
การใช้งานอย่างเป็นทางการของ GFT ซึ่งเป็นโมเดล Cross-Domain Cross-Task Foundation บนกราฟ โลโก้ถูกสร้างขึ้นโดย Dall · E 3
เขียนโดย Zehong Wang, Zheyuan Zhang, Nitesh v Chawla, Chuxu Zhang และ Yanfang Ye
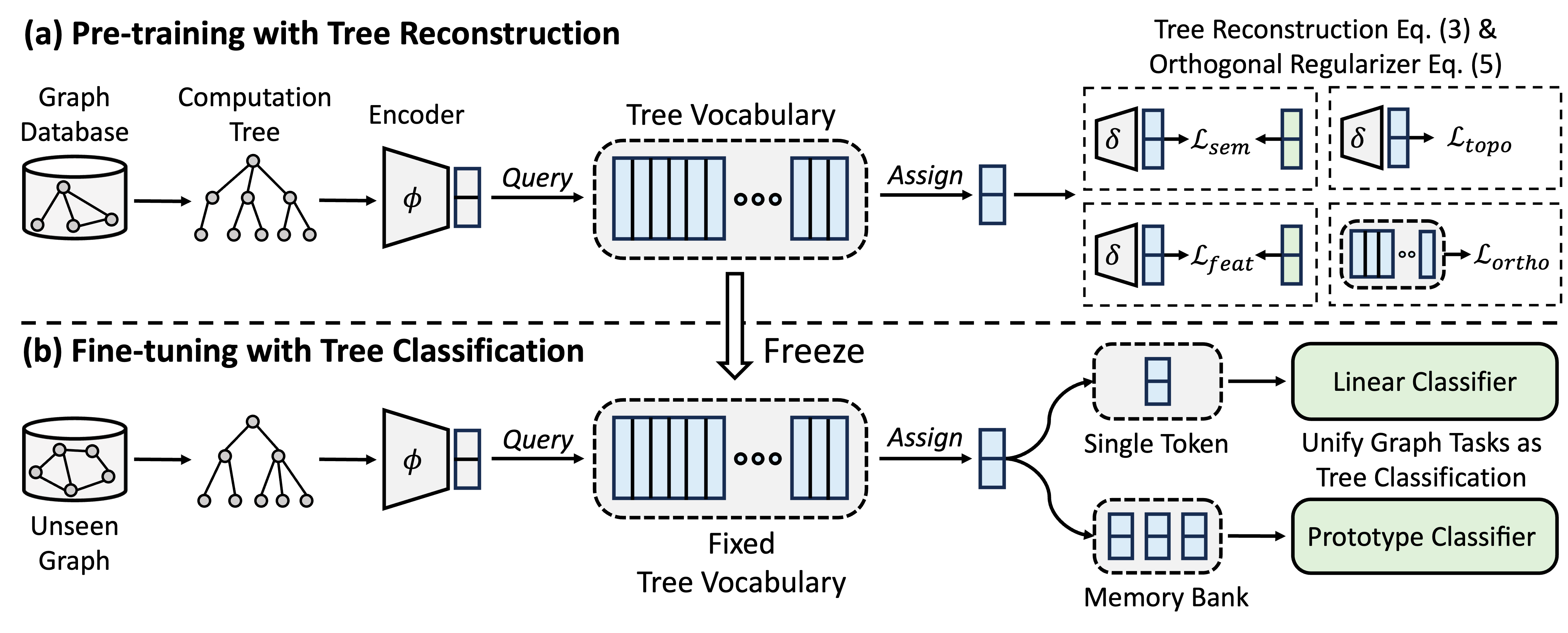
GFT เป็นโมเดลกราฟกราฟข้ามโดเมนและข้ามงานซึ่งถือว่าต้นไม้คำนวณเป็นรูปแบบที่สามารถถ่ายโอนได้เพื่อให้ได้คำศัพท์ต้นไม้ที่สามารถถ่ายโอนได้ ยิ่งไปกว่านั้น GFT ยังจัดให้มีเฟรมเวิร์กแบบครบวงจรในการจัดตำแหน่งงานที่เกี่ยวข้องกับกราฟเปิดใช้งานโมเดลกราฟเดียวเช่น GNN เพื่อร่วมกันจัดการงานระดับโหนดระดับขอบและระดับกราฟระดับ
ในระหว่างการฝึกอบรมล่วงหน้าโมเดลจะเข้ารหัสความรู้ทั่วไปจากฐานข้อมูลกราฟลงในคำศัพท์ต้นไม้ผ่านงานการสร้างต้นไม้ใหม่ ในการปรับแต่งคำศัพท์ต้นไม้ที่เรียนรู้จะถูกนำไปใช้เพื่อรวมงานที่เกี่ยวข้องกับกราฟเป็นงานการจำแนกต้นไม้โดยปรับความรู้ทั่วไปที่ได้มากับงานที่เฉพาะเจาะจง
คุณสามารถใช้ Conda เพื่อติดตั้งสภาพแวดล้อม โปรดเรียกใช้สคริปต์ต่อไปนี้ เราเรียกใช้การทดลองทั้งหมดใน GPU A40 48G เดียว แต่ GPU ที่มีหน่วยความจำ 24G นั้นเพียงพอที่จะจัดการชุดข้อมูลทั้งหมดด้วยมินิแบทช์
conda env create -f environment.yml
conda activate GFT
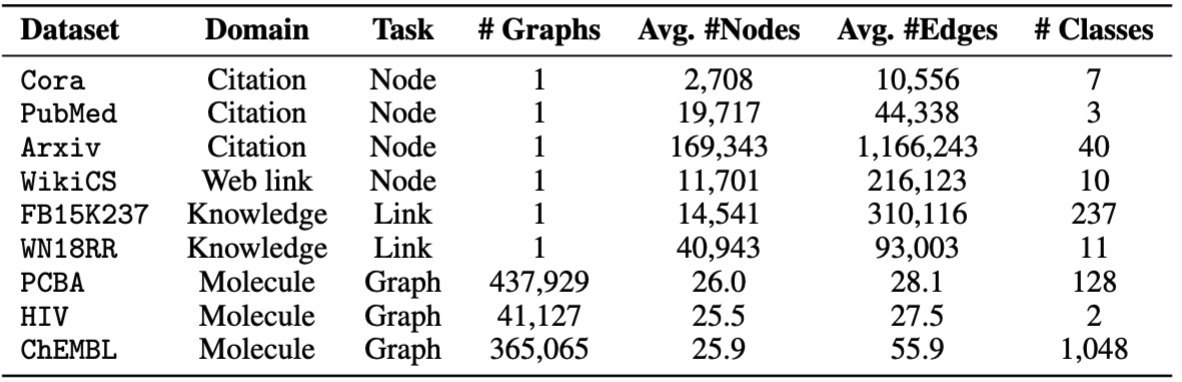
เราใช้ชุดข้อมูลที่จัดทำโดย OFA คุณสามารถเรียกใช้ pretrain.py เพื่อดาวน์โหลดชุดข้อมูลโดยอัตโนมัติซึ่งจะดาวน์โหลดไปยัง /data ตามค่าเริ่มต้น ไปป์ไลน์จะทำการประมวลผลชุดข้อมูลล่วงหน้าโดยอัตโนมัติโดยการแปลงคำอธิบายข้อความเป็น embeddings ข้อความ
หรือคุณสามารถดาวน์โหลดชุดข้อมูลที่ประมวลผลล่วงหน้าของเราและคลายซิปบนโฟลเดอร์ /data
รหัสของ GFT ถูกนำเสนอในโฟลเดอร์ /GFT โครงสร้างมีดังนี้
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
คุณสามารถเรียกใช้ pretrain.py สำหรับการเตรียมการบนกราฟที่หลากหลายและ finetune.py สำหรับการปรับตัวให้เข้ากับงานดาวน์สตรีมบางอย่างด้วย finetuning ขั้นพื้นฐานหรือการเรียนรู้ไม่กี่นัด
