คอลเล็กชั่นที่ยอดเยี่ยมสำหรับ LLM ในภาษาจีน
รวบรวมและจัดเรียง LLM จีนที่เกี่ยวข้อง
เนื่องจากการปรากฏตัวของรูปแบบภาษาขนาดใหญ่ (LLM) แสดงโดย ChatGPT เนื่องจากความสามารถที่น่าทึ่งของปัญญาประดิษฐ์สากล (AGI) ทั่วไป -อเนกประสงค์ (AGI) จึงได้สร้างคลื่นของการวิจัยและการประยุกต์ใช้ในด้านการประมวลผลภาษาธรรมชาติ โดยเฉพาะอย่างยิ่งหลังจากโอเพ่นซอร์ส LLM ขนาดเล็กที่สามารถทำงานกับ Chatglm, Llama และผู้เล่นพลเรือนอื่น ๆ สามารถวิ่งได้มีหลายกรณีของ LLM ที่ปรับน้อยที่สุดหรือแอปพลิเคชันตาม LLM โครงการนี้มีวัตถุประสงค์เพื่อรวบรวมและจัดเรียงโมเดลโอเพ่นซอร์สแอปพลิเคชันชุดข้อมูลและบทเรียนที่เกี่ยวข้องกับ LLM จีน
หากโครงการนี้สามารถช่วยคุณได้เล็กน้อยโปรดให้ฉันหน่อย ~
ในเวลาเดียวกันคุณยังสามารถนำไปใช้กับโมเดลโอเพนซอร์สที่ไม่เป็นที่นิยมแอปพลิเคชันชุดข้อมูล ฯลฯ ของโครงการนี้ ให้ข้อมูลคลังสินค้าใหม่โปรดเริ่มต้น PR และให้ข้อมูลที่เกี่ยวข้องเช่นลิงก์คลังสินค้าจำนวนดาวโปรไฟล์การบรรยายสรุปและข้อมูลอื่น ๆ ที่เกี่ยวข้องตามรูปแบบของโครงการนี้
ภาพรวมรายละเอียดแบบจำลองพื้นฐานทั่วไป:
ฐาน รวมโมเดล ขนาดพารามิเตอร์รุ่น หมายเลขโทเค็นเส้นทาง การฝึกอบรมสูงสุด ไม่ว่าจะเป็นการค้า chatglm chatglm/2/3/4 ฐาน & แชท 6B 1T/1.4 2K/32K การใช้งานเชิงพาณิชย์ ลาม่า llama/2/3 ฐานและแชท 7b/8b/13b/33b/70b 1T/2T 2K/4K ทำการค้าบางส่วน ชาวไชน่า Baichuan/2 ฐาน & แชท 7b/13b 1.2t/1.4t 4K การใช้งานเชิงพาณิชย์ Qwen QWEN/1.5/2/2.5 BASE & ChAT & VL 7b/14b/32b/72b/110b 2.2T/3T/18T 8K/32K การใช้งานเชิงพาณิชย์ ผลิบาน ผลิบาน 1B/7B/176B-MT 1.5T 2K การใช้งานเชิงพาณิชย์ อควิลล่า Aquila/2 ฐาน/แชท 7b/34b - 2K การใช้งานเชิงพาณิชย์ อินเทอร์เน็ต อินเทอร์เน็ต 7b/20b - 200k การใช้งานเชิงพาณิชย์ มิกซ์แทรค ฐานและแชท 8x7b - 32K การใช้งานเชิงพาณิชย์ ยี่ ฐานและแชท 6b/9b/34b 3T 200k การใช้งานเชิงพาณิชย์ ลึกล้ำ ฐานและแชท 1.3b/7b/33b/67b - 4K การใช้งานเชิงพาณิชย์ Xverse ฐานและแชท 7B/13B/65B/A4.2B 2.6t/3.2t 8K/16K/256K การใช้งานเชิงพาณิชย์
สารบัญ สารบัญ 1. รุ่น 1.1 ข้อความ LLM รุ่น 1.2 รุ่น LLM Multifamily 2. แอปพลิเคชัน 2.1 การกรองในสนามแนวตั้ง การรักษาพยาบาล กฎ การเงิน ให้ความรู้ วิทยาศาสตร์และเทคโนโลยี e -commerce ความปลอดภัยของเครือข่าย เกษตรกรรม 2.2 แอปพลิเคชัน Langchain 2.3 แอปพลิเคชันอื่น ๆ 3. ชุดข้อมูล ชุดข้อมูลการฝึกอบรมก่อน ชุดข้อมูล SFT ชุดข้อมูลการตั้งค่า 4. การฝึกอบรม LLM Fine Framework 5. LLM Framework การปรับใช้เหตุผล 6. การประเมิน LLM 7. การสอน LLM LLM ความรู้พื้นฐาน กระตุ้นการสอนด้านวิศวกรรม การสอนแอปพลิเคชัน LLM LLM การสอนการต่อสู้จริง 8. คลังสินค้าที่เกี่ยวข้อง ประวัติดาว
1. รุ่น
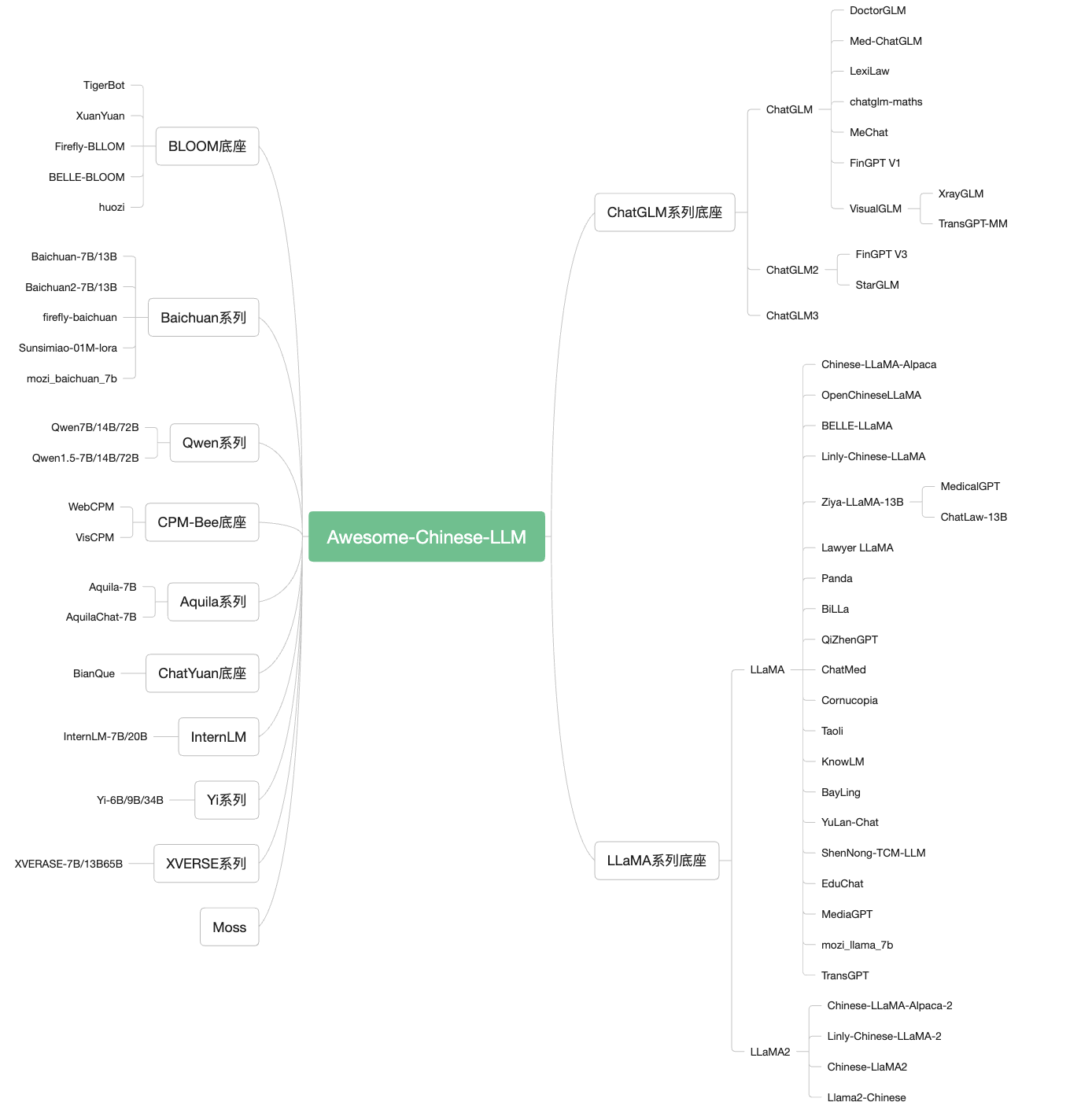
1.1 ข้อความ LLM รุ่น chatglm: ที่อยู่: https://github.com/thudm/chatglm-6b บทนำ: หนึ่งในโมเดลฐานโอเพ่นซอร์สที่มีประสิทธิภาพมากที่สุดในเขตข้อมูลจีนได้ปรับการตอบคำถามและบทสนทนาของจีนให้เหมาะสม หลังจากการฝึกอบรมสองภาษาของตัวระบุประมาณ 1T เสริมด้วยเทคโนโลยีเช่นการกำกับดูแลการปรับแต่งการตอบรับข้อเสนอแนะและข้อเสนอแนะจากข้อเสนอแนะของมนุษย์เพื่อเสริมสร้างการเรียนรู้ chatglm2-6b ที่อยู่: https://github.com/thudm/chatglm2-6b บทนำ: ขึ้นอยู่กับรุ่นที่สองของโอเพนซอร์สจีนและภาษาอังกฤษรูปแบบการสนทนา Chatglm-6B มันได้แนะนำฟังก์ชั่นเป้าหมายไฮบริดของ GLM บนพื้นฐานของการสนทนาแบบจำลองที่ได้รับการอนุรักษ์และเกณฑ์การปรับใช้ต่ำซึ่งได้รับการรักษาไว้ก่อน -การฝึกฝนสัญลักษณ์การระบุตัวตนของอังกฤษใน T และการจัดตำแหน่งของการตั้งค่าของมนุษย์; การใช้งานเชิงพาณิชย์ chatglm3-6b ที่อยู่: https://github.com/thudm/chatglm3 บทนำ: ChatGLM3-6B เป็นโมเดลโอเพ่นซอร์สในซีรี่ส์ ChatGLM3 : Chatglm3-6b-base รุ่นพื้นฐานของ Chatglm3- 6B ใช้ข้อมูลการฝึกอบรมเพิ่มเติมขั้นตอนการฝึกอบรมที่สมบูรณ์มากขึ้นและกลยุทธ์การฝึกอบรมที่สมเหตุสมผลมากขึ้น同时原生支持工具调用( การเรียกใช้ฟังก์ชัน) 、代码执行( code interpreter) 和 任务等复杂场景;更全面的开源序列: 除了对话模型 chatglm3-6b 外, 还开源了基础模型 chatglm3-6b-base ( บทสนทนาโมเดลบทสนทนา chatglm3-6b-32k น้ำหนักข้างต้นเปิดให้มีการวิจัยเชิงวิชาการอย่างสมบูรณ์และอนุญาตให้ใช้งานเชิงพาณิชย์ได้ฟรีหลังจากกรอกแบบสอบถาม GLM-4 ที่อยู่: https://github.com/thudm/glm-4 บทนำสั้น ๆ : GLM-4-9B เป็นเวอร์ชันโอเพ่นซอร์สของรุ่นก่อนการฝึกอบรมรุ่นล่าสุดที่เปิดตัวโดย Smart Spectrum AI ในการประเมินชุดข้อมูลเช่นความหมาย, คณิตศาสตร์, การใช้เหตุผล, รหัสและความรู้, GLM-4-9B และเวอร์ชันการตั้งค่าของมนุษย์ของ GLM-4-9B-Chat แสดงให้เห็นถึงประสิทธิภาพที่ยอดเยี่ยมนอกเหนือจาก LLAMA-3-8B Essence นอกเหนือจากบทสนทนาหลายรอบแล้ว GLM-4-9B-Chat ยังมีฟังก์ชั่นขั้นสูงเช่นการท่องเว็บการดำเนินการรหัสการเรียกใช้เครื่องมือที่กำหนดเอง (การเรียกใช้ฟังก์ชัน) และการให้เหตุผลข้อความยาว (สนับสนุนบริบทสูงสุด 128K สูงสุด) รุ่นนี้ได้เพิ่มการสนับสนุนหลายภาษาสนับสนุน 