Huawei UK University Challenge Competition 2021
1.0.0

ผู้นำเสนอทีม: Kahraman Kostas
เพื่อให้คุณเริ่มต้นเราได้รวบรวมปัญหาง่ายๆเพื่อแนะนำแนวคิดการวางตำแหน่งในร่มที่สำคัญ พิจารณาสภาพแวดล้อมต่อไปนี้: ผู้ใช้กำลังเดินทางในพื้นที่เปิดโล่งต่อหน้าตัวปล่อย WiFi 3 ตัว (เราเรียกข้อมูลที่สร้างโดยผู้ใช้รายนี้ว่าวิถี) ตัวปล่อยแต่ละตัวมีที่อยู่ MAC ที่ไม่ซ้ำกัน ผู้ใช้ติดตั้งสมาร์ทโฟนที่จะสแกนสภาพแวดล้อม WiFi เป็นระยะและบันทึก RSSI ของ MAC ที่ตรวจพบแต่ละตัว (เป็น DB)
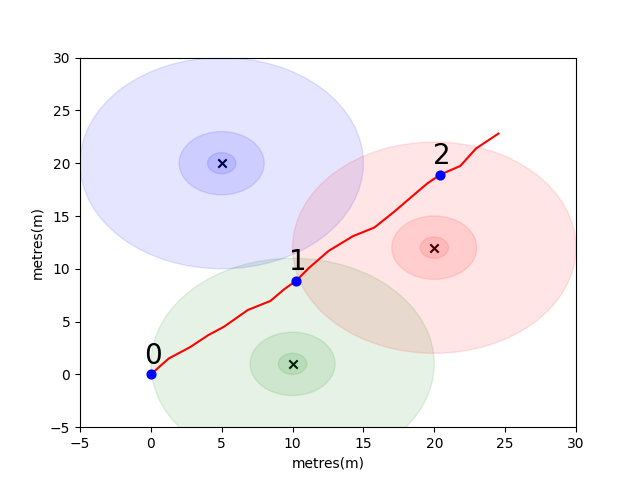
สำหรับรุ่นนี้เราได้ใช้โมเดลการแพร่กระจายพื้นที่ฟรีล็อกสเปซสำหรับตัวปล่อยแต่ละตัว นี่เป็นรูปแบบที่เรียบง่ายที่ทำงานได้ดีในพื้นที่ว่าง แต่แบ่งออกเป็นสภาพแวดล้อมในร่มจริงด้วยผนังและอุปสรรคอื่น ๆ ที่สามารถตีกลับสัญญาณรอบ ๆ ในลักษณะที่ซับซ้อนมากขึ้น โดยทั่วไปเราคาดว่าจะเห็นการลดลงของ RSSI ในระยะทางไกลกว่าระยะทางเนื่องจากพลังงานคงที่จากเสาอากาศที่เปล่งออกมานั้นแพร่กระจายไปทั่วพื้นที่ที่เพิ่มขึ้นเมื่อคลื่นแพร่กระจาย ในแผนภาพด้านล่างแต่ละวงกลมหมายถึงหยด 10dB
ผู้ใช้เดินไปทางตะวันออกเฉียงเหนือจากจุด (0,0) และมีโทรศัพท์ทำการสแกนสภาพแวดล้อมสามครั้ง ข้อมูลที่บันทึกไว้ในการสแกนแต่ละครั้งจะแสดงด้านล่าง
scan 0 -> {'green': -60, 'blue': -66, 'red': -67}
scan 1 -> {'green': -58, 'blue': -61, 'red': -60}
scan 2 -> {'green': -66, 'blue': -62, 'red': -59}
คุณสมบัติที่ซับซ้อนและเป็นเอกลักษณ์ในท้องถิ่นของสภาพแวดล้อม WiFi ทำให้มีประโยชน์มากสำหรับระบบการวางตำแหน่งในร่ม ตัวอย่างเช่นในภาพด้านล่าง scan 1 วัดข้อมูลที่ประมาณเซนทรอยด์ของตัวปล่อยสามตัวและไม่มีสถานที่อื่นในสภาพแวดล้อมนี้ที่สามารถอ่านได้ซึ่งจะลงทะเบียนค่า RSSI ที่คล้ายกัน ด้วยชุดของการสแกนหรือ "ลายนิ้วมือ" จากวิถีอิสระเรามีความสนใจในการคำนวณว่าพวกเขามีความคล้ายคลึงกันในพื้นที่ wifi เนื่องจากนี่เป็นข้อบ่งชี้ว่าพวกเขาอยู่ใกล้แค่ไหนในพื้นที่จริง
ความท้าทายแรกของคุณคือการเขียนฟังก์ชั่นเพื่อคำนวณ ระยะทางแบบยุคลิด และการวัด ระยะทางของแมนฮัตตัน ระหว่างการสแกนแต่ละครั้งในวิถีตัวอย่างที่เราแนะนำข้างต้น การใช้ข้อมูลจากวิถีเดียวเป็นวิธีที่ดีในการทดสอบคุณภาพของตัวชี้วัดความคล้ายคลึงกันเนื่องจากเราสามารถประเมินระยะทางที่แท้จริงได้อย่างแม่นยำโดยใช้ข้อมูลจากหน่วยวัด intertial ของโทรศัพท์ (IMU) ซึ่งใช้โดยคนเดินเท้า โมดูล (PDR)
def euclidean ( fp1 , fp2 ):
raise NotImplementedError
def manhattan ( fp1 , fp2 ):
raise NotImplementedError # solution of the above functions
from scipy . spatial import distance
def euclidean ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . euclidean ( fp1 , fp2 )
def manhattan ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . cityblock ( fp1 , fp2 ) import json
import numpy as np
import matplotlib . pyplot as plt
from metrics import eval_dist_metric
with open ( "intro_trajectory_1.json" ) as f :
traj = json . load ( f )
## Pre-calculate the pair indexes we are interested in
keys = []
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
# only calculate the upper triangle
if fp1 [ 'step_index' ] > fp2 [ 'step_index' ]:
keys . append (( fp1 [ 'step_index' ], fp2 [ 'step_index' ]))
## Get the distances from PDR
true_d = {}
for step1 in traj [ 'steps' ]:
for step2 in traj [ 'steps' ]:
key = ( step1 [ 'step_index' ], step2 [ 'step_index' ])
if key in keys :
true_d [ key ] = abs ( step1 [ 'di' ] - step2 [ 'di' ])
euc_d = {}
man_d = {}
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
key = ( fp1 [ 'step_index' ], fp2 [ 'step_index' ])
if key in keys :
euc_d [ key ] = euclidean ( fp1 [ 'profile' ], fp2 [ 'profile' ])
man_d [ key ] = manhattan ( fp1 [ 'profile' ], fp2 [ 'profile' ])
print ( "Euclidean Average Error" )
print ( f' { eval_dist_metric ( euc_d , true_d ):.2f } ' )
print ( "Manhattan Average Error" )
print ( f' { eval_dist_metric ( man_d , true_d ):.2f } ' ) Euclidean Average Error
9.29
Manhattan Average Error
4.90
หากคุณใช้งานฟังก์ชั่นอย่างถูกต้องคุณควรเห็นว่าข้อผิดพลาดโดยเฉลี่ยสำหรับตัวชี้วัดแบบยุคลิดคือ 9.29 ในขณะที่แมนฮัตตันมีเพียง 4.90 ดังนั้นสำหรับข้อมูลนี้ระยะทางแมนฮัตตันจึงเป็นระยะเวลาที่ดีกว่าของระยะทางที่แท้จริง
นี่เป็นแบบจำลองที่ง่ายมาก อันที่จริงไม่มีความสัมพันธ์โดยตรงระหว่างค่า RSSI และระยะห่างของพื้นที่ว่างด้วยวิธีนี้ โดยทั่วไปเมื่อเราสร้างการประมาณระยะทางของเราเองเราจะใช้ระยะทาง PDR ที่รู้จักจากภายในวิถีเพื่อให้พอดีกับคะแนนตัวเลขกับการประมาณระยะทางกายภาพ