ในการทำซ้ำผลลัพธ์เราได้จัดเตรียมพารามิเตอร์ไฮเปอร์อย่างละเอียดสำหรับทั้ง pretraining และ finetuning เก็บรักษาไว้ใน config/pretrain.yaml และ config/finetune.yaml ตามลำดับ ในการใช้ประโยชน์จากพารามิเตอร์ไฮเปอร์เริ่มต้นเราได้จัดเตรียมคำสั่ง --use_params สำหรับทั้ง pretrain และ finetune
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
สำหรับ Finetuning เรามีชุดข้อมูลแปดชุด ได้แก่ cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv และ chempcba
หรือคุณสามารถเรียกใช้สคริปต์เพื่อทำซ้ำการทดลอง
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
หมายเหตุ: โมเดล pretrained จะถูกเก็บไว้ใน ckpts/pretrain_model/ โดยค่าเริ่มต้น
# The basic command for pretraining GFT
python GFT/pretrain.py
เมื่อคุณเรียกใช้ pretrain.py คุณสามารถปรับแต่งชุดข้อมูล pretraining และพารามิเตอร์ไฮเปอร์
คุณสามารถใช้ --pretrain_dataset (หรือ --pt_data ) เพื่อตั้งค่าชุดข้อมูล pretrain ที่ใช้แล้วและน้ำหนักที่สอดคล้องกัน การกำหนดค่าข้อมูลที่กำหนดไว้ล่วงหน้าอยู่ใน config/pt_data.yaml พร้อมโครงสร้างต่อไปนี้
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
ในกรณีข้างต้น all คือชื่อของการตั้งค่าหมายถึงชุดข้อมูลทั้งหมดที่ใช้ในการเตรียมการ สำหรับแต่ละชุดข้อมูลมีคู่คีย์-ค่าซึ่งคีย์คือชื่อชุดข้อมูลและค่าคือน้ำหนักการสุ่มตัวอย่าง ตัวอย่างเช่น cora: 5 หมายถึงชุดข้อมูล cora จะถูกสุ่มตัวอย่าง 5 ครั้งในยุคเดียว คุณสามารถออกแบบชุดข้อมูลของคุณเองสำหรับการเตรียม GFT
คุณสามารถปรับแต่งขั้นตอนการเตรียมการโดยการเปลี่ยนพารามิเตอร์ไฮเปอร์ของตัวเข้ารหัสปริมาณเวกเตอร์การฝึกอบรมแบบจำลอง
--pretrain_dataset : ระบุชุดข้อมูล pretraining เช่นเดียวกับข้างต้น--use_params : ใช้พารามิเตอร์ไฮเปอร์ที่กำหนดไว้ล่วงหน้า--seed : เมล็ดพันธุ์ที่ใช้สำหรับการผ่าตัด--hidden_dim : ขนาดในเลเยอร์ที่ซ่อนอยู่ของ GNNS--num_layers : เลเยอร์ GNN--activation : ฟังก์ชั่นการเปิดใช้งาน--backbone : กระดูกสันหลัง gnn--normalize : เลเยอร์การทำให้เป็นมาตรฐาน--dropout : การออกกลางคันของเลเยอร์ GNN--code_dim : ขนาดของแต่ละรหัสในคำศัพท์--codebook_size : จำนวนรหัสในคำศัพท์--codebook_head : จำนวนหัวของ codebook หากตัวเลขมีขนาดใหญ่กว่า 1 คุณจะใช้คำศัพท์หลายคำร่วมกัน--codebook_decay : อัตราการสลายตัวของรหัส--commit_weight : น้ำหนักของเงื่อนไขความมุ่งมั่น--pretrain_epochs : จำนวนยุค--pretrain_lr : อัตราการเรียนรู้--pretrain_weight_decay : น้ำหนักของ L2 ปกติ--pretrain_batch_size : ขนาดแบทช์--feat_p : อัตราการทุจริตคุณลักษณะ--edge_p : อัตราการทุจริตขอบ/โครงสร้าง--topo_recon_ratio : อัตราส่วนของขอบควรถูกสร้างขึ้นใหม่--feat_lambda : น้ำหนักของการสูญเสียคุณสมบัติ--topo_lambda : น้ำหนักของการสูญเสียโทโพโลยี--topo_sem_lambda : น้ำหนักของการสูญเสียโทโพโลยีในคุณสมบัติขอบการสร้างใหม่--sem_lambda : น้ำหนักของการสูญเสียความหมาย--sem_encoder_decay : อัตราการอัปเดตโมเมนตัมสำหรับตัวเข้ารหัสความหมาย # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
คุณสามารถตั้ง --dataset เพื่อระบุชุดข้อมูลดาวน์สตรีมและ --use_params เพื่อใช้พารามิเตอร์ไฮเปอร์ที่กำหนดไว้ล่วงหน้าสำหรับแต่ละชุดข้อมูล พารามิเตอร์ไฮเปอร์อื่น ๆ ที่คุณสามารถระบุได้จะถูกนำเสนอดังนี้
สำหรับกราฟที่มีการแยกที่กำหนดไว้ล่วงหน้า 1 ครั้งคุณสามารถตั้งค่า --repeat เพื่อทำการทดลองหลายครั้ง
--hidden_dim : ขนาดในเลเยอร์ที่ซ่อนอยู่ของ GNNS--num_layers : เลเยอร์ GNN--activation : ฟังก์ชั่นการเปิดใช้งาน--backbone : กระดูกสันหลัง gnn--normalize : เลเยอร์การทำให้เป็นมาตรฐาน--dropout : การออกกลางคันของเลเยอร์ GNN--code_dim : ขนาดของแต่ละรหัสในคำศัพท์--codebook_size : จำนวนรหัสในคำศัพท์--codebook_head : จำนวนหัวของ codebook หากตัวเลขมีขนาดใหญ่กว่า 1 คุณจะใช้คำศัพท์หลายคำร่วมกัน--codebook_decay : อัตราการสลายตัวของรหัส--commit_weight : น้ำหนักของเงื่อนไขความมุ่งมั่น--finetune_epochs : จำนวนยุค--finetune_lr : อัตราการเรียนรู้--early_stop : Epoch หยุดเร็วสูงสุด--batch_size : หากตั้งค่าเป็น 0 ให้ทำการฝึกกราฟเต็มรูปแบบ --lambda_proto : น้ำหนักของตัวจําแนกต้นแบบใน finetuning
--lambda_act : น้ำหนักของตัวจําแนกเชิงเส้นใน finetuning
