LLaMA Omni
1.0.0
ผู้เขียน: Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui MA, Shaolei Zhang, Yang Feng*
Llama-Omni เป็นแบบจำลองภาษาพูดที่สร้างขึ้นบน Llama-3.1-8B-Instruct รองรับการโต้ตอบเสียงพูดที่มีความยืดหยุ่นต่ำและมีคุณภาพสูงพร้อมกันสร้างทั้งการตอบสนองข้อความและคำพูดตามคำแนะนำการพูด
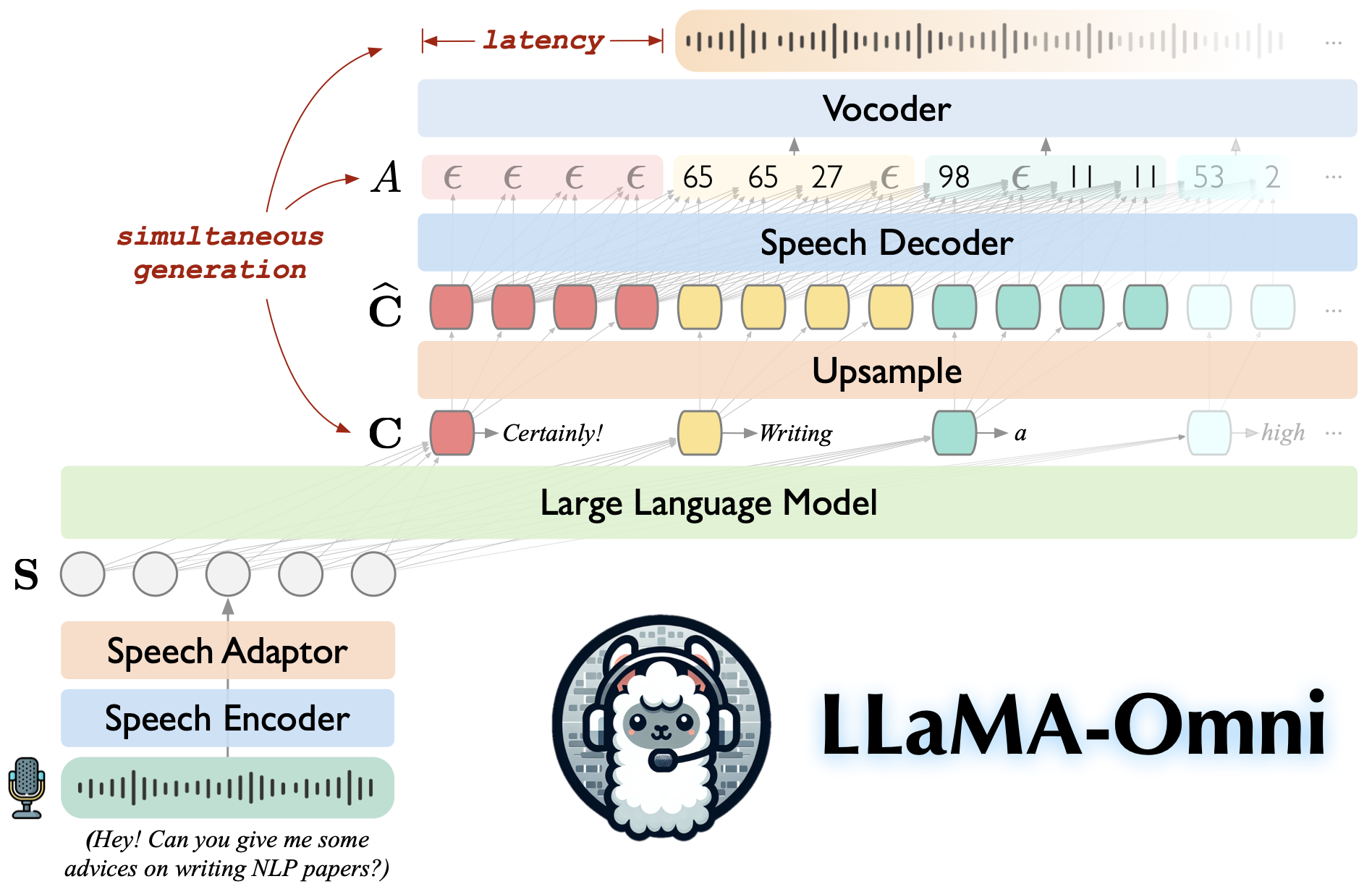
สร้างขึ้นบน LLAMA-3.1-8B-Instruct สร้างความมั่นใจในการตอบสนองที่มีคุณภาพสูง
การโต้ตอบคำพูดที่มีความล่าช้าต่ำกับเวลาแฝงต่ำถึง 226ms
การสร้างข้อความและการพูดพร้อมกัน
♻ ฝึกอบรมในเวลาน้อยกว่า 3 วันโดยใช้เพียง 4 GPU
โคลนที่เก็บนี้
git clone https://github.com/ictnlp/llama-omnicd llama-omni
ติดตั้งแพ็คเกจ
conda create -n llama -omni python = 3.10 Conda เปิดใช้งาน Llama-Omni PIP ติดตั้ง pip == 24.0 การติดตั้ง PIP -E
ติดตั้ง fairseq
git clone https://github.com/pytorch/fairseqcd fairseq การติดตั้ง PIP -E -ไม่มีการรวมกัน
ติดตั้ง flash-attention
PIP Install Flash-Attn-ไม่มีการสร้างไอโซเลชั่น
ดาวน์โหลดโมเดล Llama-3.1-8B-Omni จาก? HuggingFace
ดาวน์โหลดรุ่น Whisper-large-v3
นำเข้ากระซิบ
model = whisper.load_model ("large-v3", download_root = "models/speech_encoder/")ดาวน์โหลด Hifi-Gan Vocoder ตามหน่วย
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -p Vocoder/ wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -
เปิดตัวคอนโทรลเลอร์
Python -m Omni_Speech.serve.Controller -โฮสต์ 0.0.0.0 -พอร์ต 10,000
เปิดเว็บเซิร์ฟเวอร์ Gradio
Python -m omni_speech.serve.gradio_web_server-ตัวควบคุม http: // localhost: 10,000-พอร์ต 8000-โมเดล-โหมด-โหมดโหลด-vocoder vocoder/g_00500000-vocoder-cfg vocoder/config.json