สำหรับความท้าทายหลักของคุณเราต้องการให้คุณพัฒนาตัวชี้วัดของคุณเองเพื่อประเมินระยะห่างจากโลกแห่งความเป็นจริงระหว่างการสแกนสองครั้งโดยใช้ลายนิ้วมือ WiFi ของพวกเขาเท่านั้น เราจะให้ข้อมูลที่รวบรวมได้จริงแก่คุณในช่วงต้นปี 2564 จากห้างสรรพสินค้าเดียว ข้อมูลจะมีการสแกนลายนิ้วมือ 114661 และระยะทาง 879824 ระหว่างการสแกน ระยะทางจะเป็นการประมาณการที่ดีที่สุดของเราเกี่ยวกับระยะทางที่แท้จริงที่ได้รับข้อมูลเพิ่มเติมที่เราจะคำนึงถึง
เราจะจัดเตรียมชุดทดสอบของคู่ลายนิ้วมือและคุณจะต้องเขียนฟังก์ชั่นที่บอกเราว่าพวกเขาอยู่ห่างกันมากแค่ไหน
ฟังก์ชั่นนี้อาจเป็นเรื่องง่ายเหมือนการเปลี่ยนแปลงในหนึ่งในตัวชี้วัดที่เราแนะนำข้างต้นหรือซับซ้อนเป็นโซลูชันการเรียนรู้ของเครื่องเต็มรูปแบบที่เรียนรู้ต่อที่อยู่ MAC ที่แตกต่างกัน (หรือการรวมที่อยู่ MAC) แตกต่างกันในสถานการณ์ที่แตกต่างกัน
บางจุดสุดท้ายที่ควรพิจารณา:
ข้อมูลถูกรวบรวมเป็นสามไฟล์สำหรับคุณ
task1_fingerprints.json มีข้อมูลลายนิ้วมือทั้งหมดสำหรับปัญหา นั่นคือแต่ละรายการแสดงถึงการสแกนที่แท้จริงของตัวปล่อย wifi ในพื้นที่ของห้างสรรพสินค้า คุณจะพบว่าที่อยู่ MAC เดียวกันนี้จะปรากฏในลายนิ้วมือหลายแห่ง
task1_train.csv มีคู่การฝึกอบรมที่ถูกต้องเพื่อช่วยคุณออกแบบ/ฝึกอบรมอัลกอริทึมของคุณ คู่ id1-id2 แต่ละคู่มีระยะทางความจริงภาคพื้นดินที่มีป้ายกำกับ (เป็นเมตร) และแต่ละ ID สอดคล้องกับลายนิ้วมือจาก task1_fingerprints.json
task1_test.csv เป็นรูปแบบเดียวกับ task1_train.csv แต่ไม่มีการกระจัด นี่คือสิ่งที่เราต้องการให้คุณทำนายโดยใช้ข้อมูลลายนิ้วมือดิบ
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
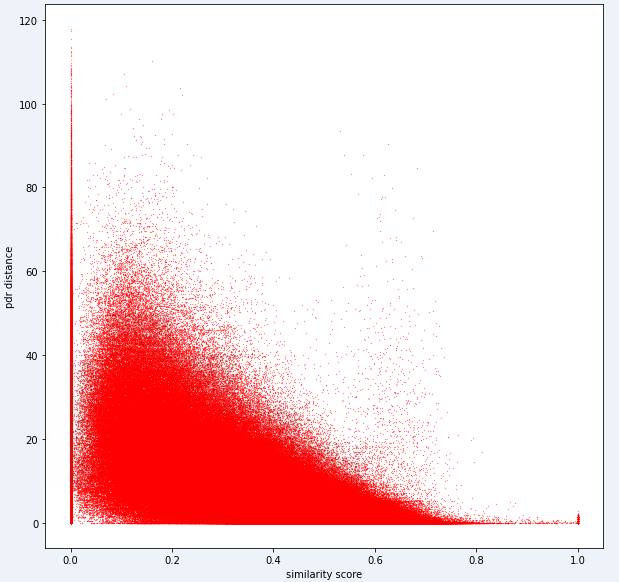
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]])ในที่สุดโมเดลในอุดมคติควรจะสามารถค้นหาการแมปที่แน่นอนระหว่างพื้นที่ลายนิ้วมือขนาดสูง (ลายนิ้วมือ 1 สามารถมีการวัดได้มากมาย) และพื้นที่ระยะทาง 1 มิติ มันจะมีประโยชน์ในการพล็อตระยะทาง PDR (จากข้อมูลการฝึกอบรม) กับตัวชี้วัดความคล้ายคลึงกันที่คำนวณได้เพื่อดูว่าตัวชี้วัดแสดงแนวโน้มที่ชัดเจนหรือไม่ ความคล้ายคลึงกันสูงควรมีความสัมพันธ์กับระยะทางต่ำ
ด้านล่างเป็นตัวชี้วัดระยะทางเดียวที่เราใช้ภายในสำหรับงานนี้ คุณจะเห็นว่าแม้สำหรับตัวชี้วัดนี้เรามีเสียงรบกวนจำนวนมาก
เนื่องจากเสียงรบกวนระดับนี้ตัวชี้วัดการให้คะแนนของเราสำหรับงาน 1 จะมีอคติต่อความแม่นยำมากกว่าการเรียกคืน
การส่งของคุณควรใช้ ID ที่แน่นอน จากไฟล์ test1_test.csv และควรเติมคอลัมน์การกระจัดที่สาม (ว่างเปล่า) ด้วยระยะทางโดยประมาณ (เป็นเมตร) สำหรับคู่ลายนิ้วมือนั้น
def my_distance_function ( fp1 , fp2 ):
raise NotImplementedError output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
fp1 = fps [ id1 ]
fp2 = fps [ id2 ]
distance_estimate = my_distance_function ( fp1 , fp2 )
output_data . append ([ id1 , id2 , distance_estimate ])
with open ( "MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )ขั้นตอนในงานแรกสามารถสรุปได้ดังนี้
ขั้นตอนเหล่านี้แสดงไว้ในภาพด้านล่าง

เราใช้ Python 3.6.5 เพื่อสร้างไฟล์แอปพลิเคชัน เรารวมโมดูลเพิ่มเติมบางอย่างที่ไม่รวมอยู่ในไฟล์ตัวอย่างที่ให้ไว้ในช่วงเริ่มต้นของการแข่งขัน โมดูลเหล่านี้สามารถแสดงรายการเป็น:
| โมล | งาน |
|---|---|
| เทนเซอร์โฟลว์ | การเรียนรู้อย่างลึกซึ้ง |
| แพนด้า | การวิเคราะห์ข้อมูล |
| คนขี้เกียจ | การคำนวณระยะไกล |
เราเริ่มต้นด้วยการติดตั้งโมดูลเหล่านี้เป็นขั้นตอนแรก
## 1.1 Installing modules
!p ip install tensorflow == 2.6 . 2
!p ip install scipy
!p ip install pandas ในขั้นตอนนี้เราได้แก้ไขเมล็ดสุ่มที่เกี่ยวข้องที่จะใช้เพื่อให้ได้ผลลัพธ์ที่ทำซ้ำได้ ด้วยวิธีนี้เราได้จัดเตรียมเส้นทางที่กำหนดไว้ซึ่งเราได้รับผลลัพธ์เดียวกันในทุกการวิ่ง อย่างไรก็ตามจากการสังเกตของเราผลลัพธ์ที่ได้จากคอมพิวเตอร์ที่แตกต่างกันอาจแตกต่างกันเล็กน้อย (± 1%)
## 1.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )
import tensorflow as tf
tf . random . set_seed ( seed_value )
import tensorflow as tf
session_conf = tf . compat . v1 . ConfigProto ( intra_op_parallelism_threads = 1 , inter_op_parallelism_threads = 1 )
sess = tf . compat . v1 . Session ( graph = tf . compat . v1 . get_default_graph (), config = session_conf ) ในส่วนนี้เราโหลดข้อมูลที่เราจะใช้ เราใช้รหัสและคำอธิบายจากไฟล์ตัวอย่างที่ให้ไว้ ( Task1-IPS-Challenge-2021.ipynb )
task1_fingerprints.json มีข้อมูลลายนิ้วมือทั้งหมดสำหรับปัญหา นั่นคือแต่ละรายการแสดงถึงการสแกนที่แท้จริงของตัวปล่อย wifi ในพื้นที่ของห้างสรรพสินค้า คุณจะพบว่าที่อยู่ MAC เดียวกันนี้จะปรากฏในลายนิ้วมือหลายแห่ง
task1_train.csv มีคู่การฝึกอบรมที่ถูกต้องเพื่อช่วยคุณออกแบบ/ฝึกอบรมอัลกอริทึมของคุณ คู่ id1-id2 แต่ละคู่มีระยะทางความจริงภาคพื้นดินที่มีป้ายกำกับ (เป็นเมตร) และแต่ละ ID สอดคล้องกับลายนิ้วมือจาก task1_fingerprints.json