26 ภาษารวมถึงญี่ปุ่นเกาหลีและเยอรมัน นอกจากนี้เรายังเปิดตัวรุ่น GLM-4-9B-Chat-1M ที่รองรับความยาวตามบริบท 1M (ประมาณ 2 ล้านตัวอักษรจีน) และรุ่นหลายโหมด GLM-4V-9B ตาม GLM-4-9B GLM-4V-9B มีความสามารถในการสนทนาหลายภาษาหลายภาษาหลายภาษาภายใต้ความละเอียดสูงที่ 1120 * 1120 ในหลาย ๆ ด้านของการประเมินแบบหลายรูปแบบเช่นความสามารถที่ครอบคลุมของจีนและภาษาอังกฤษ -9B แสดงประสิทธิภาพที่ยอดเยี่ยมของการเกิน GPT-4-Turbo-20124-04-09, Gemini 1.0 Pro, Qwen-VL-Max และ Claude 3 Opus QWEN/QWEN1.5/QWEN2/QWEN2.5 ที่อยู่: https://github.com/qwenlm บทนำ: Tongyi Qianwen เป็นชุดของแบบจำลองของแบบจำลองของ Tongyi Qianwen ที่พัฒนาโดย Alibaba Cloud รวมถึงมาตราส่วนพารามิเตอร์ 1.8 พันล้าน (1.8b), 7 พันล้าน (7b), 14 พันล้าน (14b), 72 พันล้าน (72b), 1100 และ 1100 1100 100 ล้าน (110B) แบบจำลองของแต่ละสเกลรวมถึงรุ่นพื้นฐาน Qwen และโมเดลโต้ตอบ ชุดข้อมูลรวมถึงประเภทข้อมูลที่หลากหลายเช่นข้อความและรหัส เรียกปลั๊ก -อินและอัพเกรดเป็นเอเจนซ์เอเจนต์ได้อย่างมีประสิทธิภาพ อินเทอร์เน็ต ที่อยู่: https://github.com/internlm/internlm-techreport บทนำ: เทคโนโลยี Shangtang, ห้องปฏิบัติการเซี่ยงไฮ้ AI และมหาวิทยาลัยจีนแห่งฮ่องกง, มหาวิทยาลัย Fudan และมหาวิทยาลัยเซี่ยงไฮ้ Jiaotong เปิดตัวพารามิเตอร์ระดับ 100 พันล้านระดับ "ทุนการศึกษา" มีรายงานว่า "Scholar PU" มีพารามิเตอร์ 104 พันล้านพารามิเตอร์และได้รับการฝึกฝนตาม "ชุดข้อมูลคุณภาพสูงหลายภาษาที่มีโทเค็น 1.6 ล้านล้าน" อินเทอร์เน็ต ที่อยู่: https://github.com/internlm/internlm บทนำ: Shangtang Technology, ห้องปฏิบัติการเซี่ยงไฮ้ AI และมหาวิทยาลัยจีนแห่งฮ่องกง, มหาวิทยาลัย Fudan และมหาวิทยาลัยเซี่ยงไฮ้ Jiaotong ได้เปิดตัวพารามิเตอร์ขนาดใหญ่ 100 พันล้านรูปแบบ "InternLM2" InternLM2 มีความก้าวหน้าอย่างมากในด้านดิจิตอลรหัสบทสนทนาและการสร้างและประสิทธิภาพที่ครอบคลุมได้ถึงระดับนำของโมเดลโอเพ่นซอร์ส InternLM2 มีสองรุ่น: 7B และ 20B 7B ให้แบบจำลองที่มีน้ำหนักเบา แต่เป็นเอกลักษณ์สำหรับการวิจัยและการประยุกต์ใช้น้ำหนักเบา deepseek-v2 ที่อยู่: https://github.com/deepseek-ai/deepseek-v2 บทนำ: Deepseek-V2: แบบจำลองภาษาไฮบริดที่มีประสิทธิภาพประหยัดและมีประสิทธิภาพ Baichuan-7b ที่อยู่: https://github.com/baichuan-inc/baichuan-7b บทนำ: รูปแบบภาษาการฝึกอบรมขนาดใหญ่ขนาดใหญ่ที่พัฒนาโดยการพัฒนาอัจฉริยะ Baichuan ขึ้นอยู่กับโครงสร้างของหม้อแปลงโมเดลพารามิเตอร์ 7 พันล้านที่ผ่านการฝึกอบรมเกี่ยวกับโทเค็นประมาณ 1.2 ล้านล้านนั้นรองรับภาษาจีนและภาษาอังกฤษสองภาษาและความยาวของหน้าต่างบริบทคือ 4096 ทั้งมาตรฐานของหน่วยงานมาตรฐานจีนและภาษาอังกฤษ (C-EVAL/MMLU) มีผลดีที่สุดในขนาดเดียวกัน Baichuan-13b ที่อยู่: https://github.com/baichuan-inc/baichuan-13b บทนำ: Baichuan-13b เป็นรูปแบบภาษาขนาดใหญ่ที่มีพารามิเตอร์ 13 พันล้านหลังจาก Baichuan-7b หลังจาก Baichuan-7b โครงการเผยแพร่สองเวอร์ชัน: Baichuan-13b-base และ Baichuan-13b-Chat Baichuan2 ที่อยู่: https://github.com/baichuan-inc/baichuan22 บทนำ: รุ่นใหม่ของโอเพ่นซอร์สขนาดใหญ่ที่เปิดตัวโดย Baichuan Intelligence ใช้โทเค็น 2.6 ล้านล้านเพื่อฝึกอบรมด้วยคลังข้อมูลคุณภาพสูง . Xverse-7b ที่อยู่: https://github.com/xverse- ai/xverse-7b บทนำ: รูปแบบภาษาขนาดใหญ่ที่สนับสนุนโดยเทคโนโลยีเซินเจิ้น Yuanxiang รองรับโมเดลหลายภาษารองรับความยาวบริบท 8K และใช้ข้อมูลคุณภาพสูงและหลากหลายของโทเค็น 2.6 ล้านล้านโทเค็นเพื่อฝึกอบรมแบบจำลอง รัสเซียและตะวันตก นอกจากนี้ยังรวมถึงรุ่นของรุ่น GGUF และ GPTQ เชิงปริมาณซึ่งรองรับการใช้เหตุผลใน LLAMA.CPP และ VLLM บนระบบ MACOS/Linux/Windows Xverse-13b ที่อยู่: https://github.com/xverse- ai/xverse-13b บทนำ: โมเดลภาษาขนาดใหญ่ที่สนับสนุนโดยเทคโนโลยีเซินเจิ้น Yuanxiang ที่สนับสนุนโมเดลหลายภาษาสนับสนุนความยาวบริบท 8K (ความยาวบริบท) และการใช้ข้อมูลคุณภาพสูงและหลากหลายของโทเค็น 3.2 ล้านล้านโทเค็นเพื่อฝึกอบรมแบบจำลองอย่างเต็มที่ ในฐานะสหราชอาณาจักรรัสเซียและตะวันตก รวมถึงรูปแบบการโต้ตอบลำดับยาว XVerse-13b-256k นอกจากนี้ยังรวมถึงรุ่นของรุ่น GGUF และ GPTQ เชิงปริมาณซึ่งรองรับการใช้เหตุผลใน LLAMA.CPP และ VLLM บนระบบ MACOS/Linux/Windows Xverse-65b ที่อยู่: https://github.com/xverse- ai/xverse-65b บทนำ: รูปแบบภาษาขนาดใหญ่ที่สนับสนุนโดยเทคโนโลยีเซินเจิ้น Yuanxiang รองรับแบบจำลองหลายภาษารองรับความยาวบริบทของ 16K และใช้ข้อมูลคุณภาพสูงและหลากหลายของโทเค็น 2.6 ล้านล้านเพื่อฝึกอบรมแบบจำลอง ภาษาเช่นสหราชอาณาจักรรัสเซียและตะวันตก รวมถึงโมเดล Xverse-65b-2 ที่เพิ่มขึ้นล่วงหน้าด้วยการฝึกอบรมล่วงหน้าที่เพิ่มขึ้น นอกจากนี้ยังรวมถึงรุ่นของรุ่น GGUF และ GPTQ เชิงปริมาณซึ่งรองรับการใช้เหตุผลใน LLAMA.CPP และ VLLM บนระบบ MACOS/Linux/Windows Xverse-MoE-A4.2B ที่อยู่: https://github.com/xverse- ai/xverse-moe-a4.2b บทนำ: รูปแบบภาษาขนาดใหญ่ซึ่งรองรับหลายภาษาที่พัฒนาขึ้นอย่างอิสระโดยเทคโนโลยีเซินเจิ้น Yuanxiang สนับสนุนมากกว่า 40 ภาษาเช่นจีนสหราชอาณาจักรรัสเซียและตะวันตก เวิร์กเวิร์ก ที่อยู่: https://github.com/skyworkai/skywork บทนำ: โครงการเปิดรับรุ่น Tiangong Series โมเดล Skywork-13b-base เฉพาะรุ่น Skywork-13b-Chat โมเดล Skywork-13b-Math โมเดล Skywork-13b-MM และรุ่นรุ่นเชิงปริมาณของแต่ละรุ่นเพื่อสนับสนุนผู้ใช้เพื่อปรับใช้และให้เหตุผลในการปรับใช้การ์ดกราฟิกผู้บริโภคและ การให้เหตุผลสำคัญ ยี่ ที่อยู่: https://github.com/01- ai/yi บทนำสั้น ๆ : โครงการนี้เปิดให้มีรุ่นเช่น YI-6B และ YI-34B เอกสารที่มีมากกว่า 1,000 หน้า Chinese-Llama-Alpaca: ที่อยู่: https://github.com/ymcui/chinese-llama-alpaca บทนำ: รูปแบบภาษาขนาดใหญ่ของจีนและอัลปากา+การปรับใช้ CPU/GPU ในท้องถิ่น Chinese-Llama-Alpaca-2: ที่อยู่: https://github.com/ymcui/chinese-llama-alpaca-2 บทนำ: โครงการจะตีพิมพ์รูปแบบภาษาขนาดใหญ่ของจีน Llama-2 & Alpaca-2 โดยอิงตามเชิงพาณิชย์ Llama-2 สำหรับการพัฒนารอง Chinese-llama2: ที่อยู่: https://github.com/michael-wzhu/chinese-llama2 บทนำ: โครงการนี้มีพื้นฐานมาจากการพัฒนาที่สองในเชิงพาณิชย์ -ปรับหลายรอบเพื่อปรับให้เข้ากับสถานการณ์แอปพลิเคชันต่างๆและการโต้ตอบการสนทนาหลายรอบ ในเวลาเดียวกันเรายังพิจารณาโซลูชันการปรับตัวของจีนที่เร็วขึ้น: Chinese-Llama2-SFT-V0: ใช้คำแนะนำภาษาจีนโอเพ่นซอร์สที่มีอยู่ในปัจจุบันการปรับจูนหรือข้อมูลการสนทนาเพื่อปรับแต่ง Llama-2 โดยตรง (จะเป็นโอเพ่นซอร์สเมื่อเร็ว ๆ นี้) Llama2-Chinese: ที่อยู่: https://github.com/flagalpha/llama2-chinese บทนำ: โครงการมุ่งเน้นไปที่การเพิ่มประสิทธิภาพของโมเดล LLAMA2 ในการก่อสร้างจีนและระดับสูง Openchinesellama: ที่อยู่: https://github.com/openlmlab/openchinesellama บทนำ: ขึ้นอยู่กับ LLAMA-7B ซึ่งเป็นฐานแบบจำลองภาษาขนาดใหญ่ที่สร้างขึ้นโดยการฝึกอบรมชุดข้อมูลที่เพิ่มขึ้นก่อนการฝึกอบรมของจีนเมื่อเทียบกับ LLAMA ดั้งเดิมรุ่นนี้ได้รับการปรับปรุงอย่างมากในแง่ของความเข้าใจและความสามารถในการสร้างของจีน . เบลล์: ที่อยู่: https://github.com/lianjiaatech/belle บทนำ: โอเพ่นซอร์สสำหรับชุดของแบบจำลองที่ใช้การเพิ่มประสิทธิภาพของ Bloomz และ Llama อัลกอริทึมการฝึกอบรมเกี่ยวกับประสิทธิภาพของโมเดล แพนด้า: ที่อยู่: https://github.com/dandelionsllm/pandallmm บทนำ: โอเพ่นซอร์สขึ้นอยู่กับ LLAMA -7B, -13B, -33B, -65B สำหรับแบบจำลองภาษาก่อนการฝึกอบรมอย่างต่อเนื่องในสาขาจีนและใช้ข้อมูลเกือบ 15 เมตรสำหรับการฝึกอบรมก่อน โรบิน (โรบิน): ที่อยู่: https://github.com/optimalscale/lmflow บทนำสั้น ๆ : Robin (Robin) เป็นรูปแบบสองภาษาจีน -ภาษาจีนที่พัฒนาโดยทีม LMFlow ของมหาวิทยาลัยวิทยาศาสตร์และเทคโนโลยีของจีน เฉพาะโมเดลที่สองของโรบินที่ได้รับจากข้อมูลเพียง 180k ข้อมูลเท่านั้นที่ได้รับการปรับจูนถึงสถานที่แรกในรายการ HuggingFace LMFLOW สนับสนุนผู้ใช้เพื่อฝึกอบรมโมเดลส่วนบุคคลอย่างรวดเร็ว Fengshenbang-LM: ที่อยู่: https://github.com/idea-ccnl/fengshenbang-lm บทนำ: Fengshenbang-LM (แบบจำลองขนาดใหญ่ของ God) เป็นระบบโอเพนซอร์สขนาดใหญ่ที่ถูกครอบงำโดยสถาบันวิจัยความรู้ความเข้าใจและศูนย์วิจัยภาษาธรรมชาติ , การเขียนคำโฆษณา, แบบทดสอบสามัญสำนึกและการคำนวณทางคณิตศาสตร์ นอกเหนือจากรุ่น Jiangziya แล้วโครงการยังเปิดให้กับโมเดลเช่นซีรี่ส์ Taiyi และ Erlang God Billa: ที่อยู่: https://github.com/neutralzz/billa บทนำสั้น ๆ : โครงการนี้เป็นแหล่งโอเพ่นซอร์สของจีน -รุ่น Llama สองภาษาที่มีความสามารถในการใช้เหตุผลที่เพิ่มขึ้น คุณลักษณะหลักของแบบจำลองคือ: เพิ่มความสามารถในการทำความเข้าใจภาษาจีนของ Llama อย่างมากและลดความเสียหายให้กับความสามารถของภาษาอังกฤษของ Llama ดั้งเดิมมากที่สุดเท่าที่จะทำได้ ภารกิจการทำความเข้าใจแบบจำลองเพื่อแก้ปัญหาตรรกะของงาน มอส: ที่อยู่: https://github.com/openlmlab/moss บทนำ: สนับสนุนรูปแบบภาษาโอเพ่นซอร์สของภาษาจีนและภาษาอังกฤษสองภาษาและหลายปลั๊กอิน การฝึกอบรมการตั้งค่ามันมีคำแนะนำการสนทนาปลั๊กในการเรียนรู้และการฝึกอบรมการตั้งค่าของมนุษย์ luotuo-chinese-llm: ที่อยู่: https://github.com/lc1332/luotuo-chinese-llm บทนำ: มันมีชุดของโครงการโอเพนซอร์สของแบบจำลองภาษาจีนขนาดใหญ่ซึ่งมีชุดของแบบจำลองภาษาตามโมเดลโอเพ่นซอร์สที่มีอยู่ (Moss, Llama), คำแนะนำเกี่ยวกับชุดข้อมูลที่ดี LINLY: ที่อยู่: https://github.com/cvi-szu/linly บทนำ: ให้รูปแบบการสนทนาภาษาจีน Linly-Chatflow, รุ่นพื้นฐานของจีน Linly-Chinese-Llama และข้อมูลการฝึกอบรม รูปแบบพื้นฐานของจีนนั้นมีพื้นฐานมาจาก Llama โดยใช้การฝึกอบรมที่เพิ่มขึ้นอย่างต่อเนื่องของจีนและจีนและอังกฤษและอังกฤษ โครงการสรุปข้อมูลการเรียนการสอนหลายภาษาในปัจจุบันดำเนินการคำแนะนำขนาดใหญ่เพื่อติดตามโมเดลจีนเพื่อติดตามการฝึกอบรมและตระหนักถึงรูปแบบการสนทนา