vision_transformer
1.0.0
ในที่เก็บนี้เราปล่อยโมเดลจากเอกสาร
แบบจำลองได้รับการฝึกอบรมล่วงหน้าบนชุดข้อมูล Imagenet และ Imagenet-21K เราให้รหัสสำหรับการปรับแต่งรุ่นที่ปล่อยออกมาใน Jax/Flax
แบบจำลองจาก codebase นี้ได้รับการฝึกฝนใน https://github.com/google-research/big_vision/ ซึ่งคุณสามารถค้นหารหัสขั้นสูงเพิ่มเติม (เช่นการฝึกอบรมหลายโฮสต์) รวมถึงสคริปต์การฝึกอบรมดั้งเดิม /vit_i21k.py สำหรับการฝึกอบรมล่วงหน้า A VIT หรือ configs/transfer.py สำหรับการถ่ายโอนโมเดล)
สารบัญ:
ด้านล่าง colabs ทำงานทั้งด้วย GPU และ TPUs (8 คอร์, ข้อมูลขนานข้อมูล)
colab แรกแสดงให้เห็นถึงรหัส JAX ของหม้อแปลงวิสัยทัศน์และมิกเตอร์ MLP colab นี้ช่วยให้คุณสามารถแก้ไขไฟล์จากที่เก็บโดยตรงใน Colab UI และมีเซลล์ colab ที่มีคำอธิบายประกอบที่นำคุณผ่านรหัสทีละขั้นตอนและให้คุณโต้ตอบกับข้อมูล
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
colab ที่สองช่วยให้คุณสำรวจหม้อแปลงไฟฟ้า> 50K และจุดตรวจไฮบริดที่ใช้ในการสร้างข้อมูลของกระดาษที่สาม "วิธีการฝึกอบรม VIT ของคุณ? ... " colab รวมรหัสในการสำรวจและเลือกจุดตรวจสอบและการอนุมานทั้งสองโดยใช้รหัส JAX จาก repo นี้และใช้ไลบรารี timm Pytorch ยอดนิยมที่สามารถโหลดจุดตรวจเหล่านี้ได้โดยตรงเช่นกัน โปรดทราบว่ามีแบบจำลองจำนวนหนึ่งมีให้บริการโดยตรงจาก TF-Hub: Sayakpaul/Collections/Vision_Transformer (การสนับสนุนภายนอกโดย Sayak Paul)
colab ที่สองยังช่วยให้คุณปรับจุดตรวจสอบในชุดข้อมูล TFDS และชุดข้อมูลของคุณเองพร้อมตัวอย่างในไฟล์ JPEG แต่ละไฟล์ (เลือกอ่านโดยตรงจาก Google Drive)
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax_augreg.ipynb
หมายเหตุ : สำหรับตอนนี้ (6/20/21) Google Colab รองรับ GPU เดียว (Nvidia tesla T4) และ TPU (ปัจจุบัน TPUV2-8) ติดอยู่กับ colab VM และสื่อสารผ่านเครือข่ายที่ช้าซึ่งนำไปสู่ความสวยงาม ความเร็วในการฝึกซ้อมที่ไม่ดี โดยปกติคุณจะต้องการตั้งค่าเครื่องเฉพาะหากคุณมีข้อมูลจำนวนไม่น่าสนใจเพื่อปรับแต่ง สำหรับรายละเอียดโปรดดูที่ส่วนที่กำลังดำเนินอยู่บนคลาวด์
ตรวจสอบให้แน่ใจว่าคุณติดตั้ง Python>=3.10 บนเครื่องของคุณ