task1_test.csv เป็นรูปแบบเดียวกับ task1_train.csv แต่ไม่มีการกระจัด
## 1.3 Loading the data
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]]) 879824it [05:16, 2778.31it/s]
5160445it [01:00, 85269.27it/s]
ในขั้นตอนนี้เราทำการแยกคุณสมบัติโดยใช้สองฟังก์ชั่น ฟังก์ชั่น feature_extraction_file เพียงแค่ดึงค่าที่เกี่ยวข้องของลายนิ้วมือ (เป็นคู่) จากไฟล์ JSON และส่งไปยังฟังก์ชัน feature_extraction เพื่อทำการคำนวณ
ในฟังก์ชั่น feature_extraction หากลายนิ้วมือทั้งสองนี้แตกต่างจากกันในแง่ของขนาดและอุปกรณ์ที่มีอยู่อุปกรณ์ทั้งหมดที่รวมอยู่ในลายนิ้วมือทั้งสองจะถูกนำมารวมกันเพื่อสร้างลำดับทั่วไปโดยไม่ต้องทำซ้ำ ในแต่ละอาร์เรย์เราทำให้ทั้งสองอาร์เรย์นี้เหมือนกัน (ในแง่ของอุปกรณ์ที่พวกเขารวม) โดยการกำหนดค่า 0 ให้กับอุปกรณ์ที่ไม่สอดคล้องกัน กระบวนการนี้อธิบายด้วยตัวอย่างในภาพต่อไปนี้
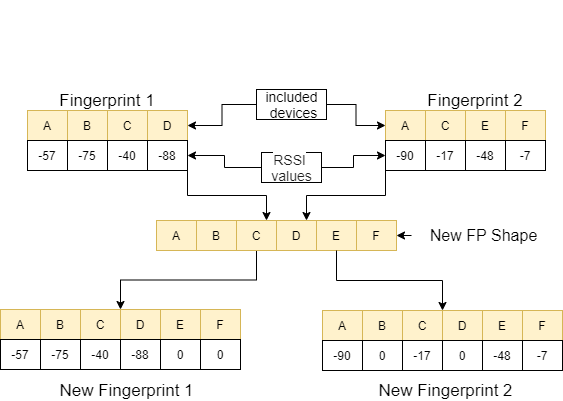
ระยะห่างระหว่างสองลายนิ้วมือซึ่งทำคล้ายกันคำนวณโดยใช้ 11 วิธีที่แตกต่างกัน [1] วิธีการเหล่านี้คือ:
จากนั้นค่าเหล่านี้จะถูกส่งไปยังฟังก์ชัน feature_extraction_file และบันทึกเป็นไฟล์ CSV ภายในฟังก์ชั่นนี้ กล่าวอีกนัยหนึ่งลายนิ้วมือที่มีขนาดต่าง ๆ กลายเป็นไฟล์ CSV 11 คุณลักษณะอันเป็นผลมาจากกระบวนการนี้ แบบจำลองที่จะใช้ได้รับการฝึกฝนและทดสอบด้วยคุณสมบัติที่สร้างขึ้นใหม่เหล่านี้
## 1.4 Feature Extraction
def feature_extraction_file ( data , name , flag ):
features = [[ "braycurtis" ,
"canberra" ,
"chebyshev" ,
"cityblock" ,
"correlation" ,
"cosine" ,
"euclidean" ,
"jensenshannon" ,
"minkowski" ,
"sqeuclidean" ,
"wminkowski" , "real" ]]
for i in tqdm (( data ), position = 0 , leave = True ):
fp1 = fps [ i [ 0 ]]
fp2 = fps [ i [ 1 ]]
feature = feature_extraction ( fp1 , fp2 )
if flag :
feature . append ( i [ 2 ])
else : feature . append ( 0 )
features . append ( feature )
with open ( name , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( features )
#print(features) ## 1.4 Feature Extraction
def feature_extraction ( fp1 , fp2 ):
mac = set ( list ( fp1 . keys ()) + list ( fp2 . keys ()))
mac = { i : 0 for i in mac }
f1 = mac . copy ()
f2 = mac . copy ()
for key in fp1 :
f1 [ key ] = fp1 [ key ]
for key in fp2 :
f2 [ key ] = fp2 [ key ]
f1 = list ( f1 . values ())
f2 = list ( f2 . values ())
braycurtis = scipy . spatial . distance . braycurtis ( f1 , f2 )
canberra = scipy . spatial . distance . canberra ( f1 , f2 )
chebyshev = scipy . spatial . distance . chebyshev ( f1 , f2 )
cityblock = scipy . spatial . distance . cityblock ( f1 , f2 )
correlation = scipy . spatial . distance . correlation ( f1 , f2 )
cosine = scipy . spatial . distance . cosine ( f1 , f2 )
euclidean = scipy . spatial . distance . euclidean ( f1 , f2 )
jensenshannon = scipy . spatial . distance . jensenshannon ( f1 , f2 )
minkowski = scipy . spatial . distance . minkowski ( f1 , f2 )
sqeuclidean = scipy . spatial . distance . sqeuclidean ( f1 , f2 )
wminkowski = scipy . spatial . distance . wminkowski ( f1 , f2 , 1 , np . ones ( len ( f1 )))
output_data = [ braycurtis ,
canberra ,
chebyshev ,
cityblock ,
correlation ,
cosine ,
euclidean ,
jensenshannon ,
minkowski ,
sqeuclidean ,
wminkowski ]
output_data = [ 0 if x != x else x for x in output_data ]
return output_data ในงานนี้มีการสแกนลายนิ้วมือซึ่งมีสัญญาณ RRSI จากสภาพแวดล้อม WiFi ในห้างสรรพสินค้า First Challange ต้องการให้เราประเมินระยะห่างระหว่างการสแกนลายนิ้วมือสองครั้งซึ่งเป็นงานการถดถอย เราใช้ Ann (เครือข่ายประสาทเทียม) ซึ่งได้รับแรงบันดาลใจจากเครือข่ายประสาทชีวภาพ แอนประกอบด้วยสามชั้น เลเยอร์อินพุตเลเยอร์ที่ซ่อนอยู่ (มากกว่าหนึ่ง) และเลเยอร์เอาต์พุต แอนเริ่มต้นด้วยเลเยอร์อินพุตซึ่งรวมถึงข้อมูลการฝึกอบรม (พร้อมคุณสมบัติ) ส่งข้อมูลไปยังเลเยอร์ที่ซ่อนอยู่แรกซึ่งข้อมูลถูกคำนวณโดยน้ำหนักของเลเยอร์ที่ซ่อนอยู่ครั้งแรก ในเลเยอร์ที่ซ่อนอยู่มีการทำซ้ำการคำนวณน้ำหนักกับอินพุตแล้วใช้ฟังก์ชันการเปิดใช้งาน [2] เนื่องจากปัญหาของเราคือการถดถอยเลเยอร์สุดท้ายของเราคือเซลล์ประสาทเอาต์พุตเดี่ยว: เอาต์พุตของมันคือระยะทางที่คาดการณ์ระหว่างคู่ของการสแกนลายนิ้วมือ เลเยอร์ที่ซ่อนอยู่ครั้งแรกของเรามี 64 และที่สองมี 128 เซลล์ประสาท สถาปัตยกรรมทั้งหมดของรุ่นนี้มีการแบ่งปันดังนี้ 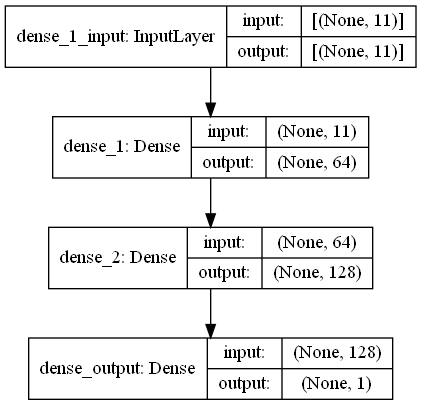
เราทำการเรียนรู้อย่างลึกซึ้งโดยใช้ฟังก์ชั่นสองฟังก์ชั่น create_model กำหนดรูปแบบข้อมูลการฝึกอบรมเพื่อฝึกอบรมแบบจำลองและกำหนดโครงสร้างของโมเดล ฟังก์ชั่น model_features สร้างแบบจำลองที่มีโครงสร้างที่ระบุ โมเดลที่สร้างขึ้นจะถูกบันทึกไว้เพื่อใช้หลังจากได้รับการฝึกฝนโดยฟังก์ชั่น create_model
## 1.5 Model
import scipy . spatial
import pandas as pd
import numpy as np
import matplotlib . pyplot as plt
from tensorflow import keras
from tensorflow . keras . models import Sequential
from tensorflow . keras . layers import Dense
#from keras.utils.vis_utils import plot_model
% matplotlib inline
def model_features ( i , ii ):
model = Sequential ()
model . add ( Dense ( i , input_shape = ( 11 , ), activation = 'relu' , name = 'dense_1' ))
model . add ( Dense ( ii , activation = 'relu' , name = 'dense_2' ))
model . add ( Dense ( 1 , activation = 'linear' , name = 'dense_output' ))
model . compile ( optimizer = 'adam' , loss = 'mse' , metrics = [ 'mae' ])
model . summary ()
#plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)
#print(model.get_config())
return model
def create_model ( name ):
df = pd . read_csv ( name )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X )
y_train = np . array ( df [ df . columns [ - 1 ]])
model = model_features ( 64 , 128 )
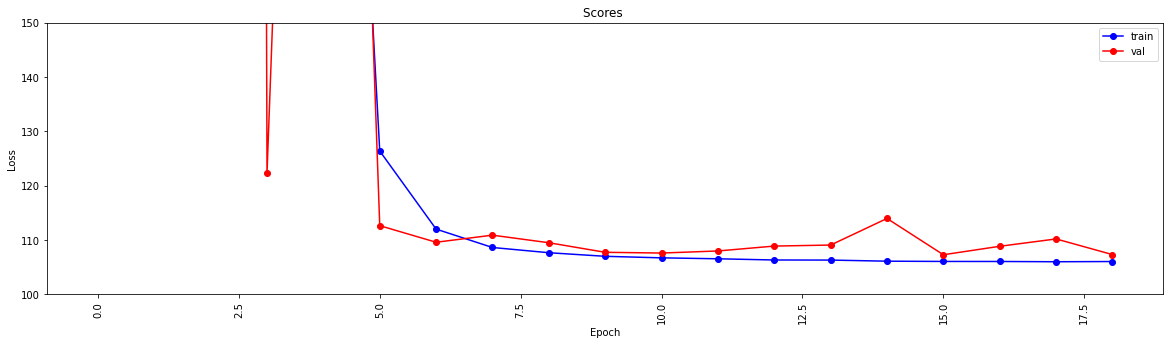
history = model . fit ( X_train , y_train , epochs = 19 , validation_split = 0.5 ) #,batch_size=1)
loss = history . history [ 'loss' ]
val_loss = history . history [ 'val_loss' ]
my_xticks = list ( range ( len ( loss )))
plt . figure ( figsize = ( 20 , 5 ))
plt . plot ( my_xticks , loss , linestyle = '-' , marker = 'o' , color = 'b' , label = "train" )
plt . plot ( my_xticks , val_loss , linestyle = '-' , marker = 'o' , color = 'r' , label = "val" )
plt . title ( "Scores " )
plt . legend ( numpoints = 1 )
plt . ylabel ( "Loss" )
plt . xlabel ( "Epoch" )
plt . xticks ( rotation = 90 )
plt . ylim ([ 100 , 150 ])
plt . show ()
madelname = "./THEMODEL"
model . save ( madelname )
print ( "Model Created!" )
ฟังก์ชั่นนี้ตรวจสอบว่าข้อมูลการฝึกอบรมและการทดสอบได้ผ่านการแยกคุณสมบัติหรือไม่ หากไม่มีมันจะสร้างไฟล์เหล่านี้และโมเดลโดยเรียกฟังก์ชั่นที่เกี่ยวข้อง หลังจากจัดการโมเดลและการสกัดคุณสมบัติทั้งหมดมันจะจัดรูปแบบข้อมูลการทดสอบเพื่อสร้างผลลัพธ์สุดท้าย
## 1.6 Checking the inputs
from numpy import inf
from numpy import nan
def create_new_files ( train , test ):
model_path = "./THEMODEL/"
my_train_file = 'new_train_features.csv'
my_test_file = 'new_test_features.csv'
if os . path . isfile ( my_train_file ) :
pass
else :
print ( "Please wait! Training data feature extraction is in progress... n it will take about 10 minutes" )
feature_extraction_file ( train , my_train_file , 1 )
print ( "TThe training feature extraction completed!!!" )
if os . path . isfile ( my_test_file ) :
pass
else :
print ( "Please wait! Testing data feature extraction is in progress... n it will take about 100-120 minutes" )
feature_extraction_file ( test , my_test_file , 0 )
print ( "The testing feature extraction completed!!!" )
if os . path . isdir ( model_path ):
pass
else :
print ( "Please wait! Creating the deep learning model... n it will take about 10 minutes" )
create_model ( my_train_file )
print ( "The model file created!!! n n n " )
model = keras . models . load_model ( model_path )
df = pd . read_csv ( my_test_file )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X_train = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X_train )
y_train = np . array ( df [ df . columns [ - 1 ]])
predicted = model . predict ( X_train )
print ( "Please wait! Creating resuşts... " )
return predicted ขั้นตอนนี้ทริกเกอร์การแยกคุณสมบัติและกระบวนการสร้างแบบจำลองและช่วยให้กระบวนการทั้งหมดเริ่มต้นขึ้น ดังนั้นการใช้ IDS จากไฟล์ test1_test.csv มันเติมคอลัมน์ที่สาม (การกระจัด) ด้วยระยะทางโดยประมาณสำหรับคู่ลายนิ้วมือนี้และบันทึกไฟล์นี้ในไดเรกทอรีด้วยชื่อ TASK1-MySubmission.csv
## 1.7 Submission
distance_estimate = create_new_files ( train_data , test_ids )
count = 0
output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
output_data . append ([ id1 , id2 , distance_estimate [ count ][ 0 ]])
count += 1
print ( "Process finished. Preparing result file ..." )
with open ( "TASK1-MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )
print ( "The results are ready. n See MySubmission.csv" ) Please wait! Creating the deep learning model...
