Noise Reduction
1.0.0

เกี่ยวกับโครงการ
ซ้อนเทค
โครงสร้างไฟล์
เริ่มต้น
ผลลัพธ์และการสาธิต
งานในอนาคต
ผู้มีส่วนร่วม
กิตติกรรมประกาศและทรัพยากร
ใบอนุญาต
เสียงที่จำเป็นต้องถูกลบออกซึ่งเกิดขึ้นตามธรรมชาติเช่นเสียงรบกวนที่ไม่ใช่สิ่งแวดล้อมซึ่งถูกลบออกด้วยสัญญาณ denoising อ้างอิงเอกสารนี้นอกจากนี้ยังบล็อกนี้เกี่ยวกับการลดเสียงรบกวน AI
ใช้ห้องสมุด Librosa สำหรับ manupulation เสียง
สำหรับสัญญาณเสียงที่เราใช้ Scipy
Matplotlib ใช้ในการจัดการข้อมูลและแสดงภาพสัญญาณ
ส่วนที่เหลือคือ numpy สำหรับการดำเนินการทางคณิตศาสตร์, คลื่นสำหรับการทำงานบนไฟล์คลื่น
Noise Reduction ├───docs ## Documents and Images │ └───Input Audio file ├─── Project Details │ | │ ├─── │ │ ├───Research papers │ │ ├───Linear Algebra │ │ ├───Neural networks & Deep Learning │ │ ├───Project Documentation │ │ ├───AI Noise Reduction Blog │ │ ├───AI Noise Reduction Report │ │ └───Code Implementation │ │ ├───AI Noise Reduction.py │ │ ├───audio.wav │ │ ├───Resources
ทดสอบบน Windows
git clone https://github.com/dhriti03/noise-reduction.gitcd เสียงลดลง
ในสมุดบันทึกของคุณติดตั้งไลบรารีบางอย่าง
Pip Install Wave PIP ติดตั้ง Librosa PIP ติดตั้ง scipy.io PIP ติดตั้ง matplotlib.pyplot
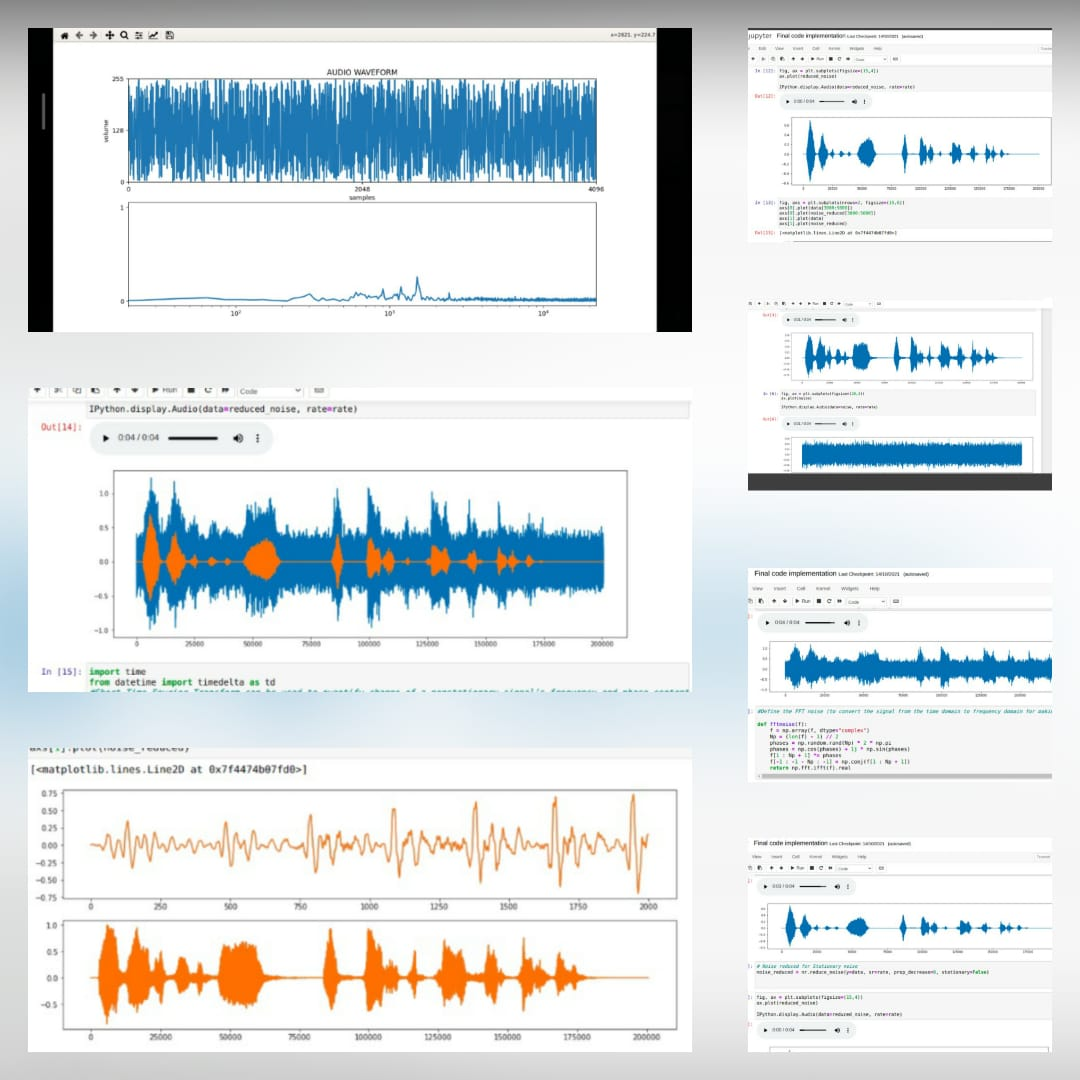
*นี่คือไฟล์เสียงดั้งเดิม * 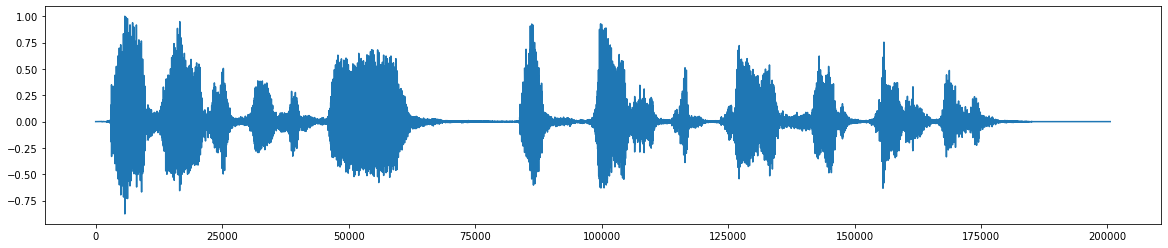 *หลังจากเพิ่มเสียงรบกวน *