--trade_off : การแลกเปลี่ยนระหว่างการใช้เครื่องคลาสสิกต้นแบบหรือการใช้ตัวจําแนกเชิงเส้นในการอนุมาน
คุณสามารถเพิ่ม --no_lin_clf หรือ --no_proto_clf เพื่อหลีกเลี่ยงการใช้ตัวจําแนกเชิงเส้นหรือตัวจําแนกต้นแบบตามลำดับ หมายเหตุคำสองคำนี้มีความขัดแย้งเนื่องจากคุณต้องใช้ตัวจําแนกอย่างน้อยหนึ่งตัว
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
คุณสามารถตั้ง --dataset เพื่อระบุชุดข้อมูลดาวน์สตรีมและ --use_params เพื่อใช้พารามิเตอร์ไฮเปอร์ที่กำหนดไว้ล่วงหน้าสำหรับแต่ละชุดข้อมูล พารามิเตอร์ไฮเปอร์อื่น ๆ ที่คุณสามารถระบุได้จะถูกนำเสนอดังนี้
พารามิเตอร์ไฮเปอร์ที่ทุ่มเทสำหรับการเรียนรู้ไม่กี่ครั้งคือ
--n_train : จำนวนอินสแตนซ์การฝึกอบรมต่อคลาสสำหรับการปรับรูปแบบ โปรดทราบว่า n_train ขนาดเล็กบรรลุประสิทธิภาพที่ต้องการ --n_task : จำนวนงานตัวอย่าง--n_way : จำนวนวิธี--n_query : ขนาดของชุดคิวรีต่อวิธี--n_shot : ขนาดของชุดสนับสนุนต่อวิธี--hidden_dim : ขนาดในเลเยอร์ที่ซ่อนอยู่ของ GNNS--num_layers : เลเยอร์ GNN--activation : ฟังก์ชั่นการเปิดใช้งาน--backbone : กระดูกสันหลัง gnn--normalize : เลเยอร์การทำให้เป็นมาตรฐาน--dropout : การออกกลางคันของเลเยอร์ GNN--code_dim : ขนาดของแต่ละรหัสในคำศัพท์--codebook_size : จำนวนรหัสในคำศัพท์--codebook_head : จำนวนหัวของ codebook หากตัวเลขมีขนาดใหญ่กว่า 1 คุณจะใช้คำศัพท์หลายคำร่วมกัน--codebook_decay : อัตราการสลายตัวของรหัส--commit_weight : น้ำหนักของเงื่อนไขความมุ่งมั่น--finetune_epochs : จำนวนยุค--finetune_lr : อัตราการเรียนรู้--early_stop : Epoch หยุดเร็วสูงสุด--batch_size : หากตั้งค่าเป็น 0 ให้ทำการฝึกกราฟเต็มรูปแบบ --lambda_proto : น้ำหนักของตัวจําแนกต้นแบบใน finetuning
--lambda_act : น้ำหนักของตัวจําแนกเชิงเส้นใน finetuning
--trade_off : การแลกเปลี่ยนระหว่างการใช้เครื่องคลาสสิกต้นแบบหรือการใช้ตัวจําแนกเชิงเส้นในการอนุมาน
คุณสามารถเพิ่ม --no_lin_clf หรือ --no_proto_clf เพื่อหลีกเลี่ยงการใช้ตัวจําแนกเชิงเส้นหรือตัวจําแนกต้นแบบตามลำดับ หมายเหตุคำสองคำนี้มีความขัดแย้งเนื่องจากคุณต้องใช้ตัวจําแนกอย่างน้อยหนึ่งตัว