it will take about 10 minutes
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 64) 768
_________________________________________________________________
dense_2 (Dense) (None, 128) 8320
_________________________________________________________________
dense_output (Dense) (None, 1) 129
=================================================================
Total params: 9,217
Trainable params: 9,217
Non-trainable params: 0
_________________________________________________________________
Epoch 1/19
13748/13748 [==============================] - 30s 2ms/step - loss: 2007233.6250 - mae: 161.3013 - val_loss: 218.8822 - val_mae: 11.5630
Epoch 2/19
13748/13748 [==============================] - 27s 2ms/step - loss: 24832.6309 - mae: 53.9385 - val_loss: 123437.0859 - val_mae: 307.2885
Epoch 3/19
13748/13748 [==============================] - 26s 2ms/step - loss: 4028.0859 - mae: 29.9960 - val_loss: 3329.2024 - val_mae: 49.9126
Epoch 4/19
13748/13748 [==============================] - 27s 2ms/step - loss: 904.7919 - mae: 17.6284 - val_loss: 122.3358 - val_mae: 6.8169
Epoch 5/19
13748/13748 [==============================] - 25s 2ms/step - loss: 315.7050 - mae: 11.9098 - val_loss: 404.0973 - val_mae: 15.2033
Epoch 6/19
13748/13748 [==============================] - 26s 2ms/step - loss: 126.3843 - mae: 7.8173 - val_loss: 112.6499 - val_mae: 7.6804
Epoch 7/19
13748/13748 [==============================] - 27s 2ms/step - loss: 112.0149 - mae: 7.4220 - val_loss: 109.5987 - val_mae: 7.1964
Epoch 8/19
13748/13748 [==============================] - 26s 2ms/step - loss: 108.6342 - mae: 7.3271 - val_loss: 110.9016 - val_mae: 7.6862
Epoch 9/19
13748/13748 [==============================] - 26s 2ms/step - loss: 107.6721 - mae: 7.2827 - val_loss: 109.5083 - val_mae: 7.5235
Epoch 10/19
13748/13748 [==============================] - 27s 2ms/step - loss: 107.0110 - mae: 7.2290 - val_loss: 107.7498 - val_mae: 7.1105
Epoch 11/19
13748/13748 [==============================] - 29s 2ms/step - loss: 106.7296 - mae: 7.2158 - val_loss: 107.6115 - val_mae: 7.1178
Epoch 12/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.5561 - mae: 7.2039 - val_loss: 107.9937 - val_mae: 6.9932
Epoch 13/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.3344 - mae: 7.1905 - val_loss: 108.8941 - val_mae: 7.4530
Epoch 14/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.3188 - mae: 7.1927 - val_loss: 109.0832 - val_mae: 7.5309
Epoch 15/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.1150 - mae: 7.1829 - val_loss: 113.9741 - val_mae: 7.9496
Epoch 16/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.0676 - mae: 7.1788 - val_loss: 107.2984 - val_mae: 7.2192
Epoch 17/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0614 - mae: 7.1733 - val_loss: 108.8553 - val_mae: 7.4640
Epoch 18/19
13748/13748 [==============================] - 28s 2ms/step - loss: 106.0113 - mae: 7.1790 - val_loss: 110.2068 - val_mae: 7.6562
Epoch 19/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0519 - mae: 7.1791 - val_loss: 107.3276 - val_mae: 7.0981
INFO:tensorflow:Assets written to: ./THEMODELassets
Model Created!
The model file created!!!
Please wait! Creating resuşts...
100%|████████████████████████████████████████████████████████████████████| 5160445/5160445 [00:08<00:00, 610910.29it/s]
Process finished. Preparing result file ...
The results are ready.
See MySubmission.csv
เนื่องจากตอนนี้เรามีตัวชี้วัดสำหรับการประเมินระยะทาง wifi งานต่อไปของเราคือการแยกวิถีการเคลื่อนที่จากห้าง แต่เราขอแนะนำวิธีการจัดกลุ่มกราฟ
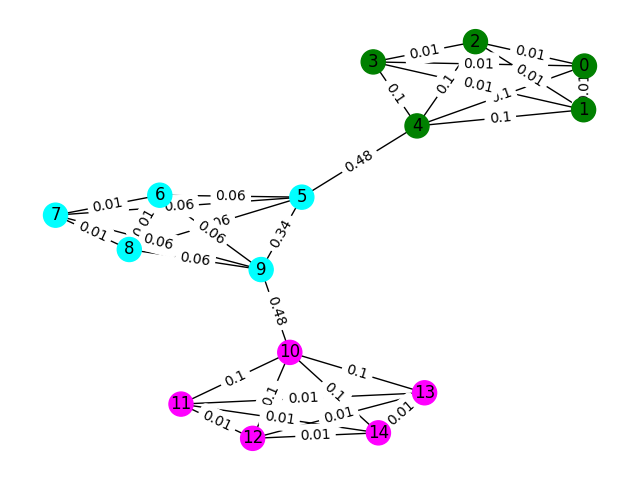
พิจารณาลายนิ้วมือ WiFi แต่ละอันในข้อมูลเป็นโหนดในกราฟและเราสามารถสร้างขอบด้วยลายนิ้วมืออื่น ๆ ในกราฟโดยการประเมินความคล้ายคลึงกันสองลายนิ้วมือ เราสามารถกำหนดน้ำหนักได้สูงให้กับขอบที่เรามีความคล้ายคลึงกันสูงระหว่างลายนิ้วมือและน้ำหนักต่ำ (หรือไม่มีขอบ) ระหว่างที่ไม่คล้ายกัน ในทางทฤษฎีตัวชี้วัดความคล้ายคลึงกันที่แม่นยำอย่างสมบูรณ์จะแยกจากกันเล็กน้อยเนื่องจากเราสามารถแยกขอบทั้งหมดที่มากกว่า 4 เมตร (ประมาณความสูงประมาณ 1 ชั้นของอาคาร) ในความเป็นจริงมันเป็นไปได้ว่าเราจะสร้างขอบเท็จระหว่างพื้นและเราจะต้องทำลายขอบเหล่านี้
เริ่มต้นด้วยตัวอย่างง่ายๆ พิจารณากราฟด้านล่างที่สีของโหนดแสดงการจำแนกพื้นอย่างแท้จริงของลายนิ้วมือและขอบสะท้อนให้เห็นว่าเราเชื่อว่าโหนดเหล่านี้มีอยู่บนชั้นเดียวกัน สำหรับแบบฝึกหัดนี้เราได้ติดฉลากไว้ล่วงหน้าแต่ละขอบด้วย "คะแนนระหว่างความเป็นตัวชี้วัดที่นับจำนวนครั้งที่ขอบนี้เดินโดยใช้เส้นทางที่สั้นที่สุดระหว่างสองโหนดใด ๆ ในกราฟ โดยทั่วไปแล้วสิ่งนี้จะเปิดเผยขอบที่บ่งบอกถึงการเชื่อมต่อที่สูงและอาจเป็นผู้สมัครสำหรับการกำจัด
ในตัวอย่างนี้ให้ใช้คะแนนขอบระหว่างความเป็นเนสเพื่อตรวจจับการสื่อสารกราฟ ส่งคืนรายการรายการที่แต่ละ sublist มีรหัสโหนดของชุมชน โปรดทราบว่านี่เป็นเพียงเพื่อช่วยให้คุณเข้าใจปัญหาและไม่นับสำหรับการแก้ปัญหาจริง
def detect_communities ( Graph ):