*หลังจากเพิ่มเสียงรบกวน * 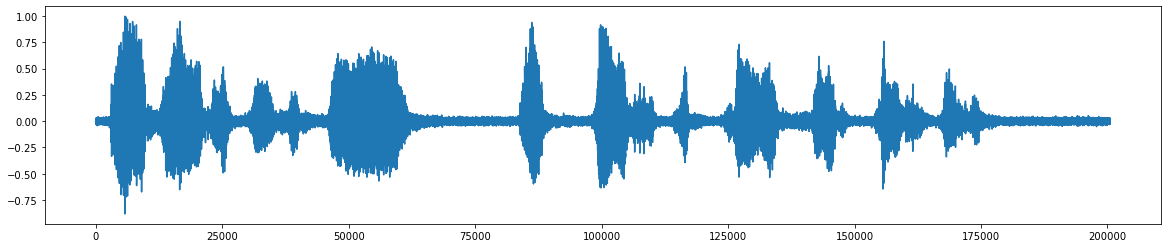 *สัญญาณเสียงสุดท้ายหลังจากลบเสียงรบกวน *
*สัญญาณเสียงสุดท้ายหลังจากลบเสียงรบกวน *  *ผังงานสำหรับโครงการ *
*ผังงานสำหรับโครงการ * 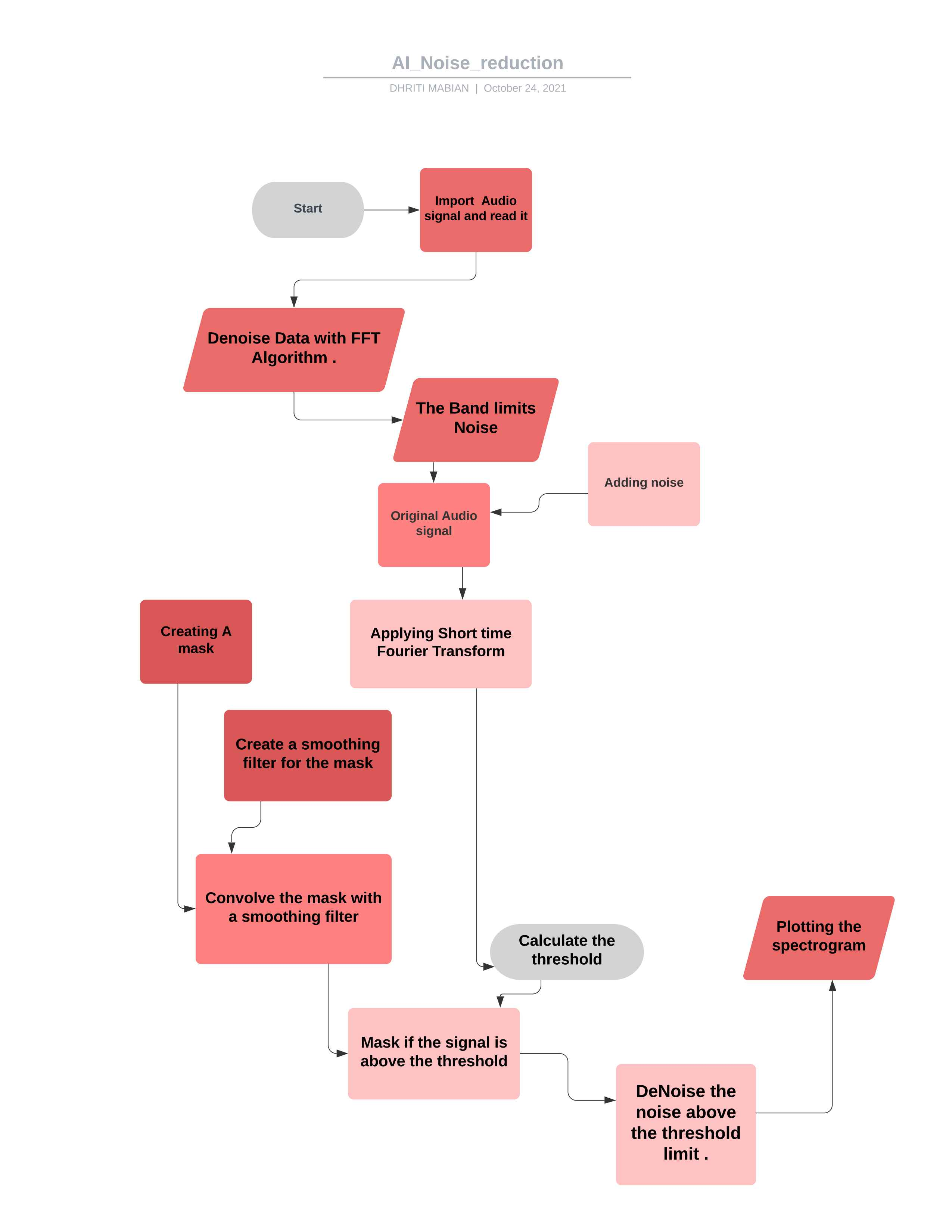
ในการจัดการรหัสตามความต้องการของคุณคุณสามารถใช้มันเพื่อควบคุมป้ายเสียงส่วนใหญ่ ##ทฤษฎี
FFT คำนวณผ่านคลิปเสียงรบกวน
สถิติคำนวณผ่าน FFT ของเสียง (เป็นความถี่)
เกณฑ์จะคำนวณตามสถิติของเสียงรบกวน (และความไวที่ต้องการของอัลกอริทึม)
หน้ากากถูกกำหนดโดยการเปรียบเทียบสัญญาณ FFT กับเกณฑ์
หน้ากากจะราบรื่นด้วยตัวกรองผ่านความถี่และเวลา
หน้ากากถูกนำไปใช้กับ FFT ของสัญญาณและกลับด้าน
นำเข้า ipython จาก scipy.io นำเข้า wavfileimport scipy.signalimport numpy เป็น npimport matplotlib.pyplot เป็น pltimport librosaimport wave%matplotlib inline
ที่นี่เรากำลังนำเข้าไลบรารีเช่น ipython lib ที่ใช้สำหรับการสร้างสภาพแวดล้อมที่ครอบคลุมสำหรับการคำนวณแบบอินเทอร์แอคทีฟและเชิงสำรวจ
จากไลบรารี scipy.io ใช้สำหรับจัดการข้อมูลและการสร้างภาพข้อมูลของข้อมูลโดยใช้คำสั่ง Python ที่หลากหลาย
Numpy มีโครงสร้างข้อมูลอาร์เรย์หลายมิติและเมทริกซ์ มันสามารถใช้เพื่อดำเนินการทางคณิตศาสตร์จำนวนมากในอาร์เรย์เช่นข้อกำหนดด้านตรีโกณมิติสถิติและพีชคณิตดังนั้นจึงเป็นห้องสมุดที่มีประโยชน์มาก
Matplotlib.pyplot Library ช่วยให้เข้าใจข้อมูลจำนวนมากผ่านการแสดงภาพที่แตกต่างกัน