ผลการทดลองอาจแตกต่างกันไปเนื่องจากการเริ่มต้นแบบสุ่มในระหว่างการผ่าตัด เราให้ผลการทดลองโดยใช้เมล็ดสุ่มที่แตกต่างกัน (เช่น 1-5) ในการเตรียมการเพื่อแสดงผลกระทบที่อาจเกิดขึ้นจากการเริ่มต้นแบบสุ่ม
| คอร่า | PubMed | wiki-cs | arxiv | WN18RR | FB15K237 | เอชไอวี | PCBA | เฉลี่ย | |
|---|---|---|---|---|---|---|---|---|---|
| เมล็ด = 1 | 78.58 ± 0.90 | 77.55 ± 1.54 | 79.38 ± 0.57 | 72.24 ± 0.16 | 91.56 ± 0.33 | 89.67 ± 0.35 | 72.69 ± 1.93 | 78.24 ± 0.23 | 79.99 |
| เมล็ด = 2 | 78.27 ± 1.26 | 76.41 ± 1.36 | 79.36 ± 0.62 | 72.13 ± 0.24 | 91.72 ± 0.19 | 89.66 ± 0.31 | 71.62 ± 2.45 | 78.20 ± 0.33 | 79.67 |
| เมล็ด = 3 | 78.16 ± 1.62 | 76.28 ± 1.37 | 79.32 ± 0.65 | 72.13 ± 0.30 | 91.57 ± 0.44 | 89.78 ± 0.23 | 71.58 ± 2.28 | 78.12 ± 0.37 | 79.62 |
| เมล็ด = 4 | 78.42 ± 1.37 | 75.76 ± 1.58 | 79.44 ± 0.62 | 72.36 ± 0.34 | 91.70 ± 0.24 | 89.73 ± 0.21 | 72.57 ± 2.46 | 78.34 ± 0.27 | 79.79 |
| เมล็ด = 5 | 78.56 ± 1.62 | 76.49 ± 2.00 | 79.27 ± 0.55 | 72.18 ± 0.26 | 91.47 ± 0.39 | 89.80 ± 0.19 | 72.27 ± 0.93 | 78.31 ± 0.34 | 79.79 |
| รายงาน | 78.62 ± 1.21 | 77.19 ± 1.99 | 79.39 ± 0.42 | 71.93 ± 0.12 | 91.91 ± 0.34 | 89.72 ± 0.20 | 72.67 ± 1.38 | 77.90 ± 0.64 | 79.92 |
เพื่อให้มั่นใจว่าการทำซ้ำได้ดีขึ้นเราได้จัดเตรียมจุดตรวจของ เมล็ด = 1 ในลิงค์นี้ เราเลือกสิ่งนี้เนื่องจากประสิทธิภาพเฉลี่ยที่ดีที่สุด คุณสามารถคลายซิปไฟล์ที่ดาวน์โหลดได้ในเส้นทาง ckpts/pretrain_model/ และตั้งค่า --pt_seed 1 เมื่อใช้ finetune.py เพื่อใช้ประโยชน์จากจุดตรวจสอบของเราอย่างประณีต
กรุณาติดต่อ [email protected] หรือเปิดปัญหาหากคุณมีคำถาม
หากคุณพบว่า repo มีประโยชน์สำหรับการวิจัยของคุณโปรดอ้างอิงกระดาษต้นฉบับอย่างถูกต้อง
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}ที่เก็บนี้ขึ้นอยู่กับ codebase ของ OFA, PYG, OGB และ VQ ขอบคุณสำหรับการแบ่งปัน!