## This function should return a list of lists containing
## the node ids of the communities that you have detected.
eb_score = nx . edge_betweenness_centrality ( G )
raise NotImplementedError import networkx as nx
from metrics import check_result
G = nx . read_adjlist ( "graph.adjlist" )
communities = detect_communities ( G )
if check_result ( communities ):
print ( "Correct!" )
else :
print ( "Try again" ) ข้อมูลการฝึกอบรมตัวอย่างสำหรับปัญหานี้คือชุดลายนิ้วมือ 1,06981 ( task2_train_fingerprints.json ) และบางขอบระหว่างพวกเขา เราได้จัดเตรียมไฟล์ที่ระบุสามประเภทที่แตกต่างกันซึ่งทั้งหมดควรได้รับการปฏิบัติแตกต่างกัน
task2_train_steps.csv ระบุขอบที่เชื่อมต่อขั้นตอนที่ตามมาภายในวิถี ขอบเหล่านี้ควรได้รับความไว้วางใจอย่างมากเนื่องจากมีความมั่นใจว่ามีการบันทึกลายนิ้วมือสองครั้งจากชั้นเดียวกัน
task2_train_elevations.csv ระบุตรงข้ามของขั้นตอน ระดับความสูงเหล่านี้บ่งชี้ว่าลายนิ้วมือเกือบจะมาจากพื้นแตกต่างกันอย่างแน่นอน คุณสามารถคาดการณ์ได้ว่าถ้าลายนิ้วมือ
task2_train_estimated_wifi_distances.csv เป็นระยะทางที่คำนวณล่วงหน้าซึ่งเราคำนวณโดยใช้ตัวชี้วัดระยะทางของเราเอง ตัวชี้วัดนี้ไม่สมบูรณ์และเรารู้ว่าขอบเหล่านี้จำนวนมากจะไม่ถูกต้อง (เช่นพวกเขาจะเชื่อมต่อสองชั้นเข้าด้วยกัน) เราขอแนะนำว่าในขั้นต้นคุณใช้ขอบในไฟล์นี้เพื่อสร้างกราฟเริ่มต้นของคุณและคำนวณวิธีแก้ปัญหาบางอย่าง อย่างไรก็ตามหากคุณได้รับคะแนนสูงใน Task1 คุณอาจพิจารณาคำนวณระยะทาง WiFi ของคุณเองเพื่อสร้างกราฟ
กราฟของคุณสามารถเป็นหนึ่งในสองระดับของรายละเอียดไม่ว่าจะเป็นระดับวิถีหรือระดับลายนิ้วมือคุณสามารถเลือกสิ่งที่คุณต้องการใช้เป็นตัวแทน แต่ท้ายที่สุดเราต้องการทราบ กลุ่มวิถี ระดับวิถีจะมีทุกโหนดเป็นวิถีและขอบระหว่างโหนดจะเกิดขึ้นหากลายนิ้วมือในวิถีของพวกเขามีความคล้ายคลึงกันสูง ระดับลายนิ้วมือจะมีลายนิ้วมือแต่ละครั้งเป็นโหนด คุณสามารถค้นหารหัสวิถีของลายนิ้วมือโดยใช้ task2_train_lookup.json เพื่อแปลงระหว่างการเป็นตัวแทน
เพื่อช่วยให้คุณดีบักและฝึกฝนโซลูชันของคุณเราได้ให้ความจริงพื้นฐานสำหรับวิถีบางอย่างใน task2_train_GT.json ในไฟล์นี้คีย์คือรหัสวิถี (เหมือนกับใน task2_train_lookup.json ) และค่าเป็นรหัสชั้นจริงของอาคาร
ชุดทดสอบเป็นรูปแบบเดียวกับชุดการฝึกอบรม (สำหรับอาคารแยกต่างหากเราจะไม่ทำให้มันง่ายมาก)) แต่เราไม่ได้รวมไฟล์ความจริงภาคพื้นดินที่เทียบเท่า สิ่งนี้จะถูกระงับเพื่อให้เราได้คะแนนโซลูชันของคุณ
คะแนนที่ควรพิจารณา
ในส่วนนี้เราจะให้รหัสตัวอย่างเพื่อเปิดไฟล์และสร้างกราฟทั้งสองประเภท
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/train"
with open ( os . path . join ( path_to_data , "task2_train_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_train_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_train_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_train_lookup.json" )
gt_path = os . path . join ( path_to_data , "task2_train_GT.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f )
with open ( gt_path ) as f :
gt = json . load ( f )
นี่เป็นวิธีหนึ่งในการสร้างกราฟระดับลายนิ้วมือซึ่งแต่ละโหนดในกราฟเป็นลายนิ้วมือ เราได้เพิ่มน้ำหนักขอบที่สอดคล้องกับระยะทางโดยประมาณ/จริงจากขอบ WiFi และ PDR ตามลำดับ เราได้เพิ่มขอบระดับความสูงเพื่อระบุความสัมพันธ์นี้ คุณอาจต้องการบังคับใช้อย่างชัดเจนว่า ไม่มี ขอบเหล่านี้ (หรือขอบระดับความสูงที่ถูกต้องระหว่างวิถี) เมื่อพัฒนาโซลูชันของคุณ
G = nx . Graph ()
for id1 , id2 , dist in tqdm ( steps ):
G . add_edge ( id1 , id2 , ty = "s" , weight = dist )
for id1 , id2 , dist in tqdm ( wifi ):
G . add_edge ( id1 , id2 , ty = "w" , weight = dist )
for id1 , id2 in tqdm ( elevs ):
G . add_edge ( id1 , id2 , ty = "e" )กราฟวิถีไม่ง่ายอย่างที่คุณต้องการคิดวิธีที่จะเป็นตัวแทนของการเชื่อมต่อ WiFi จำนวนมากระหว่างวิถี ในกราฟตัวอย่างด้านล่างเราใช้ระยะทางเฉลี่ยเป็นน้ำหนัก แต่นี่เป็นตัวแทนที่ดีที่สุดหรือไม่?
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])การส่งของคุณควรเป็นไฟล์ CSV ที่วิถีที่คุณเชื่อว่าอยู่บนชั้นเดียวกันมีดัชนีของพวกเขาในแถวเดียวกันแยกกันโดยเครื่องหมายจุลภาค แต่ละคลัสเตอร์ใหม่จะถูกป้อนในแถวใหม่
ตัวอย่างเช่นดูรายการสุ่มด้านล่าง
import random
random_data = []
n_clusters = random . randint ( 50 , 100 )
for i in range ( 0 , n_clusters ):
random_data . append ([])
for traj in set ( fp_lookup . values ()):
cluster = random . randint ( 0 , n_clusters - 1 )
random_data [ cluster ]. append ( traj )
with open ( "MyRandomSubmission.csv" , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( random_data )ขั้นตอนในงาน 2 สามารถสรุปได้ดังนี้:
Node2vecTASK2-Mysubmission.csv ) จัดทำขึ้นตามวิถีของ IDขั้นตอนเหล่านี้แสดงไว้ในภาพด้านล่าง

เราใช้ Python 3.6.5 เพื่อสร้างไฟล์แอปพลิเคชัน เรารวมโมดูลเพิ่มเติมบางอย่างที่ไม่รวมอยู่ในไฟล์ตัวอย่างที่ให้ไว้ในช่วงเริ่มต้นของการแข่งขัน โมดูลเหล่านี้สามารถแสดงรายการเป็น:
| โมล | งาน |
|---|---|
| Scikit-learn | การเรียนรู้ของเครื่องและการเตรียมข้อมูล |
| node2vec | การเรียนรู้คุณสมบัติที่ปรับขนาดได้สำหรับเครือข่าย |
| นม | การดำเนินการทางคณิตศาสตร์ |
เราเริ่มต้นด้วยการติดตั้งโมดูลเหล่านี้เป็นขั้นตอนแรก
## 2.1 Installing modules
!p ip install node2vec
!p ip install scikit - learn
!p ip install numpy ในขั้นตอนนี้เราได้แก้ไขเมล็ดสุ่มที่เกี่ยวข้องที่จะใช้เพื่อให้ได้ผลลัพธ์ที่ทำซ้ำได้ ด้วยวิธีนี้เราได้จัดเตรียมเส้นทางที่กำหนดไว้ซึ่งเราได้รับผลลัพธ์เดียวกันในทุกการวิ่ง อย่างไรก็ตามจากการสังเกตของเราผลลัพธ์ที่ได้จากคอมพิวเตอร์ที่แตกต่างกันอาจแตกต่างกันเล็กน้อย (± 1%)
## 2.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )ในส่วนนี้ไฟล์ที่ให้สำหรับข้อมูลการทดสอบจะถูกโหลด
wifi ใช้ ID และน้ำหนักจาก task2_test_estimated_wifi_distances.csvsteps จะใช้รหัสและน้ำหนักจากไฟล์ task2_test_steps.csvelevs ใช้ ID จาก FILE task2_test_elevations.csvfp_lookup ได้รับ ID และวิถีจากไฟล์ task2_test_lookup.json เราไม่ต้องการวิธีการคำนวณระยะทางโดยประมาณที่กำหนดใน WiFi ด้วยแบบจำลองที่เราได้รับใน TASK1 เนื่องจากผลลัพธ์ที่เราได้รับจากกระบวนการนี้ไม่ได้สร้างความแตกต่างอย่างมีนัยสำคัญ นั่นเป็นเหตุผลที่เราไม่ได้ใช้ไฟล์ task2_test_fingerprints.json ในงานที่ดีที่สุดของเรา
## 2.3 Loading the data
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/test"
with open ( os . path . join ( path_to_data , "task2_test_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_test_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_test_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_test_lookup.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f ) 3773297it [00:19, 191689.25it/s]
2767it [00:00, 52461.27it/s]
139537it [00:00, 180082.01it/s]
เราใช้ระยะทางเฉลี่ยเป็นน้ำหนักเมื่อสร้างกราฟวิถี เราใช้ตัวอย่างที่ให้ไว้สำหรับงาน 2 ( Task2-IPS-Challenge-2021.ipynb ) สำหรับกระบวนการนี้ เราบันทึกกราฟผลลัพธ์ ( B ) เป็นรายการ adjacency ในไดเรกทอรี (เป็น my.adjlist )
## 2.3 Generating the Trajectory graph.
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])
nx . write_adjlist ( B , "my.adjlist" ) 100%|████████████████████████████████████████████████████████████████████| 3773297/3773297 [00:27<00:00, 135453.95it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████| 2767/2767 [00:00<?, ?it/s]
ก่อนที่จะให้รายการ adjacency เป็นอินพุตไปยังอัลกอริทึมการเรียนรู้ของเครื่องเราจะแปลงโหนดเป็นเวกเตอร์ ในงานของเราเราใช้ Node2VEC เป็นวิธีการฝังกราฟอัลกอริทึมวิธีการเสนอโดย Grover & Leskovec ในปี 2559 [3] Node2VEC เป็นอัลกอริทึมกึ่งผู้ดูแลสำหรับการเรียนรู้คุณสมบัติของโหนดในเครือข่าย Node2Vec ถูกสร้างขึ้นตามเทคนิคการข้ามกรัมซึ่งเป็นวิธีการ NLP ที่มีแรงบันดาลใจในแนวคิดโครงสร้างการกระจายตามความคิดหากคำต่าง ๆ ที่ใช้ในบริบทที่คล้ายกันพวกเขาอาจมีความหมายคล้ายกันและมีความสัมพันธ์ที่ชัดเจนระหว่างพวกเขา เทคนิคการข้ามกรัมใช้คำตรงกลาง (อินพุต) เพื่อทำนายเพื่อนบ้าน (เอาท์พุท) ในขณะที่คำนวณความน่าจะเป็นของสภาพแวดล้อมตามขนาดหน้าต่างที่กำหนด (ลำดับที่ต่อเนื่องกันของรายการก่อนหลังจุดศูนย์กลาง) กล่าวอีกนัยหนึ่ง ซึ่งแตกต่างจากวิธี NLP ระบบ Node2VEC ไม่ได้ถูกป้อนด้วยคำที่มีโครงสร้างเชิงเส้น แต่โหนดและขอบซึ่งมีโครงสร้างกราฟิกแบบกระจาย โครงสร้างหลายมิตินี้ทำให้ Embeddings ซับซ้อนและมีราคาแพง แต่ Node2VEC ใช้การสุ่มตัวอย่างเชิงลบด้วยการเพิ่มประสิทธิภาพการไล่ระดับสีแบบสุ่ม (SGD) เพื่อจัดการกับมัน นอกจากนี้วิธีการเดินแบบสุ่มใช้เพื่อตรวจจับตัวอย่างโหนดใกล้เคียงของโหนดต้นทางในโครงสร้างไม่เชิงเส้น
ในการศึกษาของเราก่อนอื่นเราได้ทำการแสดงเวกเตอร์ของความสัมพันธ์ของโหนดในพื้นที่มิติต่ำโดยการสร้างแบบจำลองด้วย node2vec จากระยะทางที่กำหนดของสองโหนด (น้ำหนัก) จากนั้นเราใช้เอาต์พุตของ node2vec (กราฟฝังตัว) ซึ่งมีเวกเตอร์ของโหนดเพื่อป้อนอัลกอริทึมการจัดกลุ่ม k-mean แบบดั้งเดิม
พารามิเตอร์ที่เราใช้ใน NOD2VEC สามารถแสดงรายการดังนี้:
| พารามิเตอร์ไฮเปอร์ | ค่า |
|---|---|
| ขนาด | 32 |
| walk_length | 15 |
| num_walks | 100 |
| คนงาน | 1 |
| เมล็ด | 0 |
| หน้าต่าง | 10 |
| min_count | 1 |
| batch_words | 4 |
โมเดล Node2Vec ใช้รายการ adjacency เป็นอินพุตและส่งออกเวกเตอร์ขนาด 32 ในส่วนนี้ไฟล์ node.py ถูกสร้างและเรียกใช้ใน Jupyter Notebook มีสองเหตุผลว่าทำไมการทำงานภายนอกให้ดีกว่าในเซลล์สมุดบันทึก Jupyter
Node2vec เป็นวิธีการคำนวณที่มีราคาแพงมากข้อผิดพลาด RAM Overflow นั้นค่อนข้างเป็นไปได้ถ้า Run Inside Inside Jupyter Notebook การสร้างและเรียกใช้โมเดล Node2vec ภายนอกหลีกเลี่ยงข้อผิดพลาดนี้ เซลล์ด้านล่างสร้างไฟล์ชื่อ node.py ไฟล์นี้สร้างโมเดล Node2VEC โมเดลนี้ใช้รายการ adjacency ( my.adjlist ) เป็นอินพุตและสร้างไฟล์เวกเตอร์ 32 มิติเป็นเอาต์พุต ( vectors.emb )
สำคัญ! รหัสด้านล่างควรทำงานในการแจกแจง Linux (ทดสอบใน Google Colab และ Ubuntu)
# 2.4 Converting nodes to vectors
# A folder named tmp is created. This folder is essential for the node2vec model to use less RAM.
try :
if not os . path . exists ( "tmp" ):
os . makedirs ( "tmp" )
except OSError :
print ( "The folder could not be created! n Please manually create the " tmp " folder in the directory" )
node = """
# importing related modules
from node2vec import Node2Vec
import networkx as nx
#importing adjacency list file as B
B = nx.read_adjlist("my.adjlist")
seed_value=0
# Specifying the input and hyperparameters of the node2vec model
node2vec = Node2Vec(B, dimensions=32, walk_length=15, num_walks=100, workers=1,seed=seed_value,temp_folder = './tmp')
#Assigning/specifying random seeds
import os
os.environ['PYTHONHASHSEED']=str(seed_value)
import random
random.seed(seed_value)
import numpy as np
np.random.seed(seed_value)
# creation of the model
model = node2vec.fit(window=10, min_count=1, batch_words=4,seed=seed_value)
# saving the output vector
model.wv.save_word2vec_format("vectors.emb")
# save the model
model.save("vectorMODEL")
"""
f = open ( "node.py" , "w" )
f . write ( node )
f . close ()
! PYTHONHASHSEED = 0 python3 node . py หลังจากสร้างไฟล์เวกเตอร์ของเราแล้วเราอ่านไฟล์นี้ ( vectors.emb ) ไฟล์นี้ประกอบด้วย 33 คอลัมน์ คอลัมน์แรกคือหมายเลขโหนด (ID) และยังคงเป็นค่าเวกเตอร์ โดยการเรียงลำดับไฟล์ทั้งหมดตามคอลัมน์แรกเราจะส่งคืนโหนดไปยังคำสั่งซื้อเดิม จากนั้นเราจะลบคอลัมน์ ID นี้ซึ่งเราจะไม่ใช้อีกต่อไป ดังนั้นเราให้รูปร่างสุดท้ายของข้อมูลของเรา ข้อมูลของเราพร้อมที่จะใช้ในแอปพลิเคชันการเรียนรู้ของเครื่อง
# 2.4 Reshaping data
vec = np . loadtxt ( "vectors.emb" , skiprows = 1 )
print ( "shape of vector file: " , vec . shape )
print ( vec )
vec = vec [ vec [:, 0 ]. argsort ()];
vec = vec [ 0 : vec . shape [ 0 ], 1 : vec . shape [ 1 ]] shape of vector file: (11162, 33)
[[ 9.1200000e+03 3.9031842e-01 -4.7147268e-01 ... -5.7490986e-02
1.3059708e-01 -5.4280665e-02]
[ 6.5320000e+03 -3.5591956e-02 -9.8558587e-01 ... -2.7217887e-02
5.6435770e-01 -5.7787680e-01]
[ 5.6580000e+03 3.5879680e-01 -4.7564098e-01 ... -9.7607370e-02
1.5506668e-01 1.1333219e-01]
...
[ 2.7950000e+03 1.1724627e-02 1.0272172e-02 ... -4.5596390e-04
-1.1507459e-02 -7.6738600e-04]
[ 4.3380000e+03 1.2865483e-02 1.2103912e-02 ... 1.6619096e-03
1.3672550e-02 1.4605848e-02]
[ 1.1770000e+03 -1.3707868e-03 1.5238028e-02 ... -5.9994194e-04
-1.2986251e-02 1.3706315e-03]]
TASK-2 เป็นปัญหาการจัดกลุ่ม หลักฐานที่เราต้องตัดสินใจเมื่อแก้ปัญหานี้คือจำนวนกลุ่มที่เราควรแบ่งออกเป็นจำนวนกลุ่ม สำหรับสิ่งนี้เราลองหมายเลขคลัสเตอร์ที่แตกต่างกันและเปรียบเทียบคะแนนที่เราได้รับ กราฟด้านล่างแสดงการเปรียบเทียบจำนวนกลุ่มและคะแนนที่ได้รับ ดังที่เห็นได้จากกราฟนี้จำนวนกลุ่มเพิ่มขึ้นอย่างต่อเนื่องระหว่าง 5 และ 21 โดยมีความผันผวนข้อยกเว้นบางอย่างและเสถียรหลังจาก 21 ด้วยเหตุผลนี้เราจึงมุ่งเน้นไปที่จำนวนกลุ่มระหว่าง 21 และ 23 ในการศึกษาของเรา
# 2.5 Determine the number of clusters
import numpy as np
import matplotlib . pyplot as plt
import seaborn as sns
import matplotlib
% matplotlib inline
sns . set_style ( "whitegrid" )
agglom = [ 24.69 , 28.14 , 28.14 , 28.14 , 30 , 33.33 , 40.88 , 38.70 , 40 , 40 , 40 , 29.12 , 45.85 , 45.85 , 48.00 , 50.17 , 57.83 , 57.83 , 57.83 ]
plt . figure ( figsize = ( 10 , 5 ))
plt . plot ( range ( 5 , 24 ), agglom )
matplotlib . pyplot . xticks ( range ( 5 , 24 ))
plt . title ( 'Number of clusters and performance relationship' )
plt . xlabel ( 'Number of clusters' )
plt . ylabel ( 'Score' )
plt . show ()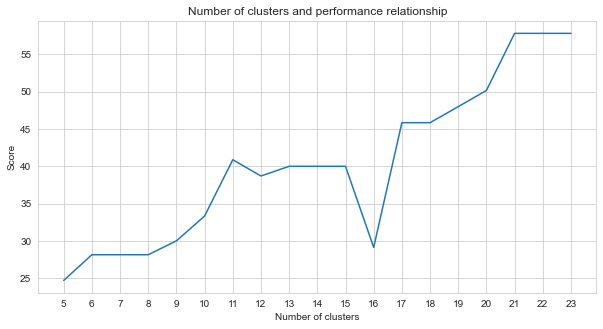
ในบรรดาวิธีการเรียนรู้ของเครื่องจักรที่ไม่ได้รับการดูแลที่เราลอง (เช่น K-Means, การจัดกลุ่ม agglomerative, การแพร่กระจายความสัมพันธ์, การเปลี่ยนแปลงหมายถึง, การจัดกลุ่มสเปกตรัม, DBSCAN, เลนส์, เบิร์ช, k-mean มินิแบทช์) เราได้ผลลัพธ์ที่ดีที่สุดโดยใช้ k-means มี 23 กลุ่ม
K-mean เป็นอัลกอริทึมการจัดกลุ่มเป็นหนึ่งในเทคนิคการเรียนรู้ของเครื่องจักรพื้นฐานและไม่ได้รับการดูแลแบบดั้งเดิมซึ่งทำให้สมมติฐานเพื่อค้นหาองค์ประกอบที่เป็นเนื้อเดียวกันหรือเป็นธรรมชาติ (กลุ่ม) โดยใช้ข้อมูลที่ไม่มีป้ายกำกับ กลุ่มคือการกำหนดจุด (โหนดในข้อมูลของเรา) จัดกลุ่มเข้าด้วยกันซึ่งมีความคล้ายคลึงกันเป็นพิเศษ K-mean ต้องการจำนวนเป้าหมายของ centroids ซึ่งหมายถึงจำนวนกลุ่มที่ควรแบ่งออกเป็นกลุ่ม อัลกอริทึมเริ่มต้นด้วยกลุ่มของเซนทรอยด์ที่ได้รับมอบหมายแบบสุ่มจากนั้นดำเนินการซ้ำเพื่อค้นหาตำแหน่งที่ดีที่สุดของพวกเขา อัลกอริทึมกำหนดคะแนน/โหนดให้กับเซนทรอยด์ที่ได้รับการแต่งตั้งโดยใช้ผลรวมของสี่เหลี่ยมของสมาชิกของคะแนนนี่คือการอัปเดตและการย้ายถิ่นฐานต่อไป [4] ในตัวอย่างของเราจำนวนเซนทรอยด์สะท้อนจำนวนพื้น ควรสังเกตว่าสิ่งนี้ไม่ได้ให้ข้อมูลเกี่ยวกับลำดับของพื้น
ด้านล่างนี้แอปพลิเคชัน K-mean ได้รับการสร้างขึ้นมา 23 กลุ่ม
# 2.5 Best result
from sklearn import cluster
import time
ML_results = []
k_clusters = 23
algorithms = {}
algorithms [ 'KMeans' ] = cluster . KMeans ( n_clusters = k_clusters , random_state = 10 )
second = time . time ()
for model in algorithms . values ():
model . fit ( vec )
ML_results = list ( model . labels_ )
print ( model , time . time () - second ) KMeans(n_clusters=23, random_state=10) 1.082334280014038
เอาต์พุตของอัลกอริทึมการเรียนรู้ของเครื่องจะกำหนดว่าการรวมกลุ่มลายนิ้วมือใด แต่สิ่งที่เราต้องการคือการรวมกลุ่มวิถี ดังนั้นลายนิ้วมือเหล่านี้จะถูกแปลงเป็นวิถีของพวกเขาโดยใช้ตัวแปร fp_lookup เอาต์พุตนี้ถูกประมวลผลลงในไฟล์ TASK2-Mysubmission.csv
## 2.6 Submission
result = {}
for ii , i in enumerate ( set ( fp_lookup . values ())):
result [ i ] = ML_results [ ii ]
ters = {}
for i in result :
if result [ i ] not in ters :
ters [ result [ i ]] = []
ters [ result [ i ]]. append ( i )
else :
ters [ result [ i ]]. append ( i )
final_results = []
for i in ters :
final_results . append ( ters [ i ])
name = "TASK2-Mysubmission.csv"
with open ( name , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( final_results )
print ( name , "file is ready!" ) TASK2-Mysubmission.csv file is ready!
[1] P. Virtanen และ Scipy 1.0 ผู้มีส่วนร่วม Scipy 1.0: อัลกอริทึมพื้นฐานสำหรับการคำนวณทางวิทยาศาสตร์ใน Python วิธีการธรรมชาติ, 17: 261--272, 2020
[2] A. Geron, การเรียนรู้ของเครื่องด้วยมือกับ Scikit-Learn, Keras และ TensorFlow: แนวคิดเครื่องมือและเทคนิคในการสร้างระบบอัจฉริยะ O'Reilly Media, 2019
[3] A. Grover, J. Leskovec การประชุมนานาชาติ ACM SIGKDD เกี่ยวกับการค้นพบความรู้และการขุดข้อมูล (KDD), 2016
[4] Jin X. , Han J. (2011) K-means Clustering ใน: Sammut C. , Webb GI (eds) สารานุกรมการเรียนรู้ของเครื่อง Springer, Boston, MA https://doi.org/10.1007/978-0-387-30164-8_425