Linly-Chatflow หิ่งห้อย: ที่อยู่: https://github.com/yangjianxin1/firefly บทนำ: Firefly เป็นโครงการรูปแบบภาษาจีนโอเพ่นซอร์สขนาดใหญ่ เช่น Baichuan Baichuan, Ziya, Bloom, Llama ฯลฯ ถือ Lora และโมเดลฐานเพื่อรวมน้ำหนักซึ่งสะดวกกว่าสำหรับเหตุผล Chatyuan ที่อยู่: https://github.com/clue- ai/chatyuan บทนำ: ชุดของแบบจำลองภาษาบทสนทนาที่ใช้งานได้ซึ่งสนับสนุนโดย Yuanyu Intelligent ซึ่งสนับสนุนบทสนทนาสองภาษาของ Sino -British, ปรับให้เหมาะสมในข้อมูลการปรับแต่งการเรียนรู้ข้อเสนอแนะของมนุษย์ chatrwkv: ที่อยู่: https://github.com/blinkdl/chatrwkv บทนำ: โอเพ่นซอร์สชุดการแชท (รวมถึงภาษาอังกฤษและภาษาจีน) ตามสถาปัตยกรรม RWKV, โมเดลที่ตีพิมพ์รวมถึง Raven, Novel-Chneng, Novel-CH และนวนิยาย-Chneng-Chnpro สามารถแชทและเล่นบทกวีนวนิยายและอื่น ๆ ได้โดยตรง การสร้างสรรค์ CPM-BEE ที่อยู่: https://github.com/openbmbmbmb/cpm-bee บทนำสั้น ๆ : โอเพ่นซอร์สเต็มรูปแบบการใช้งานเชิงพาณิชย์ที่อนุญาตของ 10 พันล้านพารามิเตอร์รุ่นจีนและภาษาอังกฤษ มันใช้สถาปัตยกรรมการถดถอยอัตโนมัติของหม้อแปลงเพื่อดำเนินการฝึกอบรมล่วงหน้าในคลังข้อมูลคุณภาพสูงในล้านล้านและมีความสามารถพื้นฐานที่แข็งแกร่ง นักพัฒนาและนักวิจัยสามารถปรับให้เข้ากับสถานการณ์ต่าง ๆ บนพื้นฐานของโมเดลฐาน CPM-BEE เพื่อสร้างโมเดลแอปพลิเคชันในสาขาเฉพาะ Tigerbot ที่อยู่: https://github.com/tigerresearch/tigerbot บทนำ: รูปแบบภาษาขนาดใหญ่ (LLM) ที่มีหลายภาษาและหลายงาน (LLM) โอเพนซอร์ซรวมถึงรุ่น: TigerBot-7B, TigerBot-7B-Base, TigerBot-180B, การฝึกอบรมขั้นพื้นฐานและรหัสการใช้เหตุผล ข้อมูลการฝึกอบรมล่วงหน้าครอบคลุมการเงินและกฎหมายสาขาสารานุกรมและ API อควิลล่า ที่อยู่: https://github.com/flagai-open/flagai/tree/examples/aquilala บทนำ: จัดพิมพ์โดยสถาบันวิจัย Zhiyuan รูปแบบภาษา Aquila ได้รับการสืบทอดข้อได้เปรียบในการออกแบบสถาปัตยกรรมของ GPT-3, Llama ฯลฯ แทนที่กลุ่มของผู้ให้บริการพื้นฐานที่มีประสิทธิภาพมากขึ้นเพื่อให้บรรลุการออกแบบ Tokenizer ภาษาจีนและภาษาอังกฤษ วิธีการฝึกอบรมเริ่มต้นจาก 0 บนพื้นฐานของคลังข้อมูลคุณภาพสูงของจีนและภาษาอังกฤษ นอกจากนี้ยังเป็นรูปแบบภาษาโอเพนซอร์สขนาดใหญ่รุ่นแรกที่สนับสนุนความรู้สองภาษาของชิโน -อังกฤษสนับสนุนข้อตกลงใบอนุญาตเชิงพาณิชย์และตอบสนองความต้องการของการปฏิบัติตามข้อมูลภายในประเทศ Aquila2 ที่อยู่: https://github.com/flagai-open/aquila2 บทนำ: เผยแพร่โดยสถาบันวิจัย Zhiyuan, Aquila2 Series รวมถึงรูปแบบภาษาพื้นฐาน Aquila2-7B, Aquila2-34b และ Aquila2-70B-Expr, รูปแบบการสนทนา Aquilachat2-7B, Aquilachat2-34B และ Aquilachat2-70B-Expr -7B-16K และ Aquilachat2-34B-16 อนิเมะ ที่อยู่: https://github.com/lyogavin/anima บทนำ: รูปแบบภาษาจีน 33B ที่ใช้ QLORA ที่พัฒนาโดยเทคโนโลยี AI Ten จากการประเมินทัวร์นาเมนต์การให้คะแนน ELO นั้นดีกว่า ความรู้ ที่อยู่: https://github.com/zjunlp/knowlm บทนำ: โครงการ Knowlm มีจุดมุ่งหมายเพื่อเผยแพร่กรอบของแบบจำลองโอเพนซอร์สขนาดใหญ่และน้ำหนักโมเดลที่สอดคล้องกันเพื่อช่วยลดปัญหาการเข้าใจผิดความรู้รวมถึงความยากลำบากของความรู้เกี่ยวกับโมเดลขนาดใหญ่และข้อผิดพลาดและอคติที่อาจเกิดขึ้น ระยะแรกของโครงการเปิดตัวการสกัด Llama โดยใช้การวิเคราะห์ข่าวกรองแบบจำลองขนาดใหญ่โดยใช้คลังข้อมูลภาษาจีนและภาษาอังกฤษเพื่อฝึกอบรม Llama (13B) อย่างเต็มที่และเพิ่มประสิทธิภาพงานการสกัดความรู้ตามเทคโนโลยีการสอนการแปลงกราฟความรู้ เบย์ลิ่ง ที่อยู่: https://github.com/ictnlp/bayling บทนำ: โมเดลสากลขนาดใหญ่ที่มีการจัดแนวข้ามภาษาที่ได้รับการพัฒนาได้รับการพัฒนาโดยทีมงานการรักษาภาษาธรรมชาติของสถาบันเทคโนโลยีคอมพิวเตอร์ของสถาบันวิทยาศาสตร์แห่งจีน Bayling ใช้ Llama เป็นแบบจำลองพื้นฐานการสำรวจวิธีการปรับแต่งที่ดีด้วยงานการแปลแบบโต้ตอบเป็นแกนกลาง . ในการประเมินผลการแปลหลายภาษาการแปลแบบโต้ตอบงานสากลและการสอบมาตรฐาน Bai Ling แสดงประสิทธิภาพที่ดีขึ้นในภาษาจีน/อังกฤษ Bai Ling ให้การสาธิตเวอร์ชันออนไลน์เพื่อให้ทุกคนได้สัมผัส นูลันช์ ที่อยู่: https://github.com/ruc-gsai/yulan- แชท บทนำ: Yulan-Chat เป็นรูปแบบภาษาขนาดใหญ่ที่พัฒนาโดย Renmin University of China Gsai นักวิจัย มันได้รับการพัฒนาอย่างดีติดตั้งบนพื้นฐานของ Llama และมีคำแนะนำภาษาอังกฤษและภาษาจีนคุณภาพสูง Yulan-Chat สามารถแชทกับผู้ใช้ปฏิบัติตามคำแนะนำภาษาอังกฤษหรือภาษาจีนได้ดีและสามารถนำไปใช้กับ GPU (A800-80G หรือ RTX3090) หลังจากการหาปริมาณ polylm ที่อยู่: https://github.com/damo-nlp-mt/polylm บทนำสั้น ๆ : โมเดลหลายภาษาที่ผ่านการฝึกอบรมตั้งแต่ต้น 640 พันล้านคำรวมถึงขนาดของสองรุ่น (1.7b และ 13b) Polylm ครอบคลุมจีนอังกฤษรัสเซียตะวันตกฝรั่งเศสโปรตุเกสเยอรมันอิตาลีเขาโบโบโบอาชิฮีบรูญี่ปุ่นเกาหลีใต้ไทยเวียดนามอินโดนีเซียและประเภทอื่น ๆ โดยเฉพาะอย่างยิ่งเป็นมิตรกับภาษาเอเชีย Huozi ที่อยู่: https://github.com/hit-scir/huozi