whisper.cpp
v1.7.2
เสถียร: v1.7.2 / Roadmap | คำถามที่พบบ่อย
การอนุมานประสิทธิภาพสูงของโมเดลการรู้จำเสียงพูดอัตโนมัติของ OpenAI (ASR):
แพลตฟอร์มที่รองรับ:
การใช้งานระดับสูงทั้งหมดของแบบจำลองนั้นมีอยู่ใน Whisper.h และ Whisper.cpp ส่วนที่เหลือของรหัสเป็นส่วนหนึ่งของไลบรารีการเรียนรู้ของเครื่อง ggml
การมีการใช้งานแบบจำลองที่มีน้ำหนักเบาช่วยให้สามารถรวมเข้ากับแพลตฟอร์มและแอปพลิเคชันที่แตกต่างกันได้อย่างง่ายดาย ตัวอย่างนี่คือวิดีโอของการเรียกใช้โมเดลบนอุปกรณ์ iPhone 13 - ออฟไลน์อย่างสมบูรณ์, on- อุปกรณ์: Whisper.objc
นอกจากนี้คุณยังสามารถสร้างแอปพลิเคชันผู้ช่วยออฟไลน์ของคุณเองได้อย่างง่ายดาย: คำสั่ง
บน Apple Silicon การอนุมานจะทำงานอย่างเต็มที่บน GPU ผ่านทางโลหะ:
หรือคุณสามารถเรียกใช้ตรงในเบราว์เซอร์: talk.wasm
ตัวดำเนินการเทนเซอร์ได้รับการปรับให้เหมาะสมอย่างมากสำหรับซีพียูแอปเปิ้ลซิลิคอน ขึ้นอยู่กับขนาดการคำนวณแขนงนีออน SIMD Intrinsics หรือ CBLAs เร่งการทำงานตามกรอบการทำงานของเฟรมเวิร์ก หลังมีประสิทธิภาพโดยเฉพาะอย่างยิ่งสำหรับขนาดที่ใหญ่กว่าเนื่องจากเฟรมเวิร์กเร่งความเร็วใช้ตัวประมวลผลร่วม AMX แบบพิเศษที่มีอยู่ในผลิตภัณฑ์แอปเปิ้ลที่ทันสมัย
โคลนครั้งแรกที่เก็บ:
git clone https://github.com/ggerganov/whisper.cpp.gitนำทางไปยังไดเรกทอรี:
cd whisper.cpp
จากนั้นดาวน์โหลดหนึ่งในรุ่น Whisper ที่แปลงในรูปแบบ ggml ตัวอย่างเช่น:
sh ./models/download-ggml-model.sh base.enตอนนี้สร้างตัวอย่างหลักและถอดความไฟล์เสียงเช่นนี้:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav สำหรับการสาธิตอย่างรวดเร็วเพียงแค่เรียก make base.en :
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
คำสั่งดาวน์โหลดโมเดล base.en แปลงเป็นรูปแบบ ggml ที่กำหนดเองและเรียกใช้การอนุมานในตัวอย่าง .wav ทั้งหมดใน samples โฟลเดอร์
สำหรับคำแนะนำการใช้งานโดยละเอียด RUN: ./main -h
โปรดทราบว่าตัวอย่างหลักจะทำงานเฉพาะกับไฟล์ WAV 16 บิตเท่านั้นดังนั้นอย่าลืมแปลงอินพุตของคุณก่อนที่จะเรียกใช้เครื่องมือ ตัวอย่างเช่นคุณสามารถใช้ ffmpeg เช่นนี้:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavหากคุณต้องการตัวอย่างเสียงพิเศษให้เล่นเพียงแค่เรียกใช้:
make -j samples
สิ่งนี้จะดาวน์โหลดไฟล์เสียงอีกสองสามไฟล์จาก Wikipedia และแปลงเป็นรูปแบบ WAV 16 บิตผ่าน ffmpeg
คุณสามารถดาวน์โหลดและเรียกใช้รุ่นอื่น ๆ ดังนี้:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| แบบอย่าง | ดิสก์ | เมม |
|---|---|---|
| ขนาดเล็ก | 75 MIB | ~ 273 MB |
| ฐาน | 142 MIB | ~ 388 MB |
| เล็ก | 466 MIB | ~ 852 MB |
| ปานกลาง | 1.5 กิบ | ~ 2.1 GB |
| ใหญ่ | 2.9 กิบ | ~ 3.9 GB |
whisper.cpp รองรับปริมาณจำนวนเต็มของรุ่น ggml Whisper โมเดลเชิงปริมาณต้องการพื้นที่หน่วยความจำและดิสก์น้อยลงและขึ้นอยู่กับฮาร์ดแวร์สามารถประมวลผลได้อย่างมีประสิทธิภาพมากขึ้น
นี่คือขั้นตอนสำหรับการสร้างและการใช้แบบจำลองเชิงปริมาณ:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav บนอุปกรณ์ Apple Silicon การอนุมานของ ENCODER สามารถดำเนินการบน Apple Neural Engine (ANE) ผ่าน Core ML ซึ่งอาจส่งผลให้เกิดการเร่งความเร็วอย่างมีนัยสำคัญ-เร็วกว่า X3 เร็วกว่าเมื่อเทียบกับการดำเนินการ CPU เท่านั้น นี่คือคำแนะนำสำหรับการสร้างโมเดล ML หลักและใช้กับ whisper.cpp :
ติดตั้งการพึ่งพา Python ที่จำเป็นสำหรับการสร้างรุ่น Core ML:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools ทำงานอย่างถูกต้องโปรดยืนยันว่า XCode ได้รับการติดตั้งและดำเนินการ xcode-select --install เพื่อติดตั้งเครื่องมือบรรทัดคำสั่งconda create -n py310-whisper python=3.10 -yconda activate py310-whisper สร้างโมเดล ML หลัก ตัวอย่างเช่นในการสร้างโมเดล base.en ให้ใช้:
./models/generate-coreml-model.sh base.en สิ่งนี้จะสร้าง models/ggml-base.en-encoder.mlmodelc
สร้าง whisper.cpp ด้วยการสนับสนุน Core ML:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config Releaseเรียกใช้ตัวอย่างตามปกติ ตัวอย่างเช่น:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
การรันครั้งแรกบนอุปกรณ์นั้นช้าเนื่องจากบริการ ANE รวบรวมรุ่น Core ML เป็นรูปแบบเฉพาะอุปกรณ์บางอย่าง การวิ่งครั้งต่อไปจะเร็วขึ้น
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการใช้งาน Core ML โปรดดูที่ PR #566
บนแพลตฟอร์มที่รองรับ OpenVino การอนุมานการเข้ารหัสสามารถดำเนินการบนอุปกรณ์ที่รองรับ OpenVino รวมถึง X86 CPU และ Intel GPU (Integrated & Discrete)
ซึ่งอาจส่งผลให้เกิดการเร่งความเร็วอย่างมีนัยสำคัญในประสิทธิภาพการเข้ารหัส นี่คือคำแนะนำสำหรับการสร้างโมเดล openvino และใช้กับ whisper.cpp :
ขั้นแรกให้ตั้งค่า Python เสมือนจริง env และติดตั้งการพึ่งพา Python แนะนำให้ใช้ Python 3.10
Windows:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux และ MacOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt สร้างโมเดล OpenVino Encoder ตัวอย่างเช่นในการสร้างโมเดล base.en ให้ใช้:
python convert-whisper-to-openvino.py --model base.en
สิ่งนี้จะผลิต ggml-base.en-encoder-openvino.xml/.bin ir โมเดลไฟล์ ขอแนะนำให้ย้ายสิ่งเหล่านี้ไปยังโฟลเดอร์เดียวกับรุ่น ggml เนื่องจากเป็นตำแหน่งเริ่มต้นที่ส่วนขยาย OpenVino จะค้นหาในเวลาทำงาน
สร้าง whisper.cpp ด้วยการสนับสนุน OpenVino:
ดาวน์โหลดแพ็คเกจ OpenVino จากหน้ารีลีส เวอร์ชันที่แนะนำในการใช้คือ 2023.0.0
หลังจากดาวน์โหลดและแยกแพ็คเกจลงในระบบการพัฒนาของคุณให้ตั้งค่าสภาพแวดล้อมที่จำเป็นโดยจัดหาสคริปต์ SetupVars ตัวอย่างเช่น:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.batจากนั้นสร้างโครงการโดยใช้ CMake:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config Releaseเรียกใช้ตัวอย่างตามปกติ ตัวอย่างเช่น:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
การทำงานครั้งแรกบนอุปกรณ์ OpenVino นั้นช้าเนื่องจาก Framework OpenVino จะรวบรวมโมเดล IR (การแสดงระดับกลาง) เป็น 'blob' เฉพาะอุปกรณ์ หยดเฉพาะอุปกรณ์นี้จะถูกแคชสำหรับการวิ่งครั้งต่อไป
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการใช้งาน Core ML โปรดดูที่ PR #1037
ด้วยการ์ด NVIDIA การประมวลผลของโมเดลนั้นทำได้อย่างมีประสิทธิภาพบน GPU ผ่าน Cublas และเมล็ด CUDA ที่กำหนดเอง ก่อนอื่นตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง cuda : https://developer.nvidia.com/cuda-downloads
ตอนนี้สร้าง whisper.cpp ด้วยการสนับสนุน cuda:
make clean
GGML_CUDA=1 make -j
โซลูชันข้ามผู้ขายซึ่งช่วยให้คุณเร่งเวิร์กโหลดใน GPU ของคุณ ก่อนอื่นตรวจสอบให้แน่ใจว่าไดรเวอร์กราฟิกการ์ดของคุณให้การสนับสนุนสำหรับ Vulkan API
ตอนนี้สร้าง whisper.cpp ด้วยการสนับสนุน Vulkan:
make clean
make GGML_VULKAN=1 -j
การประมวลผลเข้ารหัสสามารถเร่งความเร็วใน CPU ผ่าน OpenBLAS ก่อนอื่นให้แน่ใจว่าคุณได้ติดตั้ง openblas : https://www.openblas.net/
ตอนนี้สร้าง whisper.cpp ด้วยการสนับสนุน OpenBlas:
make clean
GGML_OPENBLAS=1 make -j
การประมวลผลตัวเข้ารหัสสามารถเร่งความเร็วใน CPU ผ่านอินเตอร์เฟสที่เข้ากันได้กับ BLAS ของไลบรารีเคอร์เนลคณิตศาสตร์ของ Intel ก่อนอื่นให้แน่ใจว่าคุณได้ติดตั้ง MKL Runtime และแพ็คเกจการพัฒนาของ Intel: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-download.html
ตอนนี้สร้าง whisper.cpp ด้วย Intel Mkl BLAS Support:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
Ascend NPU ให้การเร่งการอนุมานผ่านแกน CANN และ AI
ก่อนอื่นให้ตรวจสอบว่ารองรับอุปกรณ์ Ascend NPU ของคุณหรือไม่:
อุปกรณ์ตรวจสอบ
| ขึ้น NPU | สถานะ |
|---|---|
| Atlas 300t A2 | สนับสนุน |
จากนั้นตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง CANN toolkit แล้ว แนะนำให้ใช้ Cann เวอร์ชันที่ยาวนาน
ตอนนี้สร้าง whisper.cpp ด้วยการสนับสนุน Cann:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
เรียกใช้ตัวอย่างการอนุมานตามปกติเช่น:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
หมายเหตุ:
Verified devices จากตาราง เรามีภาพนักเทียบท่าสองภาพสำหรับโครงการนี้:
ghcr.io/ggerganov/whisper.cpp:main : ภาพนี้มีไฟล์ปฏิบัติการหลักรวมถึง curl และ ffmpeg (แพลตฟอร์ม: linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : เหมือนกับ main แต่รวบรวมด้วยการสนับสนุน cuda (แพลตฟอร์ม: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " คุณสามารถติดตั้งไบนารีที่สร้างไว้ล่วงหน้าสำหรับ Whisper.cpp หรือสร้างจากแหล่งที่มาโดยใช้โคนัน ใช้คำสั่งต่อไปนี้:
conan install --requires="whisper-cpp/[*]" --build=missing
สำหรับคำแนะนำโดยละเอียดเกี่ยวกับวิธีการใช้โคนันโปรดดูเอกสารของโคนัน
นี่เป็นอีกตัวอย่างหนึ่งของการถอดความคำพูด 3:24 นาทีในเวลาประมาณครึ่งนาทีใน MacBook M1 Pro โดยใช้ medium.en Model:
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
นี่เป็นตัวอย่างที่ไร้เดียงสาของการอนุมานแบบเรียลไทม์บนเสียงจากไมโครโฟนของคุณ เครื่องมือสตรีมตัวอย่างเสียงทุกครึ่งวินาทีและรันการถอดรหัสอย่างต่อเนื่อง ข้อมูลเพิ่มเติมมีอยู่ในปัญหา #10
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 การเพิ่มอาร์กิวเมนต์ --print-colors จะพิมพ์ข้อความที่ถอดความโดยใช้กลยุทธ์การเข้ารหัสสีทดลองเพื่อเน้นคำที่มีความมั่นใจสูงหรือต่ำ:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors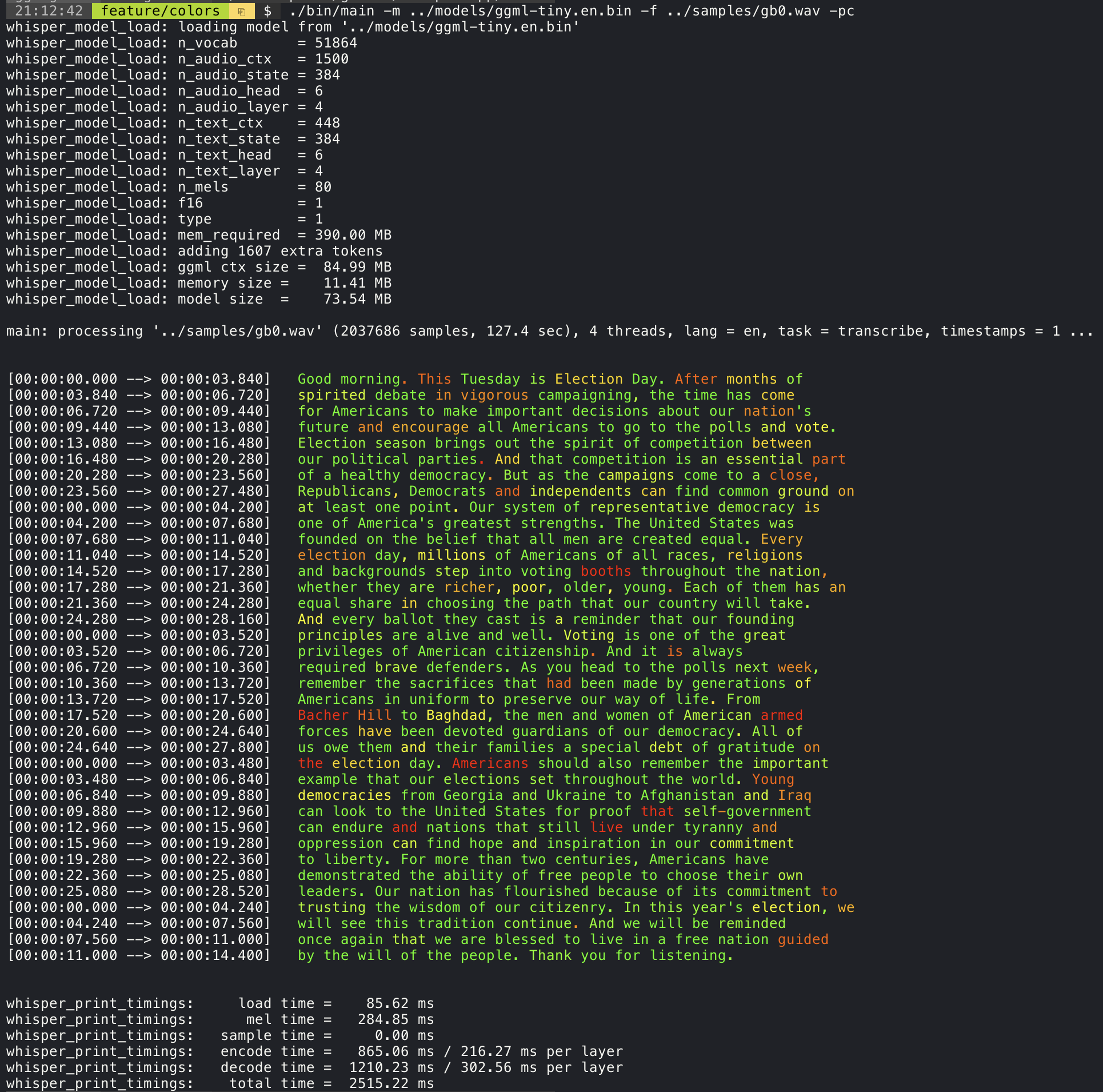
ตัวอย่างเช่นเพื่อ จำกัด ความยาวของเส้นให้สูงสุด 16 อักขระเพียงเพิ่ม -ml 16 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
อาร์กิวเมนต์ --max-len สามารถใช้เพื่อรับการประทับเวลาระดับคำ เพียงแค่ใช้ -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
ข้อมูลเพิ่มเติมเกี่ยวกับวิธีการนี้มีอยู่ที่นี่: #1058
ตัวอย่างการใช้งาน:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . ตัวอย่างหลักให้การสนับสนุนการส่งออกของภาพยนตร์สไตล์คาราโอเกะซึ่งมีการเน้นคำที่เด่นชัดในปัจจุบัน ใช้อาร์กิวเมนต์ -wts และเรียกใช้สคริปต์ Bash ที่สร้างขึ้น สิ่งนี้ต้องมีการติดตั้ง ffmpeg
นี่คือตัวอย่าง "ทั่วไป" บางประการ:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4ใช้สคริปต์สคริปต์/bench-wts.sh เพื่อสร้างวิดีโอในรูปแบบต่อไปนี้:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4เพื่อให้มีการเปรียบเทียบวัตถุประสงค์ของประสิทธิภาพของการอนุมานในการกำหนดค่าระบบที่แตกต่างกันให้ใช้เครื่องมือบัลลังก์ เครื่องมือเพียงแค่เรียกใช้ส่วนของตัวเข้ารหัสของโมเดลและพิมพ์ระยะเวลาที่ใช้เวลาในการดำเนินการ ผลลัพธ์จะสรุปในปัญหา GitHub ต่อไปนี้:
ผลการวัดผล
นอกจากนี้สคริปต์เพื่อเรียกใช้ Whisper.cpp ด้วยรุ่นที่แตกต่างกันและไฟล์เสียงมีให้ bench.py
คุณสามารถเรียกใช้ด้วยคำสั่งต่อไปนี้โดยค่าเริ่มต้นจะทำงานกับรุ่นมาตรฐานใด ๆ ในโฟลเดอร์โมเดล
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2มันถูกเขียนขึ้นใน Python ด้วยความตั้งใจที่จะแก้ไขและขยายสำหรับกรณีการใช้งานเปรียบเทียบของคุณ
มันส่งออกไฟล์ CSV พร้อมผลลัพธ์ของการเปรียบเทียบ
ggmlรุ่นดั้งเดิมจะถูกแปลงเป็นรูปแบบไบนารีที่กำหนดเอง สิ่งนี้ช่วยให้สามารถบรรจุทุกสิ่งที่จำเป็นลงในไฟล์เดียว:
คุณสามารถดาวน์โหลดโมเดลที่แปลงได้โดยใช้สคริปต์ Models/Download-GGML-model.sh หรือด้วยตนเองจากที่นี่:
สำหรับรายละเอียดเพิ่มเติมโปรดดูที่โมเดลสคริปต์การแปลง/convert-pt-to-ggml.py หรือ models/readme.md
มีตัวอย่างต่าง ๆ ของการใช้ห้องสมุดสำหรับโครงการต่าง ๆ ในโฟลเดอร์ตัวอย่าง ตัวอย่างบางส่วนถูกพอร์ตให้ทำงานในเบราว์เซอร์โดยใช้ webassembly ตรวจสอบพวกเขา!
| ตัวอย่าง | เว็บ | คำอธิบาย |
|---|---|---|
| หลัก | Whisper.wasm | เครื่องมือสำหรับการแปลและถอดเสียงโดยใช้ Whisper |
| ม้านั่ง | ม้านั่ง | เกณฑ์มาตรฐานประสิทธิภาพของ Whisper บนเครื่องของคุณ |
| ลำธาร | สตรีม | การถอดรหัสการจับไมโครโฟนดิบแบบเรียลไทม์ |
| สั่งการ | command.wasm | ตัวอย่างผู้ช่วยเสียงพื้นฐานสำหรับการรับคำสั่งเสียงจากไมค์ |
| WCHESS | wchess.wasm | หมากรุกควบคุมเสียง |
| พูดคุย | talk.wass | พูดคุยกับบอท GPT-2 |
| talk-llama | พูดคุยกับบอท llama | |
| Whisper.objc | แอปพลิเคชัน iOS มือถือโดยใช้ whisper.cpp | |
| Whisper.swiftui | แอปพลิเคชัน Swiftui iOS / MacOS โดยใช้ Whisper.cpp | |
| Whisper.android | แอปพลิเคชั่น Android Mobile โดยใช้ whisper.cpp | |
| Whisper.nvim | ปลั๊กอินคำพูดเป็นข้อความสำหรับ NeoVim | |
| generate-karaoke.sh | สคริปต์ผู้ช่วยสร้างวิดีโอคาราโอเกะของการจับเสียงดิบได้อย่างง่ายดาย | |
| livestream.sh | การถอดเสียง | |
| yt-wsp.sh | ดาวน์โหลด + ถอดความและ/หรือแปล VOD ใด ๆ (ต้นฉบับ) | |
| เซิร์ฟเวอร์ | เซิร์ฟเวอร์การถอดรหัส http พร้อม API เหมือน OAI |
หากคุณมีข้อเสนอแนะใด ๆ เกี่ยวกับโครงการนี้อย่าลังเลที่จะใช้ส่วนการอภิปรายและเปิดหัวข้อใหม่ คุณสามารถใช้หมวดหมู่การแสดงและบอกเพื่อแบ่งปันโครงการของคุณเองที่ใช้ whisper.cpp หากคุณมีคำถามตรวจสอบให้แน่ใจว่าได้ตรวจสอบการสนทนาคำถามที่พบบ่อย (#126)