เปิดตัว Model Worker
Python -m omni_speech.serve.model_worker-โฮสต์ 0.0.0.0-ตัวควบคุม http: // localhost: 10,000-พอร์ต 40000-worker http: // localhost: 40000 -Model-name llama-3.1-8b-omni--s2s
เยี่ยมชม http: // localhost: 8000/และโต้ตอบกับ llama-3.1-8b-omni!
หมายเหตุ: เนื่องจากความไม่แน่นอนของการสตรีมการเล่นเสียงใน Gradio เราจึงใช้การสังเคราะห์เสียงสตรีมมิ่งเฉพาะโดยไม่ต้องเปิดใช้งานการเล่นอัตโนมัติ หากคุณมีทางออกที่ดีอย่าลังเลที่จะส่ง PR ขอบคุณ!
ในการเรียกใช้การอนุมานในเครื่องโปรดจัดระเบียบไฟล์คำสั่งคำพูดตามรูปแบบในไดเรกทอรี omni_speech/infer/examples จากนั้นอ้างถึงสคริปต์ต่อไปนี้
bash omni_speech/infer/run.sh omni_speech/อนุมาน/ตัวอย่าง
รหัสของเราถูกเผยแพร่ภายใต้ใบอนุญาต Apache-2.0 แบบจำลองของเรามีวัตถุประสงค์เพื่อวัตถุประสงค์ในการวิจัยเชิงวิชาการเท่านั้นและอาจ ไม่ ได้ใช้เพื่อวัตถุประสงค์ทางการค้า
คุณมีอิสระที่จะใช้แก้ไขและแจกจ่ายโมเดลนี้ในการตั้งค่าทางวิชาการโดยมีเงื่อนไขว่าจะตรงตามเงื่อนไขต่อไปนี้:
การใช้งานที่ไม่ใช่เชิงพาณิชย์ : โมเดลอาจไม่ได้ใช้เพื่อวัตถุประสงค์ทางการค้าใด ๆ
การอ้างอิง : หากคุณใช้โมเดลนี้ในการวิจัยของคุณโปรดอ้างอิงงานต้นฉบับ
สำหรับการสอบถามการใช้งานเชิงพาณิชย์หรือเพื่อรับใบอนุญาตเชิงพาณิชย์กรุณาติดต่อ [email protected]
Llava: รหัสฐานที่เราสร้างขึ้น
SLAM-LLM: เรายืมรหัสเกี่ยวกับการเข้ารหัสคำพูดและอะแดปเตอร์คำพูด
หากคุณมีคำถามใด ๆ โปรดส่งปัญหาหรือติดต่อ [email protected]
หากงานของเรามีประโยชน์สำหรับคุณโปรดอ้างอิงเป็น:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