ติดตั้งการพึ่งพา Jax และ Python โดยใช้งาน:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
สำหรับ JAX รุ่นใหม่ให้ทำตามคำแนะนำที่ให้ไว้ในที่เก็บข้อมูลที่เชื่อมโยงที่นี่ โปรดทราบว่าคำแนะนำการติดตั้งสำหรับ CPU, GPU และ TPU นั้นแตกต่างกันเล็กน้อย
ติดตั้ง Flaxformer ทำตามคำแนะนำที่ให้ไว้ในที่เก็บข้อมูลที่เชื่อมโยงที่นี่
สำหรับรายละเอียดเพิ่มเติมอ้างอิงส่วนที่ทำงานบนคลาวด์ด้านล่าง
คุณสามารถใช้การปรับแต่งรุ่นที่ดาวน์โหลดได้อย่างละเอียดในชุดข้อมูลที่คุณสนใจ ทุกรุ่นแชร์อินเทอร์เฟซบรรทัดคำสั่งเดียวกัน
ตัวอย่างเช่นสำหรับการปรับแต่ง VIT-B/16 (ได้รับการฝึกอบรมล่วงหน้าบน ImageNet21K) บน CIFAR10 (หมายเหตุว่าเราระบุ b16,cifar10 เป็นอาร์กิวเมนต์ในการกำหนดค่าอย่างไร แทนที่จะดาวน์โหลดครั้งแรกลงในไดเรกทอรีท้องถิ่น):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'เพื่อปรับแต่ง Mixer-B/16 (ได้รับการฝึกอบรมล่วงหน้าบน ImageNet21K) บน CIFAR10:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' กระดาษ "How to Train Your VIT? ... " เพิ่มจุดตรวจสอบ 50K ที่คุณสามารถปรับแต่งกับ configs/augreg.py config เมื่อคุณระบุชื่อรุ่นเท่านั้น (ค่า config.name จาก configs/model.py ) จากนั้นจุดตรวจสอบ I21K ที่ดีที่สุดโดยความแม่นยำในการตรวจสอบความถูกต้องของต้นน้ำ ("จุดตรวจสอบ" ที่แนะนำ "ดูหัวข้อ 4.5 ของกระดาษ) ถูกเลือก ในการตัดสินใจว่าคุณต้องการใช้รุ่นใดให้ดูรูปที่ 3 ในกระดาษ นอกจากนี้ยังเป็นไปได้ที่จะเลือกจุดตรวจสอบที่แตกต่างกัน (ดู colab vit_jax_augreg.ipynb ) จากนั้นระบุค่าจากคอลัมน์ filename หรือ adapt_filename ซึ่งสอดคล้องกับชื่อไฟล์ที่ไม่มี .npz จากไดเรกทอรี gs://vit_models/augreg
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 ปัจจุบันรหัสจะดาวน์โหลดชุดข้อมูล CIFAR-10 และ CIFAR-100 โดยอัตโนมัติ ชุดข้อมูลสาธารณะหรือที่กำหนดเองอื่น ๆ สามารถรวมเข้าด้วยกันได้อย่างง่ายดายโดยใช้ไลบรารีชุดข้อมูล TensorFlow โปรดทราบว่าคุณจะต้องอัปเดต vit_jax/input_pipeline.py เพื่อระบุพารามิเตอร์บางอย่างเกี่ยวกับชุดข้อมูลที่เพิ่มเข้ามา
โปรดทราบว่ารหัสของเราใช้ GPU/TPU ที่มีอยู่ทั้งหมดสำหรับการปรับแต่ง