Librosa ใช้เมื่อเราทำงานกับข้อมูลเสียงเช่นในการสร้างเพลง (โดยใช้ LSTM's) การรู้จำเสียงพูดอัตโนมัติ มันให้หน่วยการสร้างที่จำเป็นในการสร้างระบบดึงข้อมูลเพลง
%matplotlib inline เพื่อเปิดใช้งานการพล็อตแบบอินไลน์โดยที่พล็อต/กราฟจะแสดงอยู่ใต้เซลล์ที่เขียนคำสั่งการพล็อตของคุณ มันให้การโต้ตอบกับแบ็กเอนด์ในส่วนหน้าเช่นสมุดบันทึก Jupyter
wav_loc = r '/home/noise_reduction/downloads/wave/file.wav'rate, data = wavfile.read (wav_loc, mmap = false)
ที่นี่เราใช้ตำแหน่งเส้นทางไฟล์ WAW จากนั้นอ่านไฟล์ WAW ที่มีโมดูล WaveFile ซึ่งมาจากไลบรารี Scipy.io ด้วยพารามิเตอร์ (ชื่อไฟล์ - สตริงหรือเปิดไฟล์ที่จับซึ่งเป็นไฟล์อินพุต WAV) จากนั้น (MMAP: BOOL เป็นทางเลือกที่จะอ่านข้อมูลเป็นหน่วยความจำแมป (ค่าเริ่มต้น: เท็จ)
def fftnoise (f): f = np.array (f, dtype = "complex") np = (len (f) - 1) // 2phases = np.random.rand (np) * 2 * np.piphases = np .COS (เฟส) + 1J * NP.SIN (เฟส) F [1: NP + 1] * = phasesf [-1: -1 -np: -1] = np.conj (f [1: np + 1] ) ส่งคืน np.fft.ifft (f) .Real
ที่นี่เรากำหนดฟังก์ชั่นเสียงรบกวน FFT โดยย่อการแปลงฟูริเยร์ที่รวดเร็ว (FFT) เป็นอัลกอริทึมที่คำนวณการแปลงฟูริเยร์แบบแยก (DFT) ของลำดับหรือผกผัน (IDFT) การวิเคราะห์ฟูริเยร์แปลงสัญญาณจากโดเมนดั้งเดิม (มักจะเวลาหรือพื้นที่) เป็นตัวแทนในโดเมนความถี่และในทางกลับกัน DFT ได้มาจากการย่อยสลายลำดับของค่าเป็นส่วนประกอบของความถี่ที่แตกต่างกัน