บทนำ: รูปแบบภาษาการฝึกอบรมขนาดใหญ่ขนาดใหญ่ของรูปแบบภาษาการฝึกอบรมขนาดใหญ่ขนาดใหญ่ที่พัฒนาโดยสถาบันวิจัยการบำบัดภาษาธรรมชาติฮาร์บิน โมเดลนี้ขึ้นอยู่กับโมเดลพารามิเตอร์ 7 พันล้านของโครงสร้าง Bloom ซึ่งรองรับภาษาจีนและภาษาอังกฤษสองภาษา ชุดข้อมูล ยาย ที่อยู่: https://github.com/weenge-research/yayi บทนำ: โมเดลที่สง่างามได้รับการปรับแต่งในข้อมูลภาคสนามคุณภาพสูงของสาขาที่มีคุณภาพสูงของโครงสร้างเทียมนับล้าน และการกำกับดูแลเมือง จากการทำซ้ำของการเริ่มต้นการฝึกอบรมก่อนการฝึกอบรมก่อนเราค่อยๆปรับปรุงความสามารถขั้นพื้นฐานของจีนและความสามารถในการวิเคราะห์ภาคสนามและเพิ่มบทสนทนาหลายรอบและความสามารถปลั๊กบางส่วน ในเวลาเดียวกันหลังจากการทดสอบภายในของผู้ใช้หลายร้อยคนการเพิ่มประสิทธิภาพการตอบกลับการป้อนกลับอย่างต่อเนื่องได้รับการปรับปรุงอย่างต่อเนื่องซึ่งปรับปรุงประสิทธิภาพของโมเดลและความปลอดภัยต่อไป โอเพ่นซอร์สของรูปแบบการเพิ่มประสิทธิภาพของจีนที่ใช้ Llama 2 สำรวจแนวทางปฏิบัติล่าสุดที่เหมาะสมสำหรับภารกิจจีนในหลายสาขาของจีน Yayi2 ที่อยู่: https://github.com/weenge-research/yayi2 บทนำ: Yayi 2 เป็นรุ่นใหม่ของแบบจำลองภาษาขนาดใหญ่โอเพนซอร์สที่พัฒนาโดย Zhongke Wenge รวมถึงรุ่นฐานและการแชทที่มีมาตราส่วนพารามิเตอร์ 30B Yayi2-30B เป็นแบบจำลองภาษาขนาดใหญ่ที่ใช้หม้อแปลงโดยใช้คลังข้อมูลคุณภาพสูงและหลายภาษาที่มีโทเค็นมากกว่า 2 ล้านล้านโทเค็นสำหรับการฝึกอบรมก่อน ในการตอบสนองต่อสถานการณ์แอปพลิเคชันโดยทั่วไปและพื้นที่เฉพาะเราได้ใช้คำแนะนำนับล้านเพื่อปรับค่าใช้จ่ายและในเวลาเดียวกันเราใช้ความคิดเห็นของมนุษย์เพื่อเสริมสร้างวิธีการเรียนรู้เพื่อจัดรูปแบบและค่านิยมของมนุษย์ให้ดีขึ้น โมเดลโอเพ่นซอร์สนี้เป็นรุ่นฐาน Yayi2-30b Yuan-2.0 ที่อยู่: https://github.com/ieit-yuan/yuan-2.0 บทนำ: โครงการเปิดให้รุ่นใหม่ของรูปแบบภาษาพื้นฐานที่ออกโดยข้อมูลของ Inspur และให้สคริปต์ที่เกี่ยวข้องสำหรับการฝึกอบรมล่วงหน้าการปรับแต่งและบริการให้เหตุผล Source 2.0 ขึ้นอยู่กับแหล่งที่มา 1.0 โดยใช้ข้อมูลการฝึกอบรมล่วงหน้าคุณภาพสูงและชุดข้อมูลการปรับแต่งเพื่อให้แบบจำลองมีความเข้าใจที่ดีขึ้นในความหมายคณิตศาสตร์การให้เหตุผลรหัสและความรู้ Chinese-Mixtral-8x7b ที่อยู่: https://github.com/hit-scir/chinese-mixtral-8x7b บทนำ: โครงการดำเนินการก่อนการฝึกอบรมตารางการขยายภาษาจีนโดยใช้โมเดลผู้เชี่ยวชาญแบบไฮบริดแบบผสมผสาน Mixtral-8x7b ประสิทธิภาพการเข้ารหัสของจีนของรุ่นนี้ดีขึ้นอย่างมีนัยสำคัญกว่ารุ่นดั้งเดิม ในเวลาเดียวกันผ่านการฝึกอบรมล่วงหน้าบนคลังข้อมูลโอเพนซอร์สขนาดใหญ่รุ่นนี้มีความสามารถในการสร้างและความเข้าใจในภาษาจีนที่แข็งแกร่ง Bluelm ที่อยู่: https: //github.com/vivo-jlab/bluelm บทนำ: Bluelm เป็นรูปแบบภาษาการฝึกอบรมขนาดใหญ่ที่พัฒนาขึ้นอย่างอิสระโดยสถาบันวิจัย Vivo AI Global Research (แชท) รุ่น ทัวริงมม. ที่อยู่: https://github.com/lightyear-turing/turingmm-34b- แชท บทนำ: Turingmm-34b-Chat เป็นรูปแบบการแชทแบบจีนและภาษาอังกฤษ . รูปแบบการปรับแต่งที่ดี นายพราน ที่อยู่: https://github.com/orionstarai/orion บทนำ: Orion-14b-base เป็นแบบจำลองหลายภาษาที่มีพารามิเตอร์ 14 พันล้านตัว Orionstar-yi-34b-chat ที่อยู่: https://github.com/orionstarai/orionstar- yi-34b-chaat บทนำ: Orionstar-Yi-34b-Chat เป็นรุ่น Yi-34B ที่ใช้สตาร์สตาร์สสเตจตามแหล่งที่มาของ 10,000 สิ่ง ประสบการณ์แบบโต้ตอบสำหรับผู้ใช้ชุมชนขนาดใหญ่ MINICPM เพิ่ม บทนำ: MINICPM เป็นชุดของแบบจำลองด้านข้างที่เปิดโดยทั่วไปโดย Noodle Wall Intelligence และ Tsinghua University Language Treating Language Laboratory ของพารามิเตอร์ Mengzi3 ที่อยู่: https://github.com/langboat/mengzi3 บทนำ: Mengzi3 8b/13b โมเดลขึ้นอยู่กับสถาปัตยกรรม Llama โดยมีการเลือกคลังข้อมูลจากหน้าเว็บ, สารานุกรม, โซเชียล, สื่อ, ข่าวและชุดข้อมูลโอเพ่นซอร์สคุณภาพสูง ด้วยการฝึกอบรมคลังข้อมูลหลายภาษาต่อเนื่องเกี่ยวกับโทเค็นล้านล้านโทเค็นความสามารถของจีนของแบบจำลองนั้นโดดเด่นและคำนึงถึงความสามารถหลายภาษา
1.2 รุ่น LLM Multifamily
2. 应用
2.1 垂直领域微调
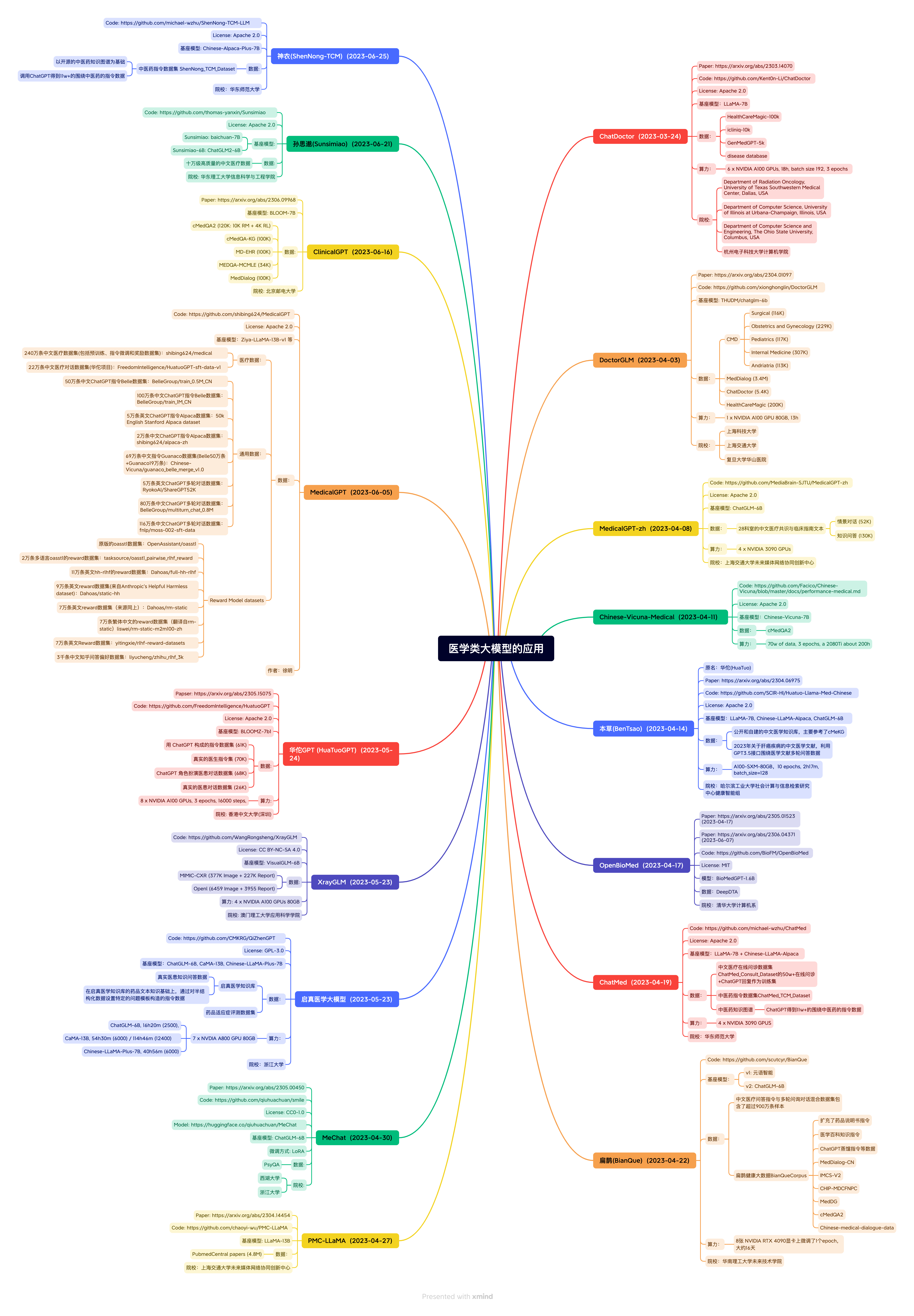
การรักษาพยาบาล
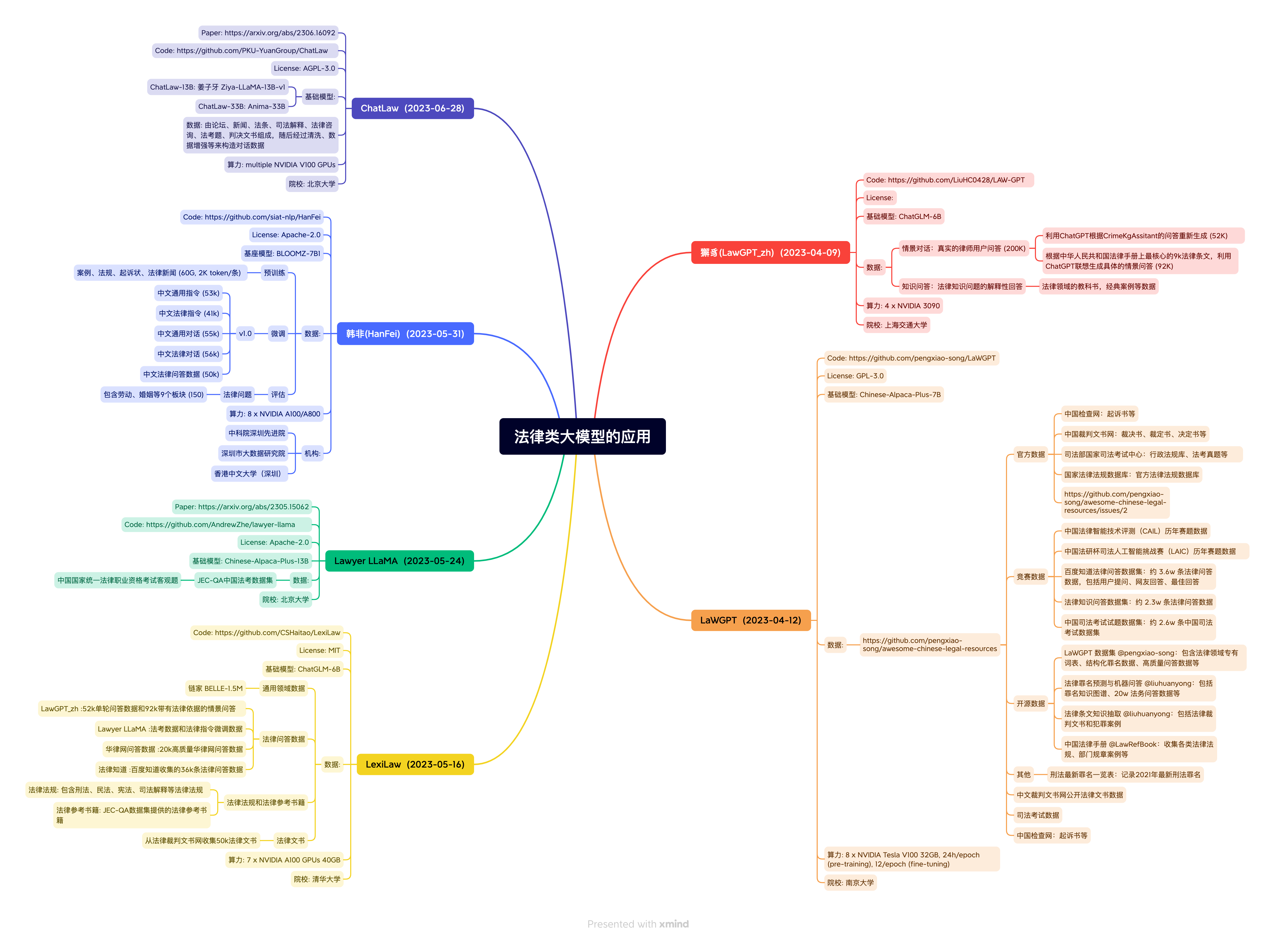
กฎ
การเงิน
ให้ความรู้ 桃李(Taoli):
地址:https://github.com/blcuicall/taoli 简介:一个在国际中文教育领域数据上进行了额外训练的模型。项目基于目前国际中文教育领域流通的500余册国际中文教育教材与教辅书、汉语水平考试试题以及汉语学习者词典等,构建了国际中文教育资源库,构造了共计88000 条的高质量国际中文教育问答数据集,并利用收集到的数据对模型进行指令微调,让模型习得将知识应用到具体场景中的能力。 EduChat:
地址:https://github.com/icalk-nlp/EduChat 简介:该项目华东师范大学计算机科学与技术学院的EduNLP团队研发,主要研究以预训练大模型为基底的教育对话大模型相关技术,融合多样化的教育垂直领域数据,辅以指令微调、价值观对齐等方法,提供教育场景下自动出题、作业批改、情感支持、课程辅导、高考咨询等丰富功能,服务于广大老师、学生和家长群体,助力实现因材施教、公平公正、富有温度的智能教育。 chatglm-maths:
地址:https://github.com/yongzhuo/chatglm-maths 简介:基于chatglm-6b微调/LORA/PPO/推理的数学题解题大模型, 样本为自动生成的整数/小数加减乘除运算, 可gpu/cpu部署,开源了训练数据集等。 MathGLM:
地址:https://github.com/THUDM/MathGLM 简介:该项目由THUDM研发,开源了多个能进行20亿参数可以进行准确多位算术运算的语言模型,同时开源了可用于算术运算微调的数据集。 QiaoBan:
地址:https://github.com/HIT-SCIR-SC/QiaoBan 简介:该项目旨在构建一个面向儿童情感陪伴的大模型,这个仓库包含:用于指令微调的对话数据/data,巧板的训练代码,训练配置文件,使用巧板进行对话的示例代码(TODO,checkpoint将发布至huggingface)。
วิทยาศาสตร์และเทคโนโลยี 天文大语言模型StarGLM:
地址:https://github.com/Yu-Yang-Li/StarGLM 简介:基于ChatGLM训练了天文大语言模型,以期缓解大语言模型在部分天文通用知识和前沿变星领域的幻觉现象,为接下来可处理天文多模态任务、部署于望远镜阵列的观测Agent——司天大脑(数据智能处理)打下基础。 TransGPT·致远:
地址:https://github.com/DUOMO/TransGPT 简介:开源交通大模型,主要致力于在真实交通行业中发挥实际价值。它能够实现交通情况预测、智能咨询助手、公共交通服务、交通规划设计、交通安全教育、协助管理、交通事故报告和分析、自动驾驶辅助系统等功能。 Mozi:
地址:https://github.com/gmftbyGMFTBY/science-llm 简介:该项目开源了基于LLaMA和Baichuan的科技论文大模型,可以用于科技文献的问答和情感支持。
e -commerce EcomGPT地址:https://github.com/Alibaba-NLP/EcomGPT 简介:一个由阿里发布的面向电商领域的语言模型,该模型基于BLOOMZ在电商指令微调数据集上微调得到,人工评估在12个电商评测数据集上超过ChatGPT。
网络安全 SecGPT地址:https://github.com/Clouditera/secgpt 简介:开项目开源了网络安全大模型,该模型基于Baichuan-13B采用Lora做预训练和SFT训练,此外该项目还开源了相关预训练和指令微调数据集等资源。
เกษตรกรรม 后稷(AgriMa):地址:https://github.com/zhiweihu1103/AgriMa 简介:首个中文开源农业大模型是由山西大学、山西农业大学与The Fin AI联合研发,以Baichuan为底座,基于海量有监督农业领域相关数据微调,具备广泛的农业知识和智能分析能力,该模型旨在为农业领域提供全面而高效的信息处理和决策支持。 稷丰(AgriAgent):地址:https://github.com/zhiweihu1103/AgriAgent 简介:首个开源中文农业多模态大模型是由山西农业大学研发,以MiniCPM-Llama3-V 2.5为底座,能够从图像、文本、气象数据等多源信息中提取有用信息,为农业生产提供全面、精准的智能化解决方案。我们致力于将稷丰应用于作物健康监测、病虫害识别、土壤肥力分析、农田管理优化等多个方面,帮助农民提升生产效率,减少资源浪费,促进农业的可持续发展。
2.2 LangChain应用
2.3 其他应用 wenda:
地址:https://github.com/wenda-LLM/wenda 简介:一个LLM调用平台。为小模型外挂知识库查找和设计自动执行动作,实现不亚于于大模型的生成能力。 JittorLLMs:
地址:https://github.com/Jittor/JittorLLMs 简介:计图大模型推理库:笔记本没有显卡也能跑大模型,具有成本低,支持广,可移植,速度快等优势。 LMFlow:
地址:https://github.com/OptimalScale/LMFlow 简介:LMFlow是香港科技大学LMFlow团队开发的大模型微调工具箱。LMFlow工具箱具有可扩展性强、高效、方便的特性。LMFlow仅使用180K条数据微调,即可得到在Huggingface榜单第一名的Robin模型。LMFlow支持用户快速训练个性化模型,仅需单张3090和5个小时即可微调70亿参数定制化模型。 fastllm:
地址:https://github.com/ztxz16/fastllm 简介:纯c++的全平台llm加速库,chatglm-6B级模型单卡可达10000+token / s,支持moss, chatglm, baichuan模型,手机端流畅运行。 WebCPM
地址:https://github.com/thunlp/WebCPM 简介:一个支持可交互网页搜索的中文大模型。 GPT Academic:
地址:https://github.com/binary-husky/gpt_academic 简介:为GPT/GLM提供图形交互界面,特别优化论文阅读润色体验,支持并行问询多种LLM模型,支持清华chatglm等本地模型。兼容复旦MOSS, llama, rwkv, 盘古等。 ChatALL:
地址:https://github.com/sunner/ChatALL 简介:ChatALL(中文名:齐叨)可以把一条指令同时发给多个AI,可以帮助用户发现最好的回答。 CreativeChatGLM:
地址:https://github.com/ypwhs/CreativeChatGLM 简介:可以使用修订和续写的功能来生成创意内容,可以使用“续写”按钮帮ChatGLM 想一个开头,并让它继续生成更多的内容,你可以使用“修订”按钮修改最后一句ChatGLM 的回复。 docker-llama2-chat:
地址:https://github.com/soulteary/docker-llama2-chat 简介:开源了一个只需要三步就可以上手LLaMA2的快速部署方案。 ChatGLM2-Voice-Cloning:
地址:https://github.com/KevinWang676/ChatGLM2-Voice-Cloning 简介:实现了一个可以和喜欢的角色沉浸式对话的应用,主要采用ChatGLM2+声音克隆+视频对话的技术。 Flappy
地址:https://github.com/pleisto/flappy 简介:一个产品级面向所有程序员的LLM SDK, LazyLLM
地址:https://github.com/LazyAGI/LazyLLM 简介:LazyLLM是一款低代码构建多Agent大模型应用的开发工具,协助开发者用极低的成本构建复杂的AI应用,并可以持续的迭代优化效果。LazyLLM提供了更为灵活的应用功能定制方式,并实现了一套轻量级网管机制来支持一键部署多Agent应用,支持流式输出,兼容多个Iaas平台,且支持对应用中的模型进行持续微调。 MemFree
地址:https://github.com/memfreeme/memfree 简介:MemFree 是一个开源的Hybrid AI 搜索引擎,可以同时对您的个人知识库(如书签、笔记、文档等)和互联网进行搜索, 为你提供最佳答案。MemFree 支持自托管的极速无服务器向量数据库,支持自托管的极速Local Embedding and Rerank Service,支持一键部署。
3. 数据集
预训练数据集 MNBVC
地址:https://github.com/esbatmop/MNBVC 数据集说明:超大规模中文语料集,不但包括主流文化,也包括各个小众文化甚至火星文的数据。MNBVC数据集包括新闻、作文、小说、书籍、杂志、论文、台词、帖子、wiki、古诗、歌词、商品介绍、笑话、糗事、聊天记录等一切形式的纯文本中文数据。数据均来源于互联网收集,且在持续更新中。 WuDaoCorporaText
地址:https://data.baai.ac.cn/details/WuDaoCorporaText 数据集说明:WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量数据集,用于支撑大模型训练研究。目前由文本、对话、图文对、视频文本对四部分组成,分别致力于构建微型语言世界、提炼对话核心规律、打破图文模态壁垒、建立视频文字关联,为大模型训练提供坚实的数据支撑。 CLUECorpus2020
地址:https://github.com/CLUEbenchmark/CLUECorpus2020 数据集说明:通过对Common Crawl的中文部分进行语料清洗,最终得到100GB的高质量中文预训练语料,可直接用于预训练、语言模型或语言生成任务以及专用于简体中文NLP任务的小词表。 WanJuan-1.0
地址:https://opendatalab.org.cn/WanJuan1.0 Data set description: The scholar · Wanjuan 1.0 is the first open source version of the scholar · Wanjuan multi -modal language library, including three parts: text data set, graphic data set, and video data set. The total amount of data exceeds 2TB . 目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。 seq-monkey-data
SFT数据集 RefGPT:基于RefGPT生成大量真实和定制的对话数据集
地址:https://github.com/DA-southampton/RedGPT 数据集说明:包括RefGPT-Fact和RefGPT-Code两部分,其中RefGPT-Fact给出了5万中文的关于事实性知识的多轮对话,RefGPT-Code给出了3.9万中文编程相关的多轮对话数据。 COIG