หากต้องการดูรายการโดยละเอียดของธงที่มีอยู่ทั้งหมดให้เรียกใช้ python3 -m vit_jax.train --help
หมายเหตุเกี่ยวกับหน่วยความจำ:
--config.accum_steps=8 อีกทางเลือกหนึ่งคุณสามารถลด --config.batch=512 (และลดลง --config.base_lr )--config.shuffle_buffer=50000 โดย Alexey Dosovitskiy*†, Lucas Beyer*, Alexander Kolesnikov*, Dirk Weissenborn*, Xiaohua Zhai*, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly
(*) การมีส่วนร่วมทางเทคนิคที่เท่าเทียมกัน (†) การให้คำปรึกษาที่เท่าเทียมกัน
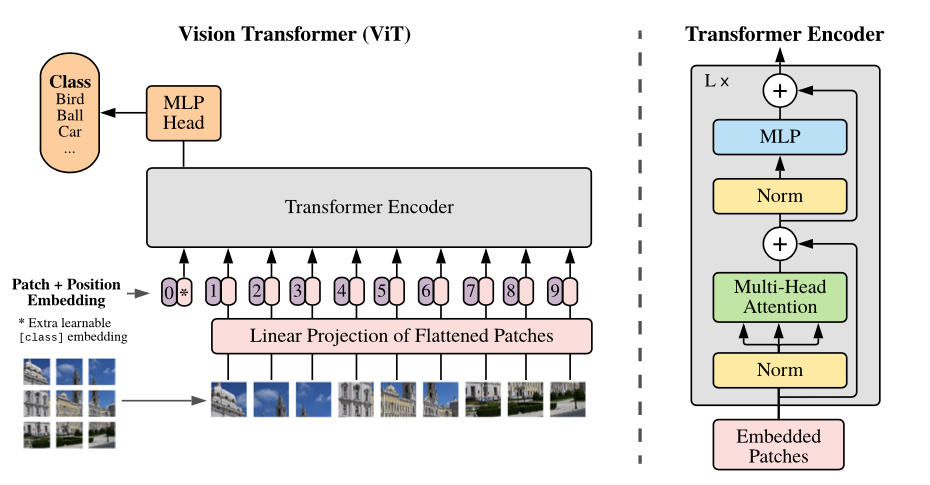
ภาพรวมของโมเดล: เราแบ่งภาพออกเป็นแพตช์ขนาดคงที่ฝังแต่ละของพวกเขาเพิ่มตำแหน่งฝังตำแหน่งและป้อนลำดับของเวกเตอร์ที่ได้ลงในตัวเข้ารหัสหม้อแปลงมาตรฐาน เพื่อดำเนินการจำแนกประเภทเราใช้วิธีการมาตรฐานในการเพิ่ม "โทเค็นการจำแนกประเภท" ที่เรียนรู้ได้เป็นพิเศษในลำดับ
เรามีแบบจำลอง VIT ที่หลากหลายในถัง GCS ที่แตกต่างกัน รุ่นสามารถดาวน์โหลดได้เช่น:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
ชื่อไฟล์โมเดล (ไม่มีส่วนขยาย .npz ) สอดคล้องกับ config.model_name ใน vit_jax/configs/models.py
gs://vit_models/imagenet21k รุ่นที่ผ่านการฝึกอบรมล่วงหน้าบน ImageNet-21Kgs://vit_models/imagenet21k+imagenet2012 รุ่นที่ผ่านการฝึกอบรมล่วงหน้าบน ImageNet-21K และปรับแต่งบน Imagenetgs://vit_models/augreg รุ่นที่ผ่านการฝึกอบรมล่วงหน้าบน ImageNet-21K โดยใช้ AUGREG ในปริมาณที่แตกต่างกัน ปรับปรุงประสิทธิภาพgs://vit_models/sam - รุ่นที่ผ่านการฝึกอบรมล่วงหน้าบน Imagenet กับ SAMgs://vit_models/gsam - รุ่นที่ผ่านการฝึกอบรมล่วงหน้าเกี่ยวกับ Imagenet ด้วย GSAMเราขอแนะนำให้ใช้จุดตรวจสอบต่อไปนี้ได้รับการฝึกฝนกับ AUGREG ที่มีตัวชี้วัดก่อนการฝึกอบรมที่ดีที่สุด:
| แบบอย่าง | จุดตรวจสอบที่ผ่านการฝึกอบรมมาก่อน | ขนาด | จุดตรวจสอบที่ปรับแต่ง | ปณิธาน | img/sec | ความแม่นยำของ ImageNet |
|---|---|---|---|---|---|---|
| l/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85.59% |
| b/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85.49% |
| s/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83.73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85.99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 Mib | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83.85% |
| ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78.22% |
| b/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83.59% |
| s/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79.58% |
| r+ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 Mib | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75.40% |
ผลลัพธ์จากกระดาษ VIT ต้นฉบับ (https://arxiv.org/abs/2010.11929) ได้รับการทำซ้ำโดยใช้แบบจำลองจาก gs://vit_models/imagenet21k :
| แบบอย่าง | ชุดข้อมูล | Dropout = 0.0 | Dropout = 0.1 |
|---|---|---|---|
| R50+VIT-B_16 | CIFAR10 | 98.72%, 3.9H (A100), TB.DEV | 98.94%, 10.1h (v100), tb.dev |
| R50+VIT-B_16 | CIFAR100 | 90.88%, 4.1h (A100), tb.dev | 92.30%, 10.1h (v100), tb.dev |
| R50+VIT-B_16 | ImageNet2012 | 83.72%, 9.9H (A100), TB.Dev | 85.08%, 24.2H (V100), TB.Dev |
| vit-b_16 | CIFAR10 | 99.02%, 2.2H (A100), TB.DEV | 98.76%, 7.8H (V100), TB.Dev |
| vit-b_16 | CIFAR100 | 92.06%, 2.2h (A100), TB.Dev | 91.92%, 7.8H (V100), TB.Dev |
| vit-b_16 | ImageNet2012 | 84.53%, 6.5h (A100), tb.dev | 84.12%, 19.3H (V100), TB.Dev |
| vit-b_32 | CIFAR10 | 98.88%, 0.8H (A100), TB.DEV | 98.75%, 1.8H (V100), TB.DEV |
| vit-b_32 | CIFAR100 | 92.31%, 0.8H (A100), TB.DEV | 92.05%, 1.8H (V100), TB.DEV |
| vit-b_32 | ImageNet2012 | 81.66%, 3.3H (A100), TB.DEV | 81.31%, 4.9h (v100), tb.dev |
| vit-l_16 | CIFAR10 | 99.13%, 6.9h (A100), TB.Dev | 99.14%, 24.7H (V100), TB.Dev |
| vit-l_16 | CIFAR100 | 92.91%, 7.1h (A100), tb.dev | 93.22%, 24.4H (V100), TB.Dev |
| vit-l_16 | ImageNet2012 | 84.47%, 16.8H (A100), TB.Dev | 85.05%, 59.7H (V100), tb.dev |
| vit-l_32 | CIFAR10 | 99.06%, 1.9H (A100), TB.DEV | 99.09%, 6.1h (v100), tb.dev |
| vit-l_32 | CIFAR100 | 93.29%, 1.9H (A100), TB.DEV | 93.34%, 6.2h (v100), tb.dev |
| vit-l_32 | ImageNet2012 | 81.89%, 7.5h (A100), TB.Dev | 81.13%, 15.0h (v100), tb.dev |
นอกจากนี้เรายังต้องการเน้นว่าผลลัพธ์ที่มีคุณภาพสูงสามารถทำได้ด้วยตารางการฝึกอบรมที่สั้นลงและกระตุ้นให้ผู้ใช้รหัสของเราเล่นกับพารามิเตอร์ไฮเปอร์เพื่อความแม่นยำในการแลกเปลี่ยนและงบประมาณการคำนวณ ตัวอย่างบางส่วนสำหรับชุดข้อมูล CIFAR-10/100 จะถูกนำเสนอในตารางด้านล่าง
| ต้นน้ำ | แบบอย่าง | ชุดข้อมูล | total_steps / warmup_steps | ความแม่นยำ | เวลาปิดผนัง | การเชื่อมโยง |
|---|---|---|---|---|---|---|
| imageNet21k | vit-b_16 | CIFAR10 | 500 /50 | 98.59% | 17m | tensorboard.dev |
| imageNet21k | vit-b_16 | CIFAR10 | 1,000 / 100 | 98.86% | 39m | tensorboard.dev |
| imageNet21k | vit-b_16 | CIFAR100 | 500 /50 | 89.17% | 17m | tensorboard.dev |
| imageNet21k | vit-b_16 | CIFAR100 | 1,000 / 100 | 91.15% | 39m | tensorboard.dev |
โดย Ilya Tolstikhin*, Neil Houlsby*, Alexander Kolesnikov*, Lucas Beyer*, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic
(*) การมีส่วนร่วมที่เท่าเทียมกัน
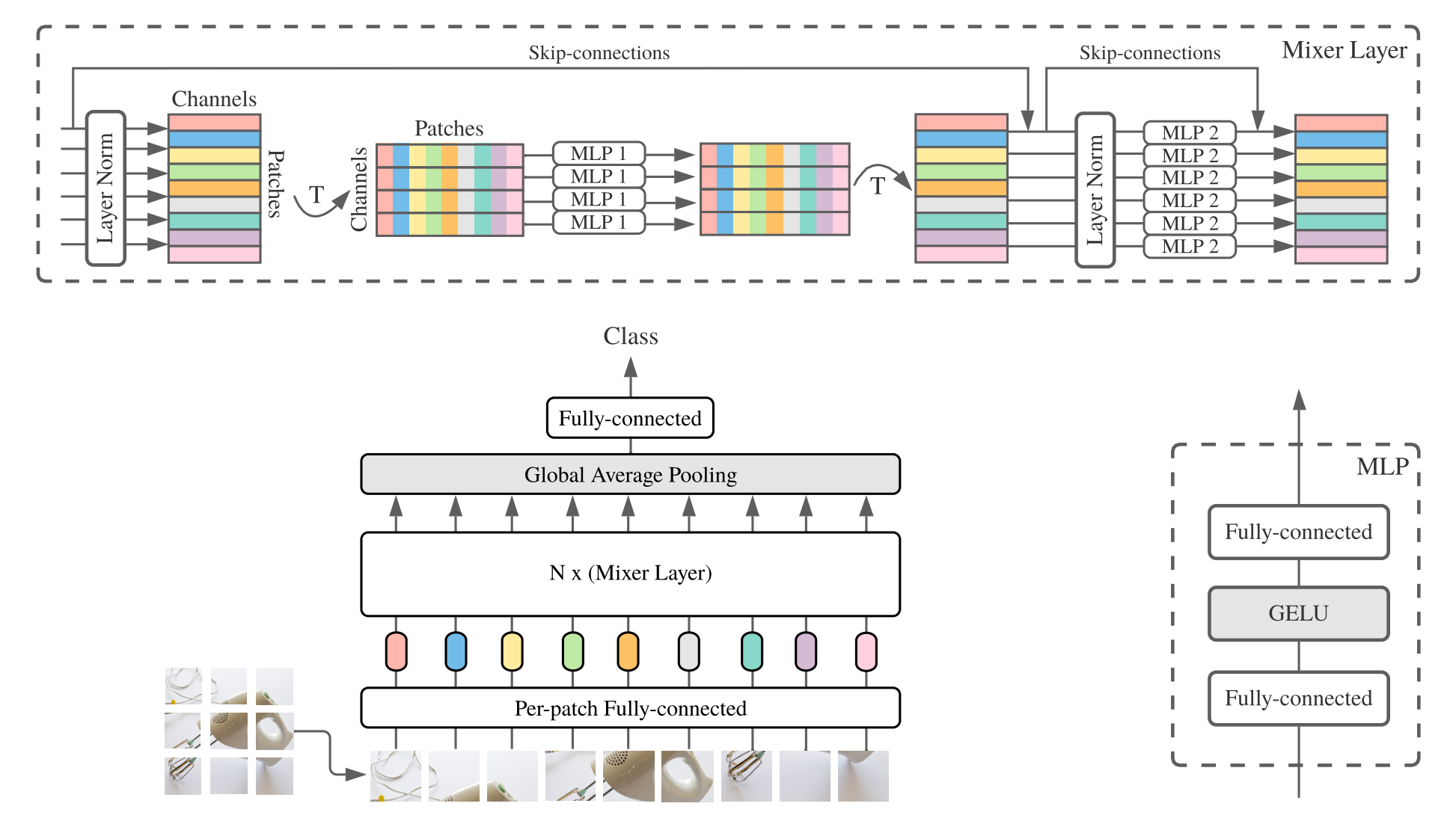
MLP-Mixer ( Mixer สั้น ๆ ) ประกอบด้วย embeddings เชิงเส้นต่อแพทช์เลเยอร์มิกเซอร์และหัวจําแนก เลเยอร์มิกเซอร์มี MLP ผสมโทเค็นหนึ่งตัวและ MLP การผสมช่องหนึ่งช่องแต่ละอันประกอบด้วยสองชั้นที่เชื่อมต่ออย่างสมบูรณ์และความไม่เชิงเส้นของเจลลู ส่วนประกอบอื่น ๆ ได้แก่ : การเชื่อมต่อข้าม, การออกกลางคันและหัวจําแนกเชิงเส้น
สำหรับการติดตั้งทำตามขั้นตอนเดียวกันกับด้านบน
เราให้บริการ Mixer-B/16 และ Mixer-L/16 รุ่นที่ผ่านการฝึกอบรมล่วงหน้าบนชุดข้อมูล Imagenet และ Imagenet-21K รายละเอียดสามารถพบได้ในตารางที่ 3 ของกระดาษผสม ทุกรุ่นสามารถพบได้ที่:
https://console.cloud.google.com/storage/mixer_models/
โปรดทราบว่ารุ่นเหล่านี้มีให้บริการโดยตรงจาก TF-Hub: Sayakpaul/Collections/MLP-Mixer (การสนับสนุนภายนอกโดย Sayak Paul)
เราใช้รหัสการปรับแต่งอย่างละเอียดบน Google Cloud Machine ด้วย V100 GPU สี่ตัวพร้อมพารามิเตอร์การปรับเริ่มต้นจากที่เก็บนี้ นี่คือผลลัพธ์:
| ต้นน้ำ | แบบอย่าง | ชุดข้อมูล | ความแม่นยำ | wall_clock_time | การเชื่อมโยง |
|---|---|---|---|---|---|
| ImageNet | Mixer-B/16 | CIFAR10 | 96.72% | 3.0h | tensorboard.dev |
| ImageNet | Mixer-L/16 | CIFAR10 | 96.59% | 3.0h | tensorboard.dev |
| ImageNet-21K | Mixer-B/16 | CIFAR10 | 96.82% | 9.6h | tensorboard.dev |
| ImageNet-21K | Mixer-L/16 | CIFAR10 | 98.34% | 10.0h | tensorboard.dev |
สำหรับรายละเอียดโปรดดูที่โพสต์บล็อกของ Google AI: การเพิ่มความเข้าใจภาษาในรูปแบบรูปภาพหรืออ่านกระดาษ CVPR "LIT: การถ่ายโอนแบบไม่มีการถ่ายภาพด้วยการปรับแต่งข้อความล็อค-ภาพ" (https://arxiv.org/abs/2111.079911 ).
เราตีพิมพ์โมเดล B/16-base Transformer ด้วยความแม่นยำของ Imagenet Zeroshot ที่ 72.1%และรุ่น L/16 ขนาดใหญ่ด้วยความแม่นยำของ Imagenet Zeroshot ที่ 75.7% สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับโมเดลเหล่านี้โปรดดูที่การ์ดรุ่น Lit
เราให้บริการสาธิตในเบราว์เซอร์พร้อมตัวเข้ารหัสข้อความขนาดเล็กสำหรับการใช้งานแบบโต้ตอบ (รุ่นที่เล็กที่สุดควรทำงานบนโทรศัพท์มือถือที่ทันสมัย):
https://google-research.github.io/vision_transformer/lit/
และในที่สุดก็เป็น colab ที่ใช้โมเดล JAX ที่มีทั้งภาพและตัวเข้ารหัสข้อความ:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
โปรดทราบว่ายังไม่มีรุ่นข้างต้นรองรับอินพุตหลายภาษา แต่เรากำลังดำเนินการเผยแพร่โมเดลดังกล่าวและจะอัปเดตที่เก็บนี้เมื่อเปิดให้บริการ
ที่เก็บนี้มีรหัสการประเมินผลสำหรับแบบจำลองที่มีแสงเท่านั้น คุณสามารถค้นหารหัสการฝึกอบรมในที่เก็บ big_vision :
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
ZeroShot ที่คาดหวังเป็นผลมาจาก model_cards/lit.md (โปรดทราบว่าการประเมิน ZeroShot นั้นแตกต่างจากการประเมินที่ง่ายขึ้นเล็กน้อยใน colab):
| แบบอย่าง | b16b_2 | L16L |
|---|---|---|
| ImageNet Zero-shot | 73.9% | 75.7% |
| ImageNet v2 zero-shot | 65.1% | 66.6% |
| CIFAR100 zero-shot | 79.0% | 80.5% |
| Pets37 zero-shot | 83.3% | 83.3% |
| Resisc45 zero-shot | 25.3% | 25.6% |
| คำอธิบายภาพ MS-COCO | 51.6% | 48.5% |
| คำอธิบายภาพ MS-COCO | 31.8% | 31.1% |
ในขณะที่ Colabs ข้างต้นมีประโยชน์ในการเริ่มต้นคุณมักจะต้องการฝึกบนเครื่องจักรขนาดใหญ่ด้วยตัวเร่งความเร็วที่ทรงพลังกว่า
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อตั้งค่า VM ด้วย GPU บน Google Cloud:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEอีกทางเลือกหนึ่งคุณสามารถใช้คำสั่งที่คล้ายกันต่อไปนี้เพื่อตั้งค่า Cloud VM พร้อม TPUs ที่แนบมากับพวกเขา (ด้านล่างคำสั่งที่คัดลอกมาจากการสอน TPU):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME จากนั้นดึงข้อมูลที่เก็บและการพึ่งพาการติดตั้ง (รวมถึง jaxlib ด้วยการสนับสนุน TPU) ตามปกติ:
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateหากคุณเชื่อมต่อกับ VM ที่ติดตั้ง GPU ให้ติดตั้ง JAX และการอ้างอิงอื่น ๆ ด้วยคำสั่งต่อไปนี้:
pip install -r vit_jax/requirements.txtหากคุณเชื่อมต่อกับ VM ที่ติดตั้ง TPU ให้ติดตั้ง JAX และการอ้างอิงอื่น ๆ ด้วยคำสั่งต่อไปนี้:
pip install -r vit_jax/requirements-tpu.txtติดตั้ง Flaxformer ทำตามคำแนะนำที่ให้ไว้ในที่เก็บข้อมูลที่เชื่อมโยงที่นี่
สำหรับทั้ง GPU และ TPU ให้ตรวจสอบว่า JAX สามารถเชื่อมต่อกับตัวเร่งความเร็วที่แนบมากับคำสั่ง:
python -c ' import jax; print(jax.devices()) 'และในที่สุดก็ดำเนินการหนึ่งในคำสั่งที่กล่าวถึงในส่วนปรับแต่งโมเดล
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
ตามลำดับเวลาย้อนกลับ:
2022-08-18: เพิ่มรุ่น LIT-B16B_2 ที่ได้รับการฝึกฝนสำหรับขั้นตอน 60K (LIT_B16B: 30K) โดยไม่มีหัวเชิงเส้นอยู่ด้านภาพ (LIT_B16B: 768) และมีประสิทธิภาพที่ดีขึ้น
2022-06-09: เพิ่มรุ่น VIT และมิกเซอร์ที่ได้รับการฝึกฝนตั้งแต่เริ่มต้นโดยใช้ GSAM บน Imagenet โดยไม่ต้องเพิ่มข้อมูลที่แข็งแกร่ง ผลลัพธ์นั้นมีประสิทธิภาพสูงกว่าขนาดที่คล้ายกันโดยใช้ ADAMW Optimizer หรืออัลกอริทึม SAM ดั้งเดิมหรือมีการเพิ่มข้อมูลที่แข็งแกร่ง
2022-04-14: เพิ่มโมเดลและ colab สำหรับรุ่นที่มีแสงสว่าง
2021-07-29: เพิ่มโมเดล VIT-B/8 AUGREG (จุดตรวจอัพสตรีม 3 จุดและการปรับตัวด้วยความละเอียด = 224)
2021-07-02: เพิ่ม "เมื่อ Vision Transformers มีประสิทธิภาพสูงกว่า Resnets ... "
2021-07-02: เพิ่ม SAM (จุดเล็ก ๆ ที่ลดความคมชัด) จุดตรวจ VIT และ MLP-Mixer ที่ดีที่สุด
2021-06-20: เพิ่มกระดาษ "How to Train Your Vit? ... " และ colab ใหม่เพื่อสำรวจจุดตรวจสอบที่ได้รับการฝึกอบรมล่วงหน้าและได้รับการฝึกฝนมาก่อนและปรับแต่งได้อย่างละเอียดในกระดาษ
2021-06-18: ที่เก็บนี้ถูกเขียนใหม่เพื่อใช้ผ้าลินิน API และ ml_collections.ConfigDict สำหรับการกำหนดค่า
2021-05-19: ด้วยการตีพิมพ์กระดาษ "How to Train Your Vit? ... " เราได้เพิ่มโมเดล VIT และไฮบริดมากกว่า 50K ที่ได้รับการฝึกฝนไว้ล่วงหน้าเกี่ยวกับ ImageNet และ ImageNet-21K ด้วยการเพิ่มข้อมูลหลายระดับและแบบจำลองการทำให้เป็นมาตรฐาน และปรับแต่งอย่างละเอียดเกี่ยวกับ Imagenet, Pets37, Kitti-distance, CIFAR-100 และ RESISC45 ตรวจสอบ vit_jax_augreg.ipynb เพื่อนำทางขุมทรัพย์ของโมเดลนี้! ตัวอย่างเช่นคุณสามารถใช้ colab นั้นเพื่อดึงชื่อไฟล์ของจุดตรวจสอบที่ได้รับการฝึกอบรมล่วงหน้าและได้รับการฝึกอบรมอย่างละเอียดจากคอลัมน์ i21k_300 ของตารางที่ 3 ในกระดาษ
2020-12-01: เพิ่มโมเดลไฮบริด R50+VIT-B/16 (VIT-B/16 ที่ด้านบนของกระดูกสันหลัง RESNET-50) เมื่อได้รับการปรับแต่งเกี่ยวกับ Imagenet21K โมเดลนี้จะได้รับประสิทธิภาพเกือบของโมเดล L/16 โดยมีค่าใช้จ่ายในการคำนวณน้อยกว่าครึ่งหนึ่ง โปรดทราบว่า "R50" ค่อนข้างได้รับการแก้ไขสำหรับตัวแปร B/16: RESNET-50 ดั้งเดิมมี [3,4,6,3] บล็อกแต่ละบล็อกลดความละเอียดของภาพด้วยปัจจัยสองตัว เมื่อรวมกับลำต้น resnet สิ่งนี้จะส่งผลให้ลดลง 32x ดังนั้นแม้จะมีขนาดแพตช์ (1,1) ตัวแปร Vit-B/16 ไม่สามารถรับรู้ได้อีกต่อไป ด้วยเหตุนี้เราจึงใช้ [3,4,9] บล็อกสำหรับตัวแปร R50+B/16
2020-11-09: เพิ่มรุ่น VIT-L/16
2020-10-29: เพิ่ม VIT-B/16 และ VIT-L/16 รุ่นที่ได้รับการปรับแต่งบน ImageNet-21K จากนั้นปรับแต่ง ImageNet ที่ความละเอียด 224x224 (แทนที่จะเป็นค่าเริ่มต้น 384x384) โมเดลเหล่านี้มีคำต่อท้าย "-224" ในชื่อของพวกเขา พวกเขาคาดว่าจะบรรลุความแม่นยำ 81.2% และ 82.7% Top-1 ตามลำดับ
โอเพนซอร์สที่จัดทำโดย Andreas Steiner
หมายเหตุ: ที่เก็บนี้ถูกแยกและแก้ไขจาก Google Research/Big_Transfer
นี่ไม่ใช่ผลิตภัณฑ์ของ Google อย่างเป็นทางการ