การใช้การแปลงฟูริเยร์อย่างรวดเร็วและกำหนดฟังก์ชั่นของประเภทข้อมูลที่ซับซ้อนและในที่สุดก็คำนวณส่วนจริงของฟังก์ชั่น ในสิ่งนี้ความถี่ที่อยู่ระหว่างความถี่ต่ำสุดและความถี่สูงสุดถูกตั้งค่าเป็น 1 และส่วนที่ไม่ต้องการที่เหลือจะถูกละเลย
ให้ตำแหน่งไฟล์
การอ่านไฟล์ WAV
-32767 ถึง +32767 เป็นเสียงที่เหมาะสม (เป็นสมมาตร) และ 32768 หมายความว่าเสียงที่ถูกตัด ณ จุดนั้น
WAV-FILE เป็นจำนวนเต็ม 16 บิตช่วงคือ [-32768, 32767] ดังนั้นการหารด้วย 32768 (2^15) จะให้ช่วง twos-complement ที่เหมาะสมของ [-1, 1]
def band_limited_noise (min_freq, max_freq, samples = 1024, samplerate = 1): freqs = np.abs (np.fft.fftfreq (ตัวอย่าง, 1 / samplerate)) f = np.zeros (ตัวอย่าง) f [np.logical_and > = min_freq, freqs <= max_freq)] = 1 กลับมา fftnoise (f)
ฟังก์ชั่นหรืออนุกรมเวลาที่มีการแปลงฟูริเยร์ถูก จำกัด ให้อยู่ในช่วงความถี่หรือความยาวคลื่น
การกำหนด FREQ ด้วยมาตรฐาน FREQ ที่มีขีด จำกัด ขั้นต่ำและสูงสุด
noise_len = 2 # secondsnoise = band_limited_noise (min_freq = 4000, max_freq = 12000, samples = len (data), samplerate = อัตรา)*10noise_clip = เสียง
บล็อกเสียงสีขาวที่ จำกัด วงดนตรีระบุสเปกตรัมสองด้านที่หน่วยเป็น Hz
ในกรณีที่สูงสุด 12000 และขั้นต่ำของ 4000 จะถูกเปรียบเทียบ WRT เสียงและข้อมูลที่ให้ไว้
ที่นี่เรากำลังตัดสัญญาณเสียงรบกวนโดยมีผลิตภัณฑ์ของอัตราและสัญญาณของสัญญาณรบกวน
ดังนั้นการเพิ่มเสียงและข้อมูลที่กำหนด
ผลการเพิ่มเสียงรบกวนจะขยายขนาดของชุดข้อมูลการฝึกอบรม