地址:https://huggingface.co/datasets/BAAI/COIG 数据集说明:维护了一套无害、有用且多样化的中文指令语料库,包括一个人工验证翻译的通用指令语料库、一个人工标注的考试指令语料库、一个人类价值对齐指令语料库、一个多轮反事实修正聊天语料库和一个leetcode 指令语料库。 generated_chat_0.4M:
地址:https://huggingface.co/datasets/BelleGroup/generated_chat_0.4M 数据集说明:包含约40万条由BELLE项目生成的个性化角色对话数据,包含角色介绍。但此数据集是由ChatGPT产生的,未经过严格校验,题目或解题过程可能包含错误。 alpaca_chinese_dataset:
地址:https://github.com/hikariming/alpaca_chinese_dataset 数据集说明:根据斯坦福开源的alpaca数据集进行中文翻译,并再制造一些对话数据 Alpaca-CoT:
地址:https://github.com/PhoebusSi/Alpaca-CoT Data set description: Unified rich IFT data (such as COT data, still expands continuously), multiple training efficiency methods (such as Lora, P-Tuning), and multiple LLMS, three interfaces on three levels to create convenient researchers LLM-IFT research แพลตฟอร์ม. pCLUE:
地址:https://github.com/CLUEbenchmark/pCLUE 数据集说明:基于提示的大规模预训练数据集,用于多任务学习和零样本学习。包括120万训练数据,73个Prompt,9个任务。 firefly-train-1.1M:
地址:https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M 数据集说明:23个常见的中文数据集,对于每个任务,由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为115万 BELLE-data-1.5M:
地址:https://github.com/LianjiaTech/BELLE/tree/main/data/1.5M 数据集说明:通过self-instruct生成,使用了中文种子任务,以及openai的text-davinci-003接口,涉及175个种子任务 Chinese Scientific Literature Dataset:
地址:https://github.com/ydli-ai/csl 数据集说明:中文科学文献数据集(CSL),包含396,209 篇中文核心期刊论文元信息(标题、摘要、关键词、学科、门类)以及简单的prompt Chinese medical dialogue data:
地址:https://github.com/Toyhom/Chinese-medical-dialogue-data 数据集说明:中文医疗对话数据集,包括:<Andriatria_男科> 94596个问答对<IM_内科> 220606个问答对<OAGD_妇产科> 183751个问答对<Oncology_肿瘤科> 75553个问答对<Pediatric_儿科> 101602个问答对<Surgical_外科> 115991个问答对总计792099个问答对。 Huatuo-26M:
地址:https://github.com/FreedomIntelligence/Huatuo-26M 数据集说明:Huatuo-26M 是一个中文医疗问答数据集,此数据集包含了超过2600万个高质量的医疗问答对,涵盖了各种疾病、症状、治疗方式、药品信息等多个方面。Huatuo-26M 是研究人员、开发者和企业为了提高医疗领域的人工智能应用,如聊天机器人、智能诊断系统等需要的重要资源。 Alpaca-GPT-4:
地址:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM 数据集说明:Alpaca-GPT-4 是一个使用self-instruct 技术,基于175 条中文种子任务和GPT-4 接口生成的50K 的指令微调数据集。 InstructionWild
地址:https://github.com/XueFuzhao/InstructionWild 数据集说明:InstructionWild 是一个从网络上收集自然指令并过滤之后使用自然指令结合ChatGPT 接口生成指令微调数据集的项目。主要的指令来源:Twitter、CookUp.AI、Github 和Discard。 ShareChat
地址:https://paratranz.cn/projects/6725 数据集说明:一个倡议大家一起翻译高质量ShareGPT 数据的项目。 项目介绍:清洗/构造/翻译中文的ChatGPT数据,推进国内AI的发展,人人可炼优质中文Chat 模型。本数据集为ChatGPT约九万个对话数据,由ShareGPT API获得(英文68000,中文11000条,其他各国语言)。项目所有数据最终将以CC0 协议并入Multilingual Share GPT 语料库。 Guanaco
地址:https://huggingface.co/datasets/JosephusCheung/GuanacoDataset 数据集说明:一个使用Self-Instruct 的主要包含中日英德的多语言指令微调数据集。 chatgpt-corpus
地址:https://github.com/PlexPt/chatgpt-corpus 数据集说明:开源了由ChatGPT3.5 生成的300万自问自答数据,包括多个领域,可用于用于训练大模型。 SmileConv
地址:https://github.com/qiuhuachuan/smile 数据集说明:数据集通过ChatGPT改写真实的心理互助QA为多轮的心理健康支持多轮对话(single-turn to multi-turn inclusive language expansion via ChatGPT),该数据集含有56k个多轮对话,其对话主题、词汇和篇章语义更加丰富多样,更加符合在长程多轮对话的应用场景。
偏好数据集
4. LLM训练微调框架
5. LLM推理部署框架
6. LLM评测 FlagEval (天秤)大模型评测体系及开放平台
地址:https://github.com/FlagOpen/FlagEval 简介:旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用AI方法实现对主观评测的辅助,大幅提升评测的效率和客观性。FlagEval (天秤)创新构建了“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界,可视化呈现评测结果。 C-Eval: 构造中文大模型的知识评估基准:
地址:https://github.com/SJTU-LIT/ceval 简介:构造了一个覆盖人文,社科,理工,其他专业四个大方向,52 个学科(微积分,线代…),从中学到大学研究生以及职业考试,一共13948 道题目的中文知识和推理型测试集。此外还给出了当前主流中文LLM的评测结果。 OpenCompass:
地址:https://github.com/InternLM/opencompass 简介:由上海AI实验室发布的面向大模型评测的一站式平台。主要特点包括:开源可复现;全面的能力维度:五大维度设计,提供50+ 个数据集约30 万题的的模型评测方案;丰富的模型支持:已支持20+ HuggingFace 及API 模型;分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测;多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板;灵活化拓展。 SuperCLUElyb: SuperCLUE琅琊榜
地址:https://github.com/CLUEbenchmark/SuperCLUElyb 简介:中文通用大模型匿名对战评价基准,这是一个中文通用大模型对战评价基准,它以众包的方式提供匿名、随机的对战。他们发布了初步的结果和基于Elo评级系统的排行榜。 GAOKAO-Bench:
地址:https://github.com/OpenLMLab/GAOKAO-Bench 简介:GAOKAO-bench是一个以中国高考题目为数据集,测评大模型语言理解能力、逻辑推理能力的测评框架,收集了2010-2022年全国高考卷的题目,其中包括1781道客观题和1030道主观题,构建起GAOKAO-bench的数据部分。 AGIEval:
地址:https://github.com/ruixiangcui/AGIEval 简介:由微软发布的一项新型基准测试,这项基准选取20种面向普通人类考生的官方、公开、高标准往常和资格考试,包括普通大学入学考试(中国高考和美国SAT 考试)、法学入学考试、数学竞赛、律师资格考试、国家公务员考试等等。 Xiezhi:
地址:https://github.com/mikegu721/xiezhibenchmark 简介:由复旦大学发布的一个综合的、多学科的、能够自动更新的领域知识评估Benchmark,包含了哲学、经济学、法学、教育学、文学、历史学、自然科学、工学、农学、医学、军事学、管理学、艺术学这13个学科门类,24万道学科题目,516个具体学科,249587道题目。 Open LLM Leaderboard:
地址:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard 简介:由HuggingFace组织的一个LLM评测榜单,目前已评估了较多主流的开源LLM模型。评估主要包括AI2 Reasoning Challenge, HellaSwag, MMLU, TruthfulQA四个数据集上的表现,主要以英文为主。 CMMLU:
地址:https://github.com/haonan-li/CMMLU 简介:CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用。因此是一个完全中国化的中文测试基准。 MMCU:
地址:https://github.com/Felixgithub2017/MMCU 简介:该项目提供对中文大模型语义理解能力的测试,评测方式、评测数据集、评测记录都公开,确保可以复现。该项目旨在帮助各位研究者们评测自己的模型性能,并验证训练策略是否有效。 chinese-llm-benchmark:
地址:https://github.com/jeinlee1991/chinese-llm-benchmark 简介:中文大模型能力评测榜单:覆盖百度文心一言、chatgpt、阿里通义千问、讯飞星火、belle / chatglm6b 等开源大模型,多维度能力评测。不仅提供能力评分排行榜,也提供所有模型的原始输出结果! Safety-Prompts:
地址:https://github.com/thu-coai/Safety-Prompts 简介:由清华大学提出的一个关于LLM安全评测benchmark,包括安全评测平台等,用于评测和提升大模型的安全性,囊括了多种典型的安全场景和指令攻击的prompt。 PromptCBLUE: 中文医疗场景的LLM评测基准
地址:https://github.com/michael-wzhu/PromptCBLUE 简介:为推动LLM在医疗领域的发展和落地,由华东师范大学联合阿里巴巴天池平台,复旦大学附属华山医院,东北大学,哈尔滨工业大学(深圳),鹏城实验室与同济大学推出PromptCBLUE评测基准, 将16种不同的医疗场景NLP任务全部转化为基于提示的语言生成任务,形成首个中文医疗场景的LLM评测基准。 HalluQA: 中文幻觉评估基准
地址:https://github.com/xiami2019/HalluQA 简介:该项目提出了一个名为HalluQA的基准测试,用于衡量中文大型语言模型中的幻觉现象。HalluQA包含450个精心设计的对抗性问题,涵盖多个领域,并考虑了中国历史文化、风俗和社会现象。在构建HalluQA时,考虑了两种类型的幻觉:模仿性虚假和事实错误,并基于GLM-130B和ChatGPT构建对抗性样本。为了评估,设计了一种使用GPT-4进行自动评估的方法,判断模型输出是否是幻觉。
7. LLM教程
LLM基础知识 HuggingLLM:
地址:https://github.com/datawhalechina/hugging-llm 简介:介绍ChatGPT 原理、使用和应用,降低使用门槛,让更多感兴趣的非NLP或算法专业人士能够无障碍使用LLM创造价值。 LLMsPracticalGuide:
เพิ่ม 简介:该项目提供了关于LLM的一系列指南与资源精选列表,包括LLM发展历程、原理、示例、论文等。
提示工程教程
LLM应用教程
LLM实战教程 LLMs九层妖塔:
地址:https://github.com/km1994/LLMsNineStoryDemonTower 简介:ChatGLM、Chinese-LLaMA-Alpaca、MiniGPT-4、FastChat、LLaMA、gpt4all等实战与经验。 llm-action:
地址:https://github.com/liguodongiot/llm-action 简介:该项目提供了一系列LLM实战的教程和代码,包括LLM的训练、推理、微调以及LLM生态相关的一些技术文章等。 llm大模型训练专栏:
地址:https://www.zhihu.com/column/c_1252604770952642560 简介:该项目提供了一系列LLM前言理论和实战实验,包括论文解读与洞察分析。 书生·浦语大模型实战营
地址:https://github.com/InternLM/tutorial 简介:该课程由上海人工智能实验室重磅推出。课程包括大模型微调、部署与评测全链路,目的是为广大开发者搭建大模型学习和实践开发的平台。
8. 相关仓库 FindTheChatGPTer:
地址:https://github.com/chenking2020/FindTheChatGPTer Introduction: ChatGPT burst into fire, which has opened a key step leading to AGI. This project aims to summarize the open source calories of those ChatGPTs, including large text models, multi -mode and large models, etc., providing some convenience for everyone . LLM_reviewer:
地址:https://github.com/SpartanBin/LLM_reviewer 简介:总结归纳近期井喷式发展的大语言模型,以开源、规模较小、可私有化部署、训练成本较低的'小羊驼类'模型为主。 Awesome-AITools:
地址:https://github.com/ikaijua/Awesome-AITools 简介:收藏整理了AI相关的实用工具、评测和相关文章。 open source ChatGPT and beyond:
地址:https://github.com/SunLemuria/open_source_chatgpt_list 简介:This repo aims at recording open source ChatGPT, and providing an overview of how to get involved, including: base models, technologies, data, domain models, training pipelines, speed up techniques, multi-language, multi-modal, and more to go. Awesome Totally Open Chatgpt:
地址:https://github.com/nichtdax/awesome-totally-open-chatgpt 简介:This repo record a list of totally open alternatives to ChatGPT. Awesome-LLM:
地址:https://github.com/Hannibal046/Awesome-LLM 简介:This repo is a curated list of papers about large language models, especially relating to ChatGPT. It also contains frameworks for LLM training, tools to deploy LLM, courses and tutorials about LLM and all publicly available LLM checkpoints and APIs. DecryptPrompt:
地址:https://github.com/DSXiangLi/DecryptPrompt 简介:总结了Prompt&LLM论文,开源数据&模型,AIGC应用。 Awesome Pretrained Chinese NLP Models:
地址:https://github.com/lonePatient/awesome-pretrained-chinese-nlp-models 简介:收集了目前网上公开的一些高质量中文预训练模型。 ChatPiXiu:
地址:https://github.com/catqaq/ChatPiXiu 简介:该项目旨在打造全面且实用的ChatGPT模型库和文档库。当前V1版本梳理了包括:相关资料调研+通用最小实现+领域/任务适配等。 LLM-Zoo:
地址:https://github.com/DAMO-NLP-SG/LLM-Zoo 简介:该项目收集了包括开源和闭源的LLM模型,具体包括了发布时间,模型大小,支持的语种,领域,训练数据及相应论文/仓库等。 LLMs-In-China:
地址:https://github.com/wgwang/LLMs-In-China 简介:该项目旨在记录中国大模型发展情况,同时持续深度分析开源开放的大模型以及数据集的情况。 BMList:
地址:https://github.com/OpenBMB/BMList 简介:该项目收集了参数量超过10亿的大模型,并梳理了各个大模型的适用模态、发布的机构、适合的语种,参数量和开源地址、API等信息。 awesome-free-chatgpt:
地址:https://github.com/LiLittleCat/awesome-free-chatgpt 简介:该项目收集了免费的ChatGPT 镜像网站列表,ChatGPT的替代方案,以及构建自己的ChatGPT的教程工具等。 Awesome-Domain-LLM:
地址:https://github.com/luban-agi/Awesome-Domain-LLM 简介:该项目收集和梳理垂直领域的开源模型、数据集及评测基准。
Star History