เป้าหมายของพื้นที่เก็บข้อมูลนี้คือการติดตามเทคนิค GGPLOT2 ที่เรียบร้อยที่ฉันได้เรียนรู้ สิ่งนี้จะถือว่าคุณคุ้นเคยกับพื้นฐานของ GGPLOT2 และสามารถสร้างพล็อตที่ดีของคุณเอง ถ้าไม่โปรดอ่านหนังสือที่ข้อเสนอของคุณ
ฉันไม่ได้ปรับตัวอย่างไม่น่าเชื่อในแผนการเรียงพิมพ์ที่มีชื่อเสียงและธีม finetuning อย่างเชี่ยวชาญและจานสีดังนั้นคุณต้องให้อภัยฉัน ชุดข้อมูล mpg นั้นมีความหลากหลายมากสำหรับการวางแผนดังนั้นคุณจะได้เห็นสิ่งนั้นมากมายเมื่อคุณอ่าน แพ็คเกจส่วนขยายนั้นยอดเยี่ยมมากและฉันก็ขลุกอยู่ แต่ฉันจะพยายาม จำกัด ตัวเองให้เป็นเทคนิควานิลลา Ggplot2 ที่นี่
สำหรับตอนนี้ส่วนใหญ่จะเป็นกระเป๋าที่อ่านได้อย่างเดียว แต่ฉันอาจตัดสินใจในภายหลังว่าจะนำพวกเขาออกเป็นกลุ่มแยกต่างหากในไฟล์อื่น ๆ
โดยการโหลดไลบรารีและตั้งค่าธีมการพล็อต เคล็ดลับแรกที่นี่คือการใช้ theme_set() เพื่อตั้งค่าธีมสำหรับพล็อต ทั้งหมด ของคุณตลอดทั้งเอกสาร หากคุณพบว่าตัวเองตั้งค่าธีม verbose มากสำหรับทุกพล็อตนี่คือสถานที่ที่คุณตั้งค่าการตั้งค่าทั่วไปทั้งหมด จากนั้นอย่าเขียนนวนิยายขององค์ประกอบธีมอีกเลย 1 !
library( ggplot2 )
library( scales )
theme_set(
# Pick a starting theme
theme_gray() +
# Add your favourite elements
theme(
axis.line = element_line(),
panel.background = element_rect( fill = " white " ),
panel.grid.major = element_line( " grey95 " , linewidth = 0.25 ),
legend.key = element_rect( fill = NA )
)
) เอกสาร ?aes ไม่ได้บอกสิ่งนี้ แต่คุณสามารถแยกอาร์กิวเมนต์ mapping ใน GGPLOT2 ได้ นั่นหมายความว่าอย่างไร? หมายความว่าคุณสามารถเขียนอาร์กิวเมนต์ mapping ในระหว่างการเดินทาง !!! - นี่เป็นสิ่งที่ดีโดยเฉพาะอย่างยิ่งหากคุณต้องการรีไซเคิลสุนทรียศาสตร์ทุกครั้ง
my_mapping <- aes( x = foo , y = bar )
aes( colour = qux , !!! my_mapping )
# > Aesthetic mapping:
# > * `x` -> `foo`
# > * `y` -> `bar`
# > * `colour` -> `qux` การใช้งานส่วนตัวที่ฉันชอบคือการทำให้สี fill ตรงกับสี colour แต่เบา กว่า เล็กน้อยเล็กน้อย เราจะใช้ระบบการประเมินที่ล่าช้าสำหรับสิ่งนี้ after_scale() ในกรณีนี้ซึ่งคุณจะเห็นมากขึ้นในส่วนต่อไปนี้ ฉันจะทำซ้ำเคล็ดลับนี้สองสามครั้งในเอกสารนี้
my_fill <- aes( fill = after_scale(alpha( colour , 0.3 )))
ggplot( mpg , aes( displ , hwy )) +
geom_point(aes( colour = factor ( cyl ), !!! my_fill ), shape = 21 )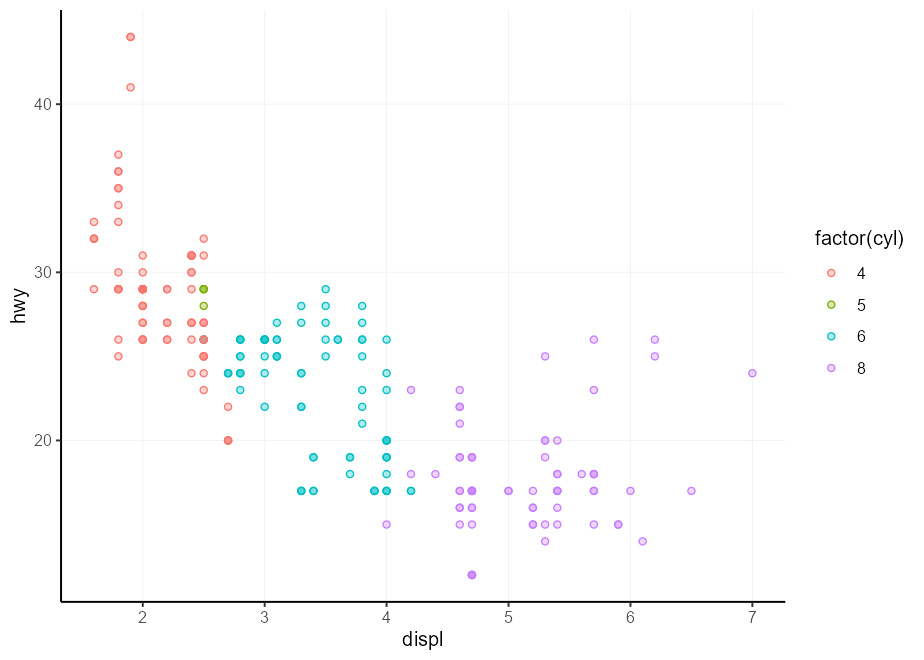
คุณอาจพบว่าตัวเองอยู่ในสถานการณ์ที่คุณถูกขอให้สร้างความร้อนของตัวแปรจำนวนน้อย โดยทั่วไปแล้วเครื่องชั่งต่อเนื่องจะทำงานจากแสงเป็นมืดหรือในทางกลับกันซึ่งทำให้ข้อความเป็นสีเดียวที่อ่านได้ยาก เราสามารถกำหนดวิธีการเขียนข้อความเป็นสีขาวโดยอัตโนมัติบนพื้นหลังสีดำและสีดำบนพื้นหลังแสง ฟังก์ชั่นด้านล่างพิจารณาค่าความเบาสำหรับสีและส่งคืนทั้งสีดำหรือสีขาวขึ้นอยู่กับความสว่างนั้น
contrast <- function ( colour ) {
out <- rep( " black " , length( colour ))
light <- farver :: get_channel( colour , " l " , space = " hcl " )
out [ light < 50 ] <- " white "
out
} ตอนนี้เราสามารถสร้างสุนทรียศาสตร์ที่จะถูกประกบกับ mapping ของเลเยอร์ตามความต้องการ
autocontrast <- aes( colour = after_scale(contrast( fill )))สุดท้ายเราสามารถทดสอบการควบคุมความคมชัดอัตโนมัติของเรา คุณอาจสังเกตเห็นว่ามันปรับให้เข้ากับเครื่องชั่งดังนั้นคุณไม่จำเป็นต้องทำการจัดรูปแบบแบบมีเงื่อนไขสำหรับสิ่งนี้
cors <- cor( mtcars )
# Melt matrix
df <- data.frame (
col = colnames( cors )[as.vector(col( cors ))],
row = rownames( cors )[as.vector(row( cors ))],
value = as.vector( cors )
)
# Basic plot
p <- ggplot( df , aes( row , col , fill = value )) +
geom_raster() +
geom_text(aes( label = round( value , 2 ), !!! autocontrast )) +
coord_equal()
p + scale_fill_viridis_c( direction = 1 )
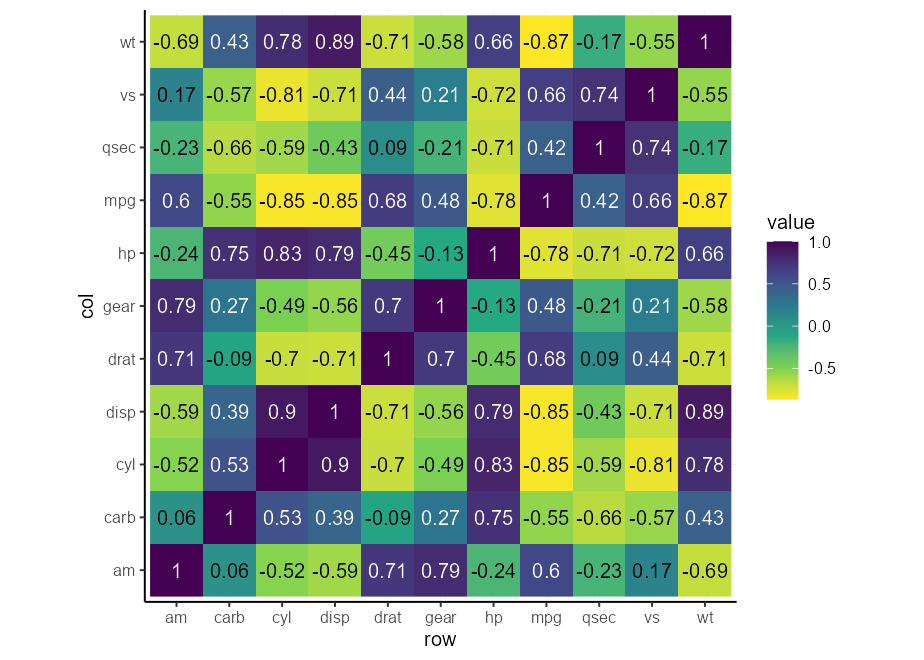
p + scale_fill_viridis_c( direction = - 1 )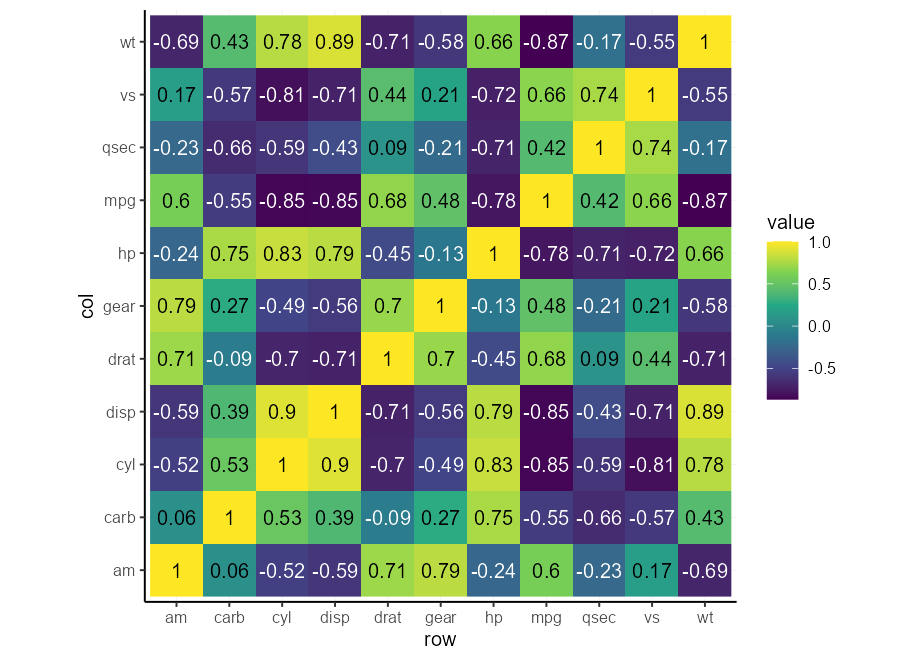
มีส่วนขยายบางอย่างที่เสนอสิ่งต่าง ๆ แบบครึ่ง Geom ในสิ่งที่ฉันรู้จัก Gghalves และแพ็คเกจ See เสนอครึ่งหนึ่ง
นี่คือวิธีการใช้ระบบการประเมินล่าช้าในการใช้งานของคุณเอง สิ่งนี้สามารถมีประโยชน์ได้หากคุณไม่เต็มใจที่จะพึ่งพาการพึ่งพาเป็นพิเศษสำหรับคุณสมบัตินี้
เคสง่ายๆคือ Boxplot คุณสามารถตั้งค่า xmin หรือ xmax เป็น after_scale(x) เพื่อให้ส่วนขวาและซ้ายของ boxplot ตามลำดับ สิ่งนี้ยังใช้งานได้ดีกับ position = "dodge"
# A basic plot to reuse for examples
p <- ggplot( mpg , aes( class , displ , colour = class , !!! my_fill )) +
guides( colour = " none " , fill = " none " ) +
labs( y = " Engine Displacement [L] " , x = " Type of car " )
p + geom_boxplot(aes( xmin = after_scale( x )))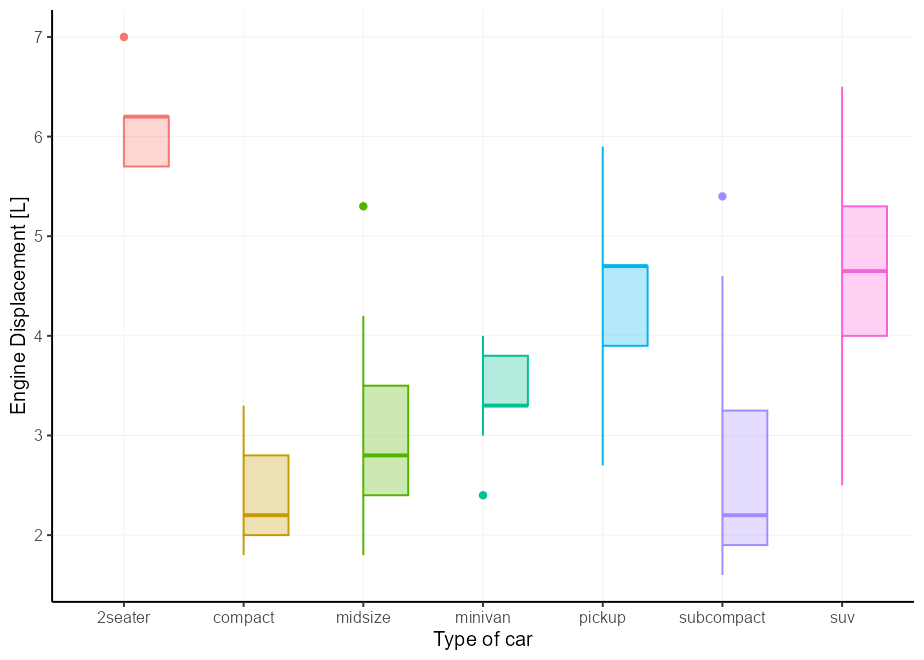
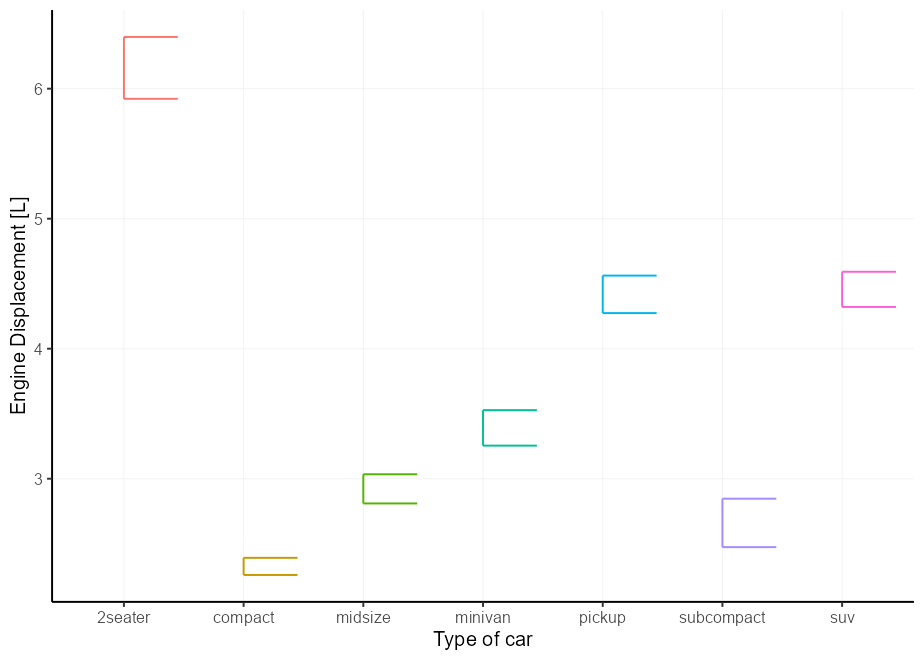
สิ่งเดียวกับที่ใช้ได้กับ Boxplots ก็ใช้ได้กับ Errorbars
p + geom_errorbar(
stat = " summary " ,
fun.data = mean_se ,
aes( xmin = after_scale( x ))
)
เราสามารถทำสิ่งเดียวกันอีกครั้งสำหรับแปลงไวโอลิน แต่เลเยอร์บ่นว่าไม่รู้เกี่ยวกับความงามของ xmin มันใช้ความสวยงาม แต่หลังจากการตั้งค่าข้อมูลดังนั้นจึงไม่ได้มี วัตถุประสงค์ เพื่อเป็นสุนทรียภาพของผู้ใช้ที่สามารถเข้าถึงได้ เราสามารถเงียบคำเตือนได้โดยการอัปเดตค่าเริ่มต้น xmin เป็น NULL ซึ่งหมายความว่ามันจะไม่บ่น แต่ก็ไม่ได้ใช้หากขาดหายไป
update_geom_defaults( " violin " , list ( xmin = NULL ))
p + geom_violin(aes( xmin = after_scale( x )))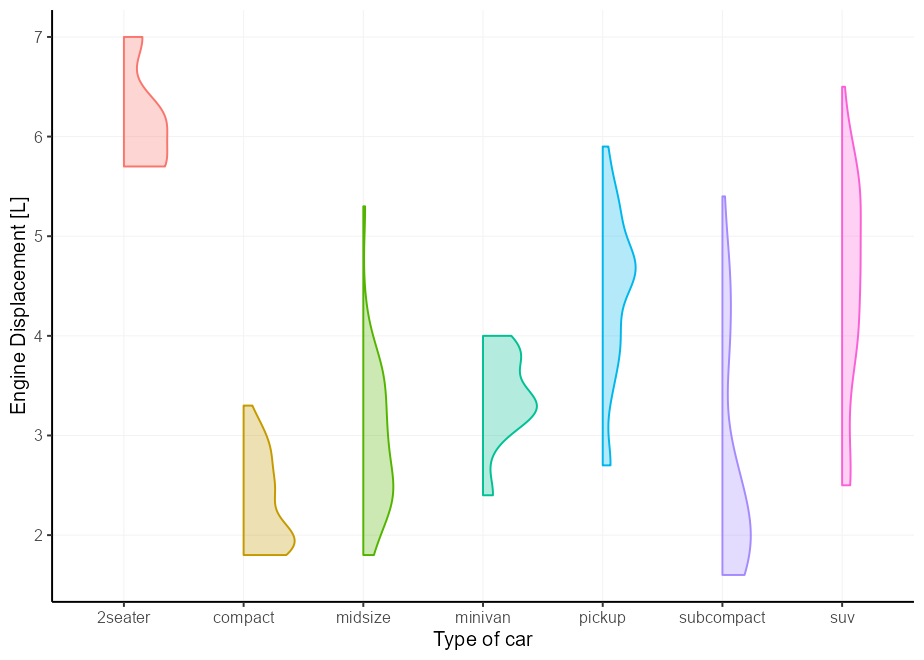
ไม่ทิ้งให้เป็นแบบฝึกหัดสำหรับผู้อ่านในครั้งนี้ แต่ฉันแค่อยากจะแสดงให้เห็นว่ามันจะทำงานอย่างไรถ้าคุณจะรวมสองครึ่งและต้องการให้พวกเขาชดเชยเล็กน้อยจากกัน เราจะละเมิดข้อผิดพลาดเพื่อทำหน้าที่เป็นลวดเย็บกระดาษสำหรับ boxplots
# A small nudge offset
offset <- 0.025
# We can pre-specify the mappings if we plan on recycling some
right_nudge <- aes(
xmin = after_scale( x ),
x = stage( class , after_stat = x + offset )
)
left_nudge <- aes(
xmax = after_scale( x ),
x = stage( class , after_stat = x - offset )
)
# Combining
p +
geom_violin( right_nudge ) +
geom_boxplot( left_nudge ) +
geom_errorbar( left_nudge , stat = " boxplot " , width = 0.3 )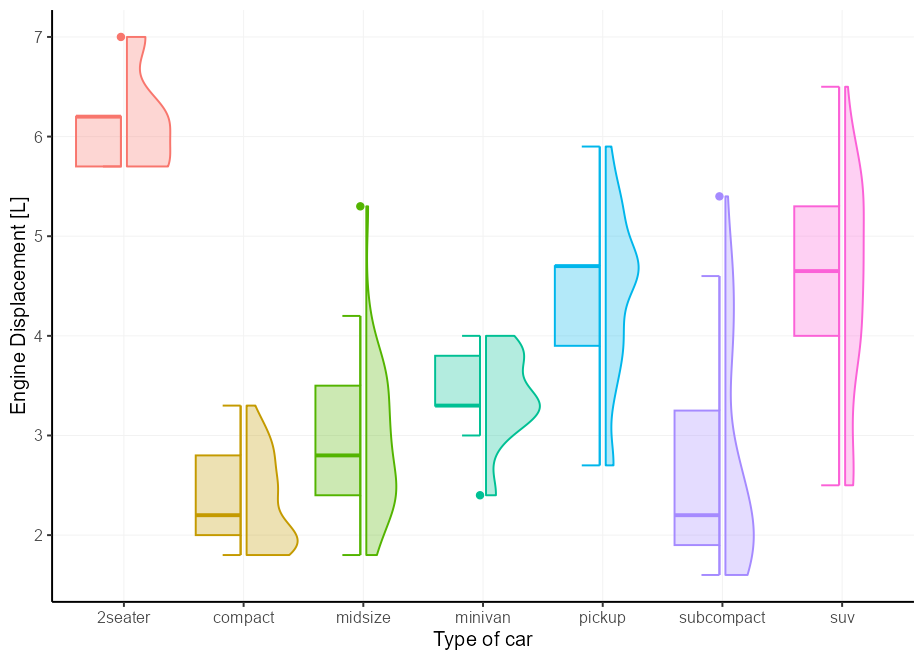
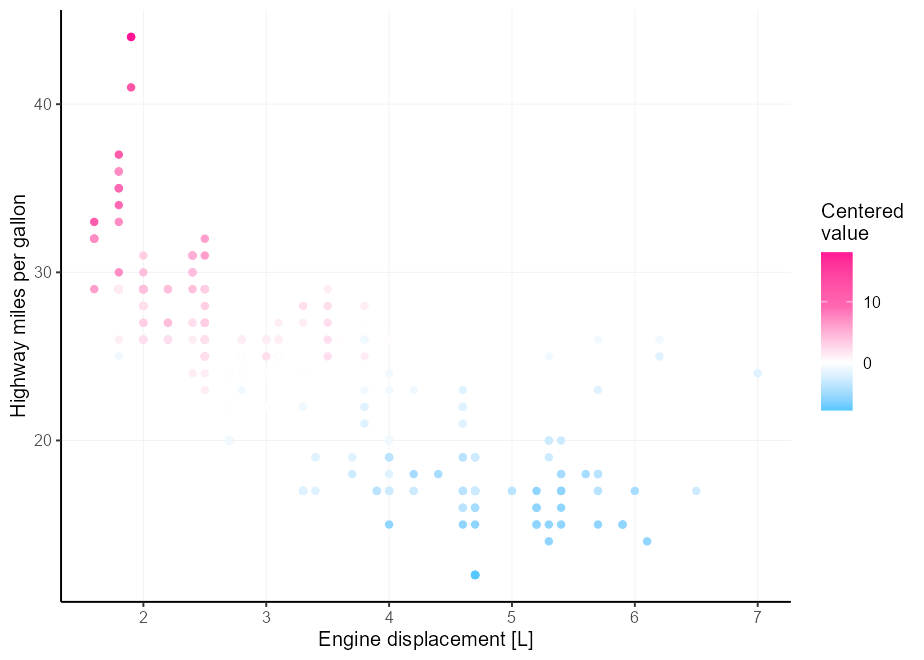
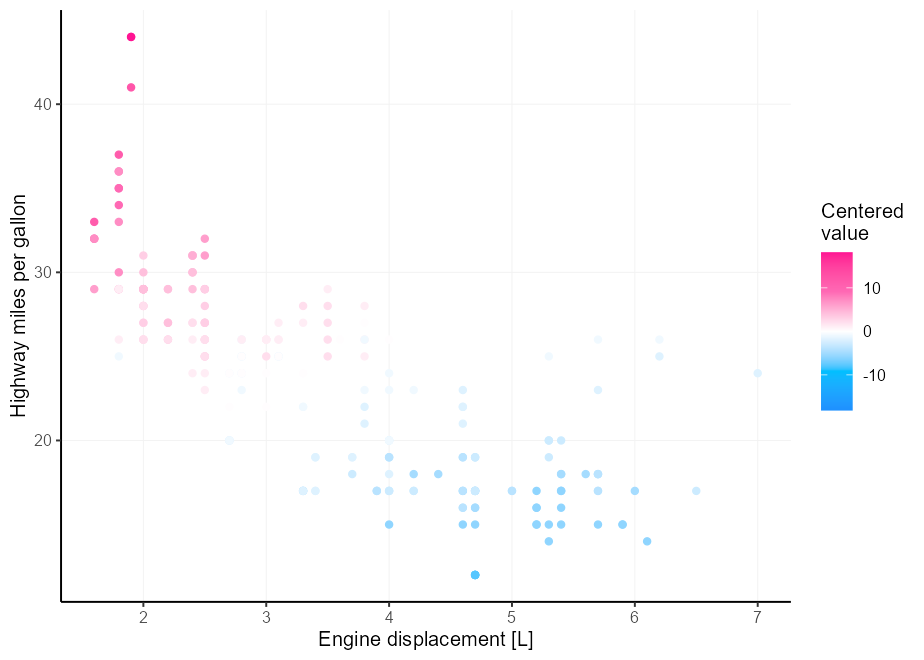
สมมติว่าคุณมีสัญชาตญาณสีที่ดีกว่าที่ฉันมีและสามสีไม่เพียงพอสำหรับความต้องการจานสีที่แตกต่างของคุณ ความเจ็บปวดคือมันเป็นเรื่องยากที่จะได้จุดกึ่งกลางที่ถูกต้องหากขีด จำกัด ของคุณไม่ได้อยู่กึ่งกลางอย่างสมบูรณ์ ป้อนอาร์กิวเมนต์ rescaler ในลีกด้วย scales::rescale_mid()
my_palette <- c( " dodgerblue " , " deepskyblue " , " white " , " hotpink " , " deeppink " )
p <- ggplot( mpg , aes( displ , hwy , colour = cty - mean( cty ))) +
geom_point() +
labs(
x = " Engine displacement [L] " ,
y = " Highway miles per gallon " ,
colour = " Centered n value "
)
p +
scale_colour_gradientn(
colours = my_palette ,
rescaler = ~ rescale_mid( .x , mid = 0 )
)
อีกทางเลือกหนึ่งคือการ จำกัด ขอบเขตของ x เราสามารถทำได้โดยการจัดทำฟังก์ชั่นให้กับขีด จำกัด ของเครื่องชั่ง
p +
scale_colour_gradientn(
colours = my_palette ,
limits = ~ c( - 1 , 1 ) * max(abs( .x ))
)
คุณสามารถติดฉลากจุดด้วย geom_text() แต่ปัญหาที่อาจเกิดขึ้นคือข้อความและคะแนนทับซ้อนกัน
set.seed( 0 )
df <- USArrests [sample(nrow( USArrests ), 5 ), ]
df $ state <- rownames( df )
q <- ggplot( df , aes( Murder , Rape , label = state )) +
geom_point()
q + geom_text()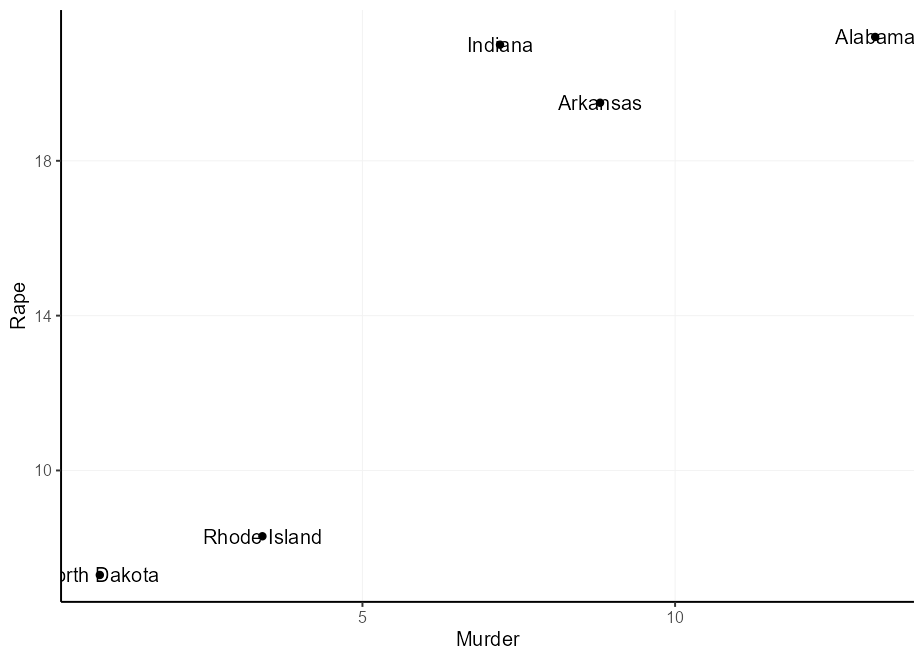
มีวิธีแก้ปัญหาทั่วไปหลายประการสำหรับปัญหานี้และพวกเขาทั้งหมดมาพร้อมกับข้อเสีย:
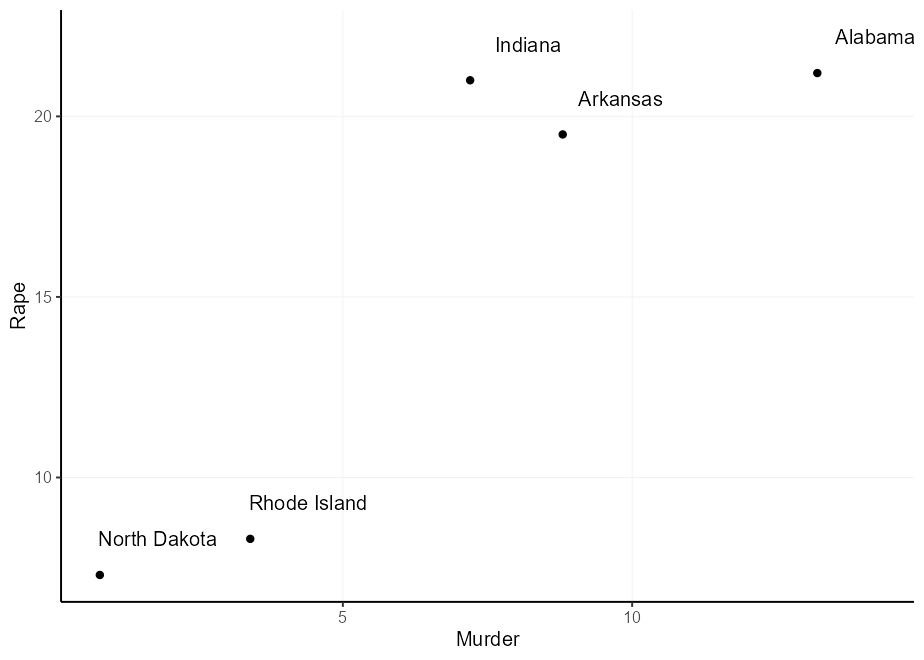
nudge_x และ nudge_y ปัญหาที่นี่คือสิ่งเหล่านี้ถูกกำหนดไว้ในหน่วยข้อมูลดังนั้นการเว้นวรรคจึงไม่สามารถคาดเดาได้และไม่มีวิธีที่จะต้องขึ้นอยู่กับสถานที่ดั้งเดิมhjust และ vjust ช่วยให้คุณต้องพึ่งพาสถานที่ดั้งเดิม แต่สิ่งเหล่านี้ไม่มีการชดเชยตามธรรมชาตินี่คือตัวเลือก 2 และ 3 ในการดำเนินการ:
q + geom_text( nudge_x = 1 , nudge_y = 1 )
q + geom_text(aes(
hjust = Murder > mean( Murder ),
vjust = Rape > mean( Rape )
))
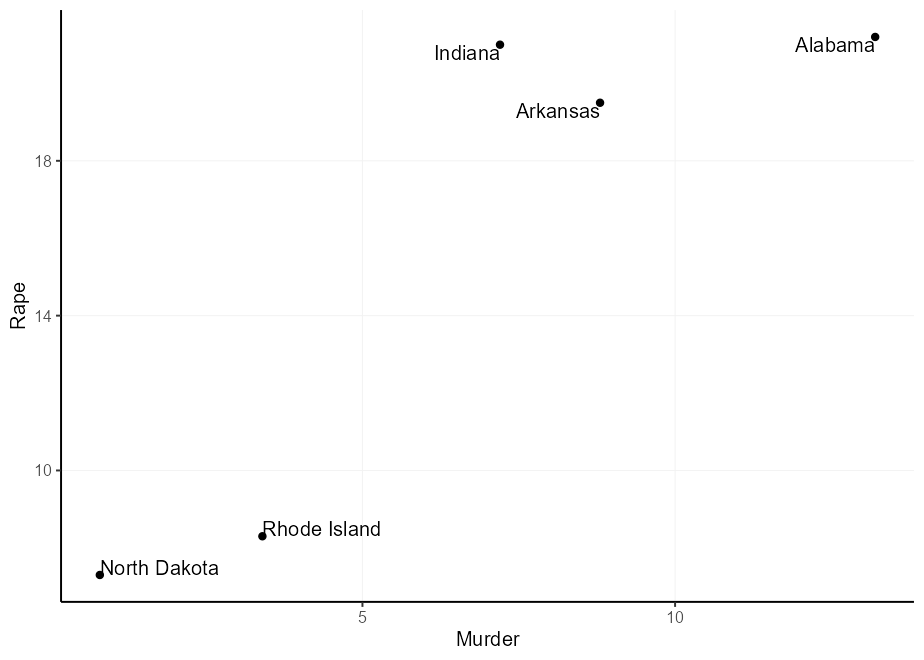
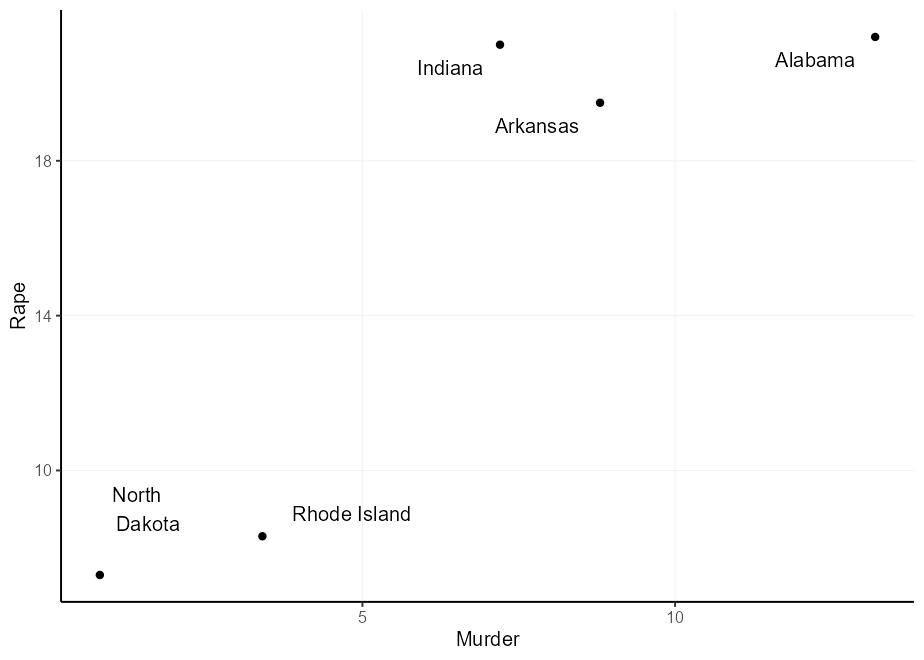
คุณอาจคิดว่า: 'ฉันสามารถทวีคูณเหตุผลเพื่อรับการชดเชยที่กว้างขึ้น' และคุณจะพูดถูก อย่างไรก็ตามเนื่องจากเหตุผลขึ้นอยู่กับขนาดของข้อความคุณอาจได้รับการชดเชยที่ไม่เท่ากัน ข้อสังเกตในพล็อตด้านล่างว่า 'นอร์ทดาโคตา' นั้นชดเชยการเคี้ยวในทิศทาง y และ 'โรดไอส์แลนด์' ในทิศทาง X
q + geom_text(aes(
label = gsub( " North Dakota " , " North n Dakota " , state ),
hjust = (( Murder > mean( Murder )) - 0.5 ) * 1.5 + 0.5 ,
vjust = (( Rape > mean( Rape )) - 0.5 ) * 3 + 0.5
))
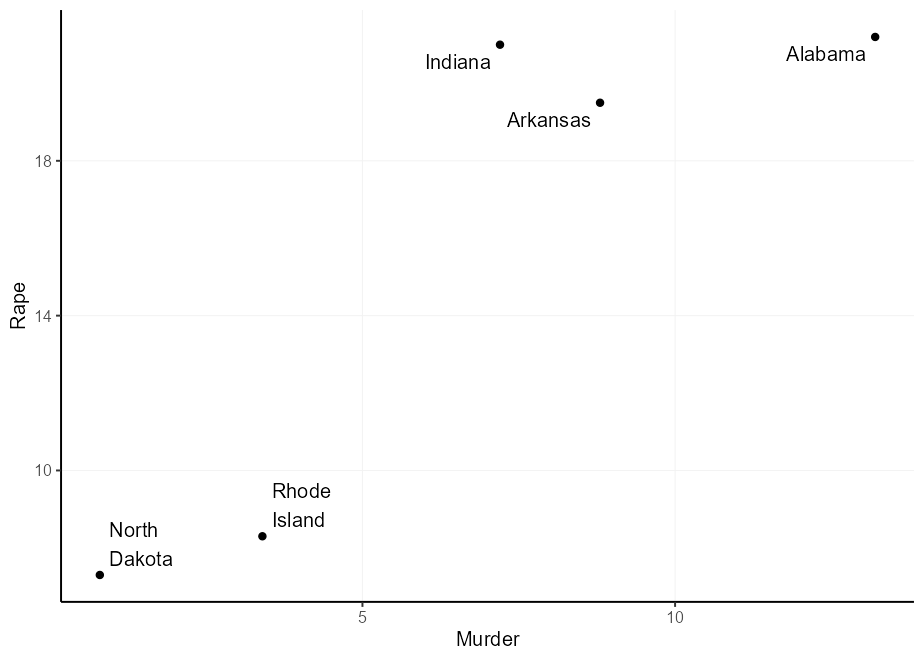
สิ่งที่ดีของ geom_label() คือคุณสามารถปิดกล่องฉลากและเก็บข้อความ ด้วยวิธีนี้คุณสามารถใช้สิ่งที่มีประโยชน์อื่น ๆ ต่อไปเช่นการตั้ง label.padding เพื่อให้การชดเชยแบบสัมบูรณ์ (ไม่อิสระ) จากข้อความไปยังฉลาก
q + geom_label(
aes(
label = gsub( " " , " n " , state ),
hjust = Murder > mean( Murder ),
vjust = Rape > mean( Rape )
),
label.padding = unit( 5 , " pt " ),
label.size = NA , fill = NA
)
สิ่งนี้เคยเป็นเคล็ดลับเกี่ยวกับการวางแท็ก facet ในแผงซึ่งเคยซับซ้อน ด้วย GGPLOT2 3.5.0 คุณไม่จำเป็นต้องเล่นซออีกต่อไปด้วยการตั้งค่าตำแหน่งที่ไม่มีที่สิ้นสุดและปรับเปลี่ยนพารามิเตอร์ hjust หรือ vjust ตอนนี้คุณสามารถใช้ x = I(0.95), y = I(0.95) เพื่อวางข้อความที่มุมบนขวา เปิดรายละเอียดเพื่อดูเคล็ดลับเก่า
การใส่คำอธิบายประกอบข้อความลงบนแปลงแบบ facetted เป็นความเจ็บปวดเนื่องจากขีด จำกัด อาจแตกต่างกันไปตามแผงต่อแผงดังนั้นจึงเป็นเรื่องยากมากที่จะหาตำแหน่งที่ถูกต้อง ส่วนขยายที่สำรวจการบรรเทาความเจ็บปวดนี้คือส่วนขยายของ Tagger แต่เราสามารถทำสิ่งที่คล้ายกันในวานิลลา Ggplot2
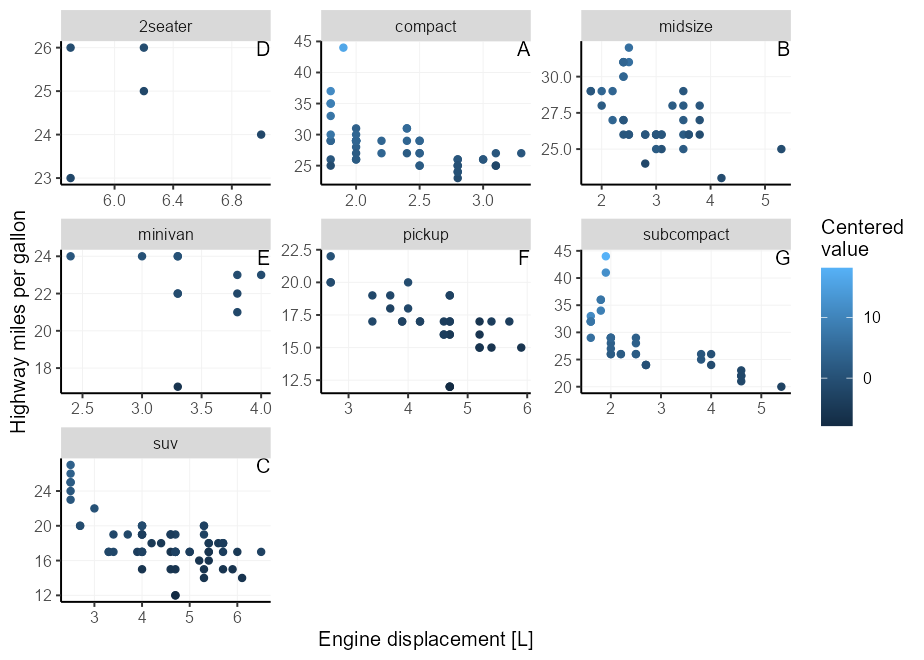
โชคดีที่มีช่างในแกนตำแหน่งของ GGPLOT2 ที่ Let's Let's -Inf และ Inf ถูกตีความว่าเป็นขีด จำกัด ขั้นต่ำและสูงสุดของสเกลตามลำดับ 3 คุณสามารถใช้ประโยชน์จากสิ่งนี้ได้โดยเลือก x = Inf, y = Inf เพื่อวางฉลากไว้ในมุมหนึ่ง นอกจากนี้คุณยังสามารถใช้ -Inf แทนที่จะเป็น Inf เพื่อวางที่ด้านล่างแทนที่จะเป็นด้านบนหรือซ้ายแทนขวา
เราจำเป็นต้องจับคู่อาร์กิวเมนต์ hjust / vjust กับด้านข้างของพล็อต สำหรับ x/y = Inf พวกเขาจะต้องเป็น hjust/vjust = 1 และสำหรับ x/y = -Inf พวกเขาต้องเป็น hjust/vjust = 0
p + facet_wrap( ~ class , scales = " free " ) +
geom_text(
# We only need 1 row per facet, so we deduplicate the facetting variable
data = ~ subset( .x , ! duplicated( class )),
aes( x = Inf , y = Inf , label = LETTERS [seq_along( class )]),
hjust = 1 , vjust = 1 ,
colour = " black "
)
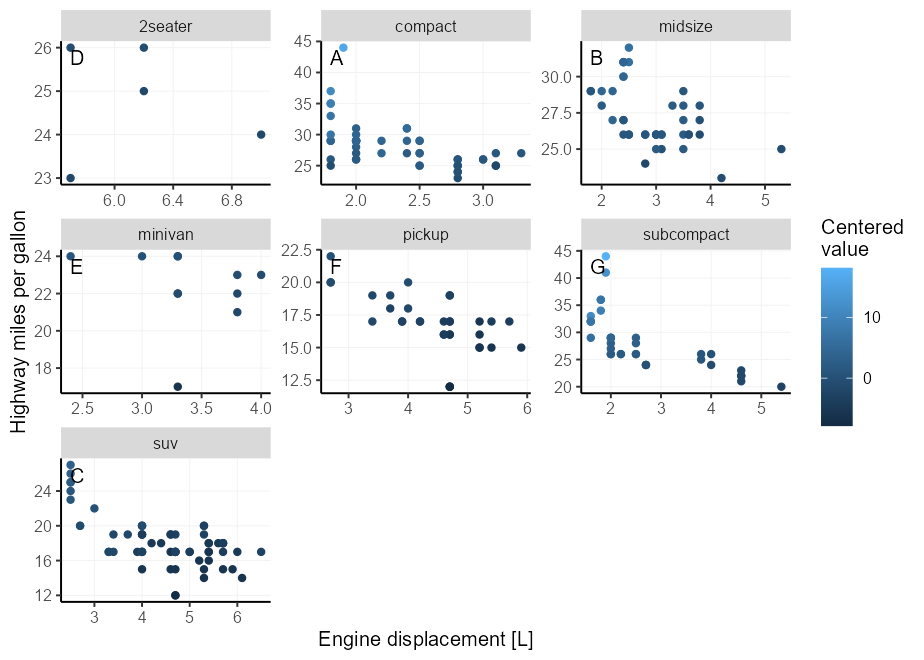
น่าเสียดายที่สิ่งนี้ทำให้ข้อความตรงไปที่ชายแดนของแผงซึ่งอาจทำให้เรารู้สึกถึงความงาม เราสามารถรับนักเล่นได้เล็กน้อยโดยใช้ geom_label() ซึ่งช่วยให้เราควบคุมระยะห่างระหว่างข้อความและเส้นขอบพาเนลได้อย่างแม่นยำยิ่งขึ้นโดยการตั้งค่าป้าย label.padding
ยิ่งกว่านั้นเราสามารถใช้ label.size = NA, fill = NA เพื่อซ่อนส่วนกล่องข้อความของ geom เพื่อวัตถุประสงค์ในการแสดงตอนนี้เราวางแท็กที่ซ้ายบนแทนที่จะเป็นด้านบนขวา
p + facet_wrap( ~ class , scales = " free " ) +
geom_label(
data = ~ subset( .x , ! duplicated( class )),
aes( x = - Inf , y = Inf , label = LETTERS [seq_along( class )]),
hjust = 0 , vjust = 1 , label.size = NA , fill = NA ,
label.padding = unit( 5 , " pt " ),
colour = " black "
)
สมมติว่าเราได้รับมอบหมายให้สร้างพล็อตที่คล้ายกันพร้อมชุดข้อมูลและคอลัมน์ที่แตกต่างกัน ตัวอย่างเช่นเราอาจต้องการสร้างชุดของ Barplots 4 ด้วยชุดล่วงหน้าบางอย่าง: เราต้องการให้แท่งสัมผัสกับแกน x และไม่วาดกริดแนวตั้ง
วิธีหนึ่งที่รู้จักกันดีในการสร้างพล็อตที่คล้ายกันคือการตัดการก่อสร้างพล็อตลงในฟังก์ชั่น ด้วยวิธีนี้คุณสามารถใช้เข้ารหัสที่ตั้งไว้ล่วงหน้าทั้งหมดที่คุณต้องการในฟังก์ชั่นของคุณ
ฉันกรณีที่คุณอาจไม่ทราบว่ามีวิธีการต่าง ๆ ในการเขียนโปรแกรมด้วยฟังก์ชั่น aes() และการใช้ {{ }} (หยิกเคาะ) เป็นหนึ่งในวิธีที่ยืดหยุ่นมากขึ้น 5
barplot_fun <- function ( data , x ) {
ggplot( data , aes( x = {{ x }})) +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.05 , 0 )) +
theme( panel.grid.major.x = element_blank())
}
barplot_fun( mpg , class )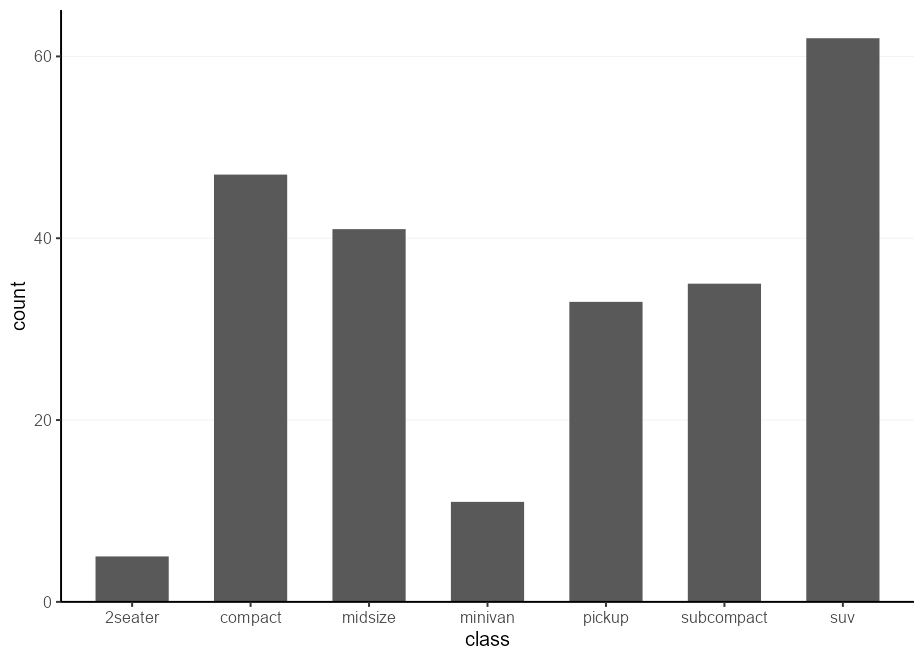
ข้อเสียเปรียบอย่างหนึ่งของวิธีการนี้คือคุณล็อคความสวยงามใด ๆ ในข้อโต้แย้งฟังก์ชั่น หากต้องการไปรอบ ๆ สิ่งนี้วิธีที่ง่ายกว่าคือการผ่าน ... โดยตรงไปยัง aes()
barplot_fun <- function ( data , ... ) {
ggplot( data , aes( ... )) +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )) +
theme( panel.grid.major.x = element_blank())
}
barplot_fun( mpg , class , colour = factor ( cyl ), !!! my_fill )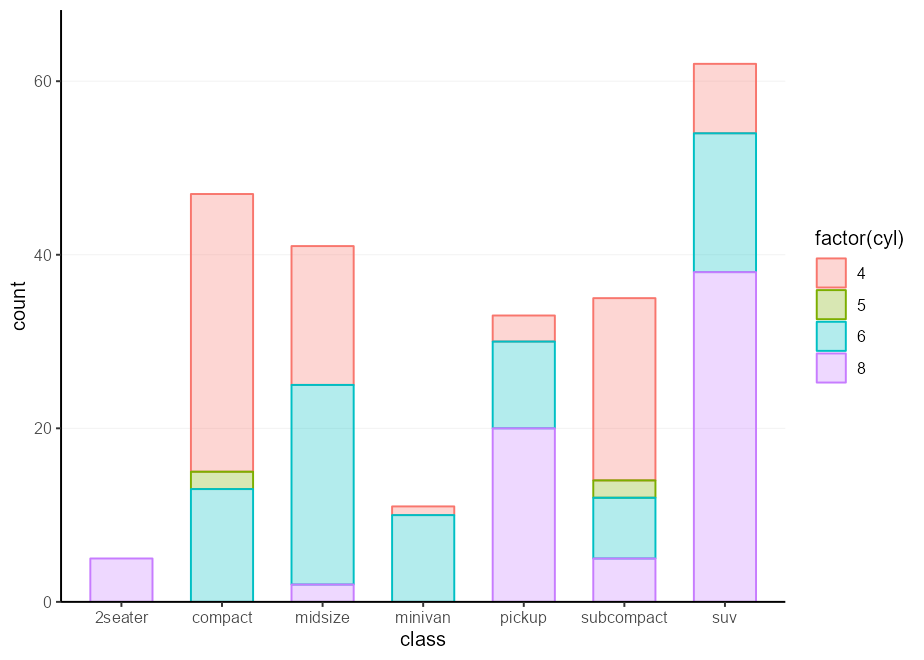
อีกวิธีหนึ่งในการทำสิ่งที่คล้ายกันมากคือการใช้ 'โครงกระดูก' พล็อต แนวคิดที่อยู่เบื้องหลังโครงกระดูกคือคุณสามารถสร้างพล็อตโดยมีหรือไม่มีอาร์กิวเมนต์ data ใด ๆ และเพิ่มเฉพาะในภายหลัง จากนั้นเมื่อคุณต้องการพล็อตจริงคุณสามารถใช้ %+% เพื่อเติมหรือแทนที่ชุดข้อมูลและ + aes(...) เพื่อตั้งค่าความสวยงามที่เกี่ยวข้อง
barplot_skelly <- ggplot() +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )) +
theme( panel.grid.major.x = element_blank())
my_plot <- barplot_skelly % + % mpg +
aes( class , colour = factor ( cyl ), !!! my_fill )
my_plot 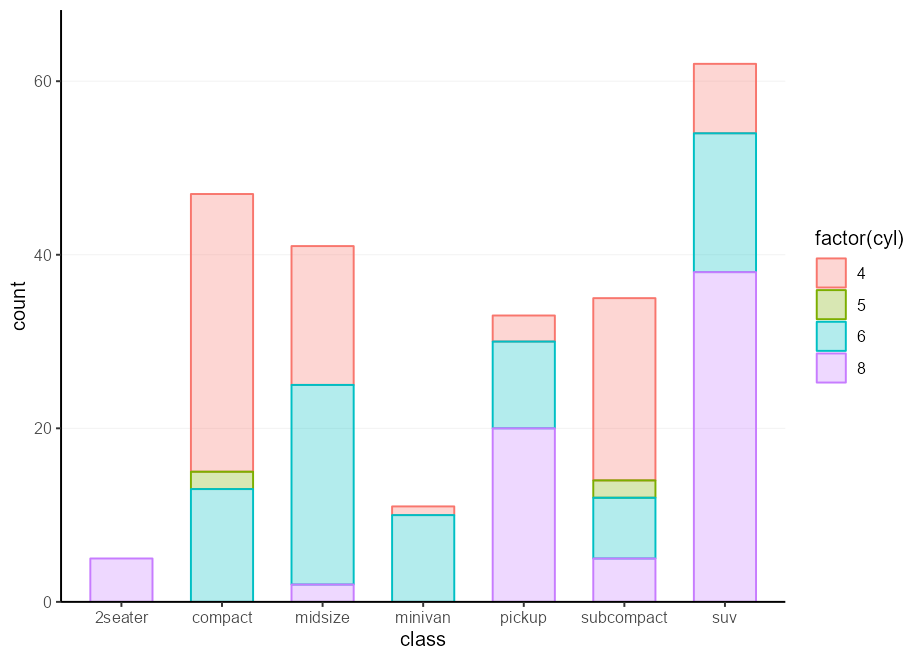
สิ่งหนึ่งที่เรียบร้อยเกี่ยวกับโครงกระดูกเหล่านี้คือแม้ว่าคุณจะกรอก data และ mapping อาร์กิวเมนต์แล้วคุณก็สามารถแทนที่พวกเขาได้อีกครั้งและอีกครั้ง
my_plot % + % mtcars +
aes( factor ( carb ), colour = factor ( cyl ), !!! my_fill )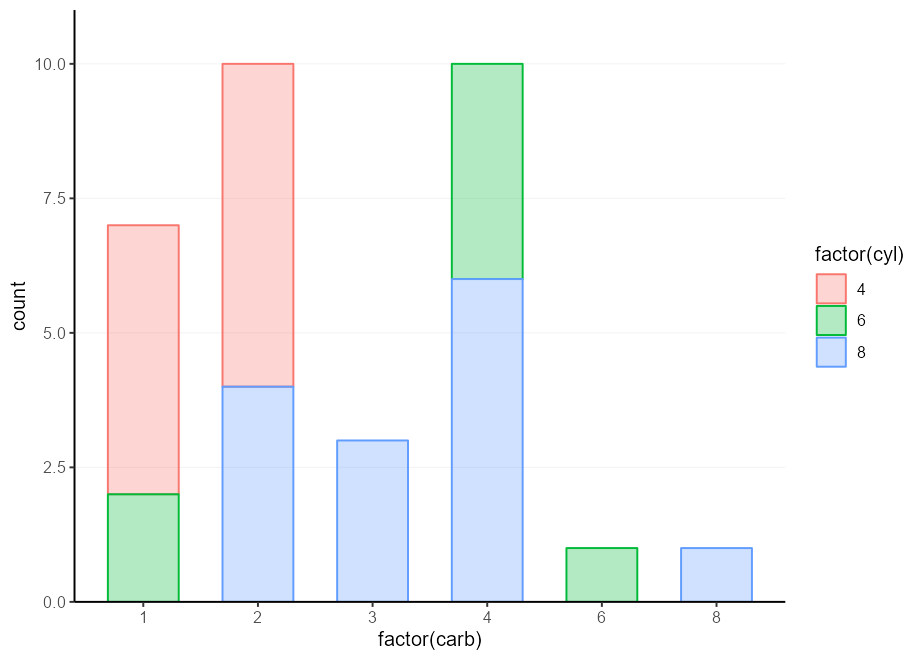
ความคิดที่นี่คือการไม่ทำโครงกระดูกทั้งหมด แต่เป็นเพียงชุดของชิ้นส่วนที่ใช้ซ้ำบ่อยครั้ง ตัวอย่างเช่นเราอาจต้องการติดฉลาก barplot ของเราและบรรจุทุกสิ่งที่ประกอบขึ้นเป็น barplot ที่มีป้ายกำกับ เคล็ดลับในการนี้คือการ ไม่ เพิ่มส่วนประกอบเหล่านี้เข้าด้วยกันด้วย + แต่เพียงใส่ไว้ใน list() จากนั้นคุณสามารถ + รายการของคุณพร้อมกับการโทรพล็อตหลัก
labelled_bars <- list (
geom_bar( my_fill , width = 0.618 ),
geom_text(
stat = " count " ,
aes( y = after_stat( count ),
label = after_stat( count ),
fill = NULL , colour = NULL ),
vjust = - 1 , show.legend = FALSE
),
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )),
theme( panel.grid.major.x = element_blank())
)
ggplot( mpg , aes( class , colour = factor ( cyl ))) +
labelled_bars +
ggtitle( " The `mpg` dataset " )
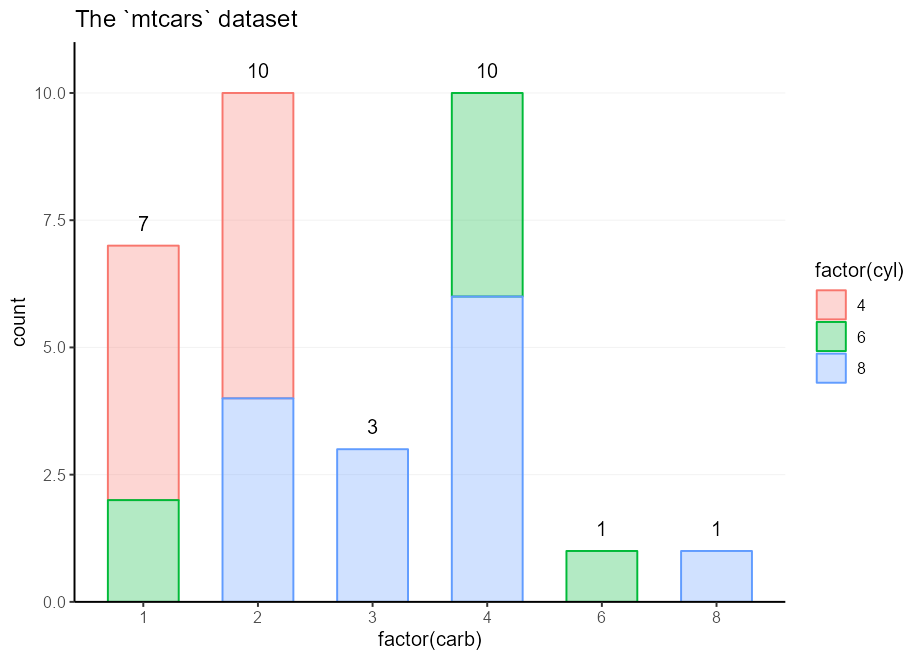
ggplot( mtcars , aes( factor ( carb ), colour = factor ( cyl ))) +
labelled_bars +
ggtitle( " The `mtcars` dataset " )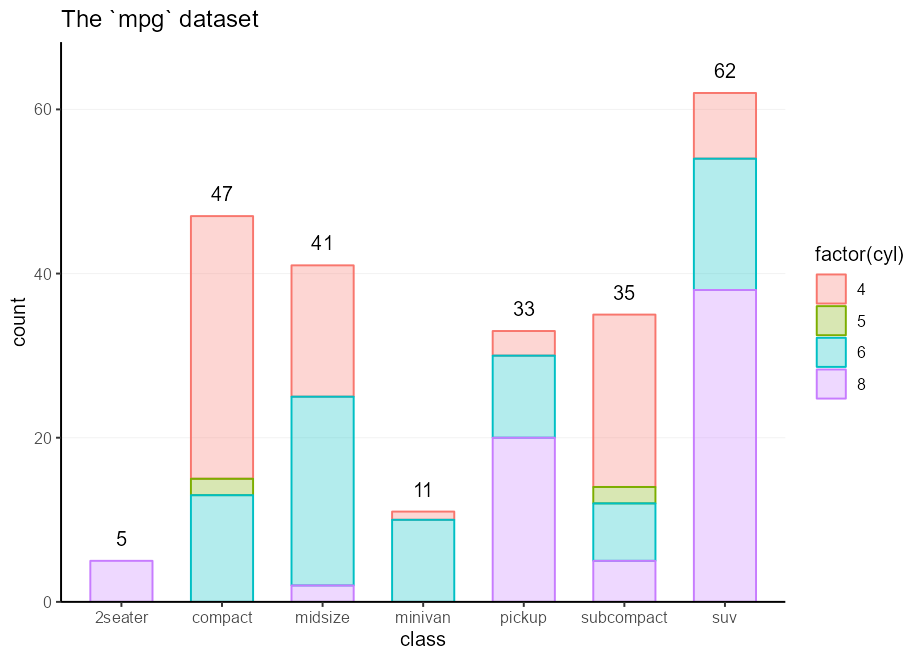
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.3.2 (2023-10-31 ucrt)
#> os Windows 11 x64 (build 22631)
#> system x86_64, mingw32
#> ui RTerm
#> language (EN)
#> collate English_Netherlands.utf8
#> ctype English_Netherlands.utf8
#> tz Europe/Amsterdam
#> date 2024-02-27
#> pandoc 3.1.1
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> cli 3.6.2 2023-12-11 [] CRAN (R 4.3.2)
#> colorspace 2.1-0 2023-01-23 [] CRAN (R 4.3.2)
#> digest 0.6.34 2024-01-11 [] CRAN (R 4.3.2)
#> dplyr 1.1.4 2023-11-17 [] CRAN (R 4.3.2)
#> evaluate 0.23 2023-11-01 [] CRAN (R 4.3.2)
#> fansi 1.0.6 2023-12-08 [] CRAN (R 4.3.2)
#> farver 2.1.1 2022-07-06 [] CRAN (R 4.3.2)
#> fastmap 1.1.1 2023-02-24 [] CRAN (R 4.3.2)
#> generics 0.1.3 2022-07-05 [] CRAN (R 4.3.2)
#> ggplot2 * 3.5.0.9000 2024-02-27 [] local
#> glue 1.7.0 2024-01-09 [] CRAN (R 4.3.2)
#> gtable 0.3.4 2023-08-21 [] CRAN (R 4.3.2)
#> highr 0.10 2022-12-22 [] CRAN (R 4.3.2)
#> htmltools 0.5.7 2023-11-03 [] CRAN (R 4.3.2)
#> knitr 1.45 2023-10-30 [] CRAN (R 4.3.2)
#> labeling 0.4.3 2023-08-29 [] CRAN (R 4.3.1)
#> lifecycle 1.0.4 2023-11-07 [] CRAN (R 4.3.2)
#> magrittr 2.0.3 2022-03-30 [] CRAN (R 4.3.2)
#> munsell 0.5.0 2018-06-12 [] CRAN (R 4.3.2)
#> pillar 1.9.0 2023-03-22 [] CRAN (R 4.3.2)
#> pkgconfig 2.0.3 2019-09-22 [] CRAN (R 4.3.2)
#> R6 2.5.1 2021-08-19 [] CRAN (R 4.3.2)
#> ragg 1.2.7 2023-12-11 [] CRAN (R 4.3.2)
#> rlang 1.1.3 2024-01-10 [] CRAN (R 4.3.2)
#> rmarkdown 2.25 2023-09-18 [] CRAN (R 4.3.2)
#> rstudioapi 0.15.0 2023-07-07 [] CRAN (R 4.3.2)
#> scales * 1.3.0 2023-11-28 [] CRAN (R 4.3.2)
#> sessioninfo 1.2.2 2021-12-06 [] CRAN (R 4.3.2)
#> systemfonts 1.0.5 2023-10-09 [] CRAN (R 4.3.2)
#> textshaping 0.3.7 2023-10-09 [] CRAN (R 4.3.2)
#> tibble 3.2.1 2023-03-20 [] CRAN (R 4.3.2)
#> tidyselect 1.2.0 2022-10-10 [] CRAN (R 4.3.2)
#> utf8 1.2.4 2023-10-22 [] CRAN (R 4.3.2)
#> vctrs 0.6.5 2023-12-01 [] CRAN (R 4.3.2)
#> viridisLite 0.4.2 2023-05-02 [] CRAN (R 4.3.2)
#> withr 3.0.0 2024-01-16 [] CRAN (R 4.3.2)
#> xfun 0.41 2023-11-01 [] CRAN (R 4.3.2)
#> yaml 2.3.8 2023-12-11 [] CRAN (R 4.3.2)
#>
#>
#> ──────────────────────────────────────────────────────────────────────────────
คุณต้องทำครั้งเดียวเมื่อเริ่มต้นเอกสารของคุณ แต่แล้วไม่อีกแล้ว! ยกเว้นในเอกสารถัดไปของคุณ เพียงเขียนสคริปต์ plot_defaults.R และ source() ที่มาจากเอกสารของคุณ คัดลอกวางสคริปต์นั้นสำหรับทุกโครงการ จากนั้นอย่างแท้จริง ไม่เคย อีกครั้ง: หัวใจ:
นี่เป็นเรื่องโกหก ในความเป็นจริงฉันใช้ aes(colour = after_scale(colorspace::darken(fill, 0.3))) แทนที่จะทำให้การเติมเต็ม ฉันไม่ต้องการให้ readme นี้มีการพึ่งพา {colorspace}
เว้นแต่ว่าคุณจะก่อวินาศกรรมด้วยตนเองโดยการตั้งค่า oob = scales::oob_censor_any ในระดับเช่น
ในจิตวิญญาณของคุณคุณ ต้องการ ทำ barplots มากมายหรือไม่?
var .data[[var]] .data$var การใช้คำ .data
บิตนี้เดิมเรียกว่า 'Sytial Skeleton' แต่ในฐานะที่เป็นซี่โครงเป็นส่วนหนึ่งของโครงกระดูกชื่อนี้ฟังดูน่าตื่นเต้นมากขึ้น