เสียงรบกวนแบบสุ่มจะถูกเพิ่มเข้าไปในตัวแปรอินพุตทำให้แตกต่างกันทุกครั้งที่สัมผัสกับโมเดล
การเพิ่มเสียงรบกวนในตัวอย่างอินพุตเป็นรูปแบบที่ง่ายของการเพิ่มข้อมูล
การเพิ่มเสียงรบกวนหมายความว่าเครือข่ายไม่สามารถจดจำตัวอย่างการฝึกอบรมได้น้อยลงเพราะพวกเขากำลังเปลี่ยนแปลงตลอดเวลา
ส่งผลให้น้ำหนักเครือข่ายเล็กลงและเครือข่ายที่แข็งแกร่งยิ่งขึ้นซึ่งมีข้อผิดพลาดทั่วไปลดลง
นำเข้า TimeFrom DateTime Import TimeDelta เป็น TD
เวลานำเข้า โมดูลนี้มีฟังก์ชั่นที่เกี่ยวข้องกับเวลาต่าง ๆ สำหรับฟังก์ชั่นที่เกี่ยวข้องดูที่โมดูล DateTime และปฏิทิน คลาส DateTime.timedelta
ระยะเวลาที่แสดงความแตกต่างระหว่างสองวันที่เวลาหรืออินสแตนซ์ dateTime ไปยังความละเอียด microsecond
def _stft (y, n_fft, hop_length, win_length): return librosa.stft (y = y, n_fft = n_fft, hop_length = hop_length, win_length = win_length)
การแปลงฟูริเยร์เวลาสั้น ๆ สามารถใช้ในการหาปริมาณการเปลี่ยนแปลงของความถี่และเนื้อหาเฟสของสัญญาณที่ไม่ได้อยู่ในช่วงเวลา
ความยาวกระโดดควรอ้างถึงจำนวนตัวอย่างในระหว่างเฟรมต่อเนื่อง สำหรับการวิเคราะห์สัญญาณความยาวกระโดดควรน้อยกว่าขนาดเฟรมเพื่อให้เฟรมซ้อนทับกัน
พารามิเตอร์ ynp.ndarray [shape = (n,)], สัญญาณอินพุตที่มีค่าจริง
n_fftint> 0 [สเกลาร์]
ความยาวของสัญญาณที่มีหน้าต่างหลังจากช่องว่างภายในด้วยศูนย์ จำนวนแถวใน เมทริกซ์ STFT คือ (1 + N_FFT/2) ค่าเริ่มต้น, N_FFT = 2048 ตัวอย่างสอดคล้องกับระยะเวลาทางกายภาพ 93 มิลลิวินาทีในอัตราตัวอย่าง 22050 Hz, เช่นอัตราตัวอย่างเริ่มต้นใน Librosa ค่านี้ได้รับการปรับให้ดีสำหรับสัญญาณเพลง อย่างไรก็ตามในการประมวลผลคำพูดค่าที่แนะนำคือ 512 ซึ่งสอดคล้องกับ 23 มิลลิวินาทีในอัตราตัวอย่าง 22050 Hz ไม่ว่าในกรณีใดเราขอแนะนำให้ตั้งค่า N_FFT ให้เป็นพลังของสองเพื่อเพิ่มประสิทธิภาพความเร็วของอัลกอริทึมการแปลงฟูริเยร์ที่รวดเร็ว (FFT)
hop_lengthint> 0 [สเกลาร์]
จำนวนตัวอย่างเสียงระหว่างคอลัมน์ STFT ที่อยู่ติดกัน
ค่าที่น้อยลงจะเพิ่มจำนวนคอลัมน์ใน D โดยไม่ส่งผลกระทบต่อความละเอียดความถี่ของ STFT
หากไม่ได้ระบุค่าเริ่มต้นเป็น win_length // 4 (ดูด้านล่าง)
win_lengthint <= n_fft [สเกลาร์]
แต่ละเฟรมของเสียงจะถูกหน้าต่างตามหน้าต่างที่มีความยาว win_length จากนั้นเบาะด้วยศูนย์เพื่อให้ตรงกับ n_fft
ค่าที่เล็กลงปรับปรุงความละเอียดชั่วคราวของ STFT (เช่นความสามารถในการแยกแยะแรงกระตุ้นที่มีระยะห่างอย่างใกล้ชิด) โดยค่าใช้จ่ายของความละเอียดความถี่ (เช่นความสามารถในการแยกแยะโทนสีบริสุทธิ์ที่มีระยะห่างอย่างใกล้ชิด) เอฟเฟกต์นี้เรียกว่าการแลกเปลี่ยนความถี่ในการแปลความถี่และจำเป็นต้องปรับตามคุณสมบัติของสัญญาณอินพุต y
หากไม่ได้ระบุค่าเริ่มต้นเป็น win_length = n_fft
กลับ Librosa.istft (y, hop_length, win_length)
การแปลงฟูริเยร์เวลาสั้น ๆ แบบผกผัน (istft) .Converts spectrogram ที่มีค่าคอมเพล็กซ์ที่ซับซ้อน stft_matrix เป็นอนุกรมเวลา y โดยการลดข้อผิดพลาดค่าเฉลี่ยกำลังสองระหว่าง stft_matrix และ stft ของ y ตามที่อธิบายไว้ใน
โดