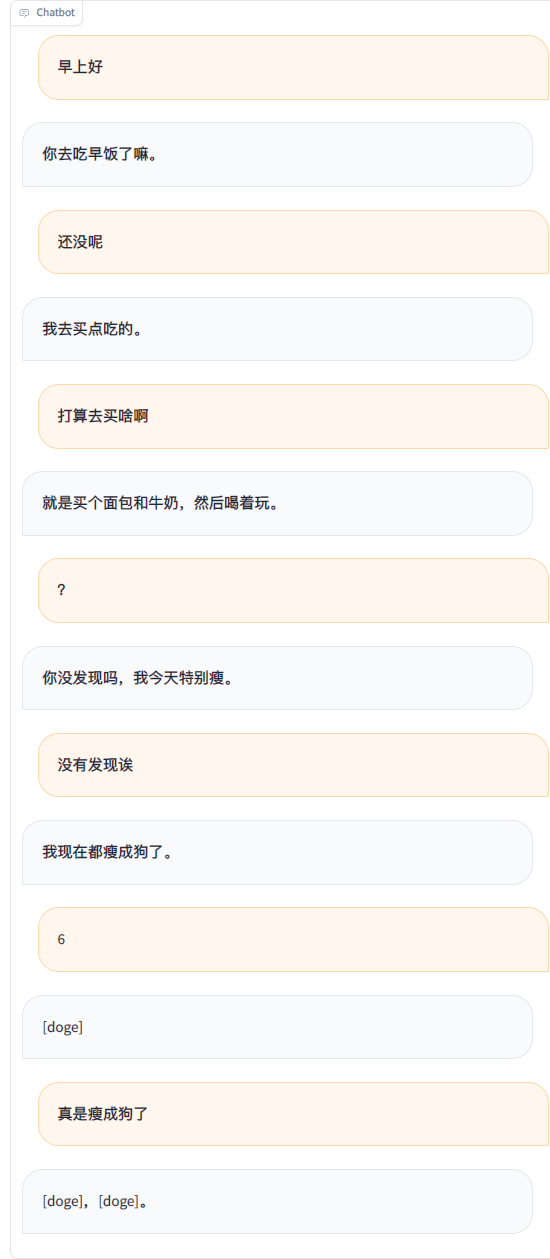
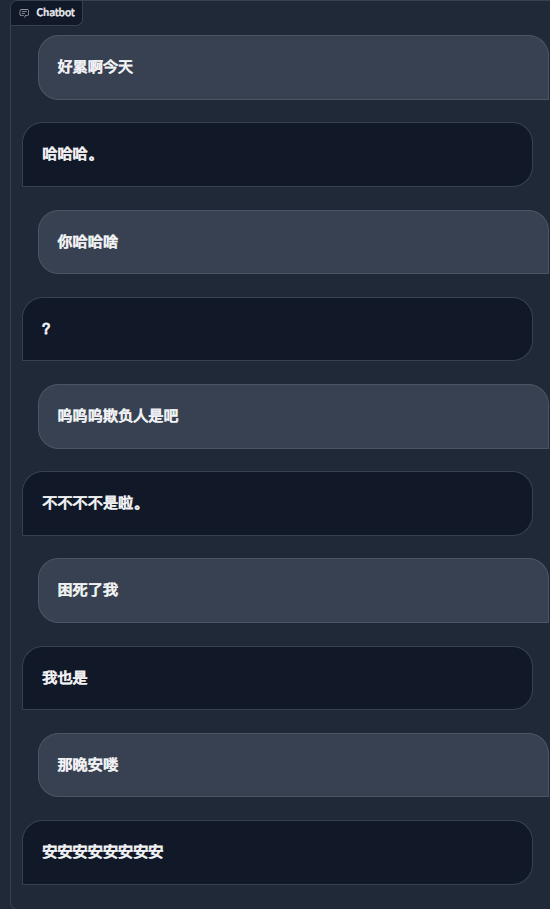
สิ่งที่ต้องทำ
สิ่งที่ต้องทำ


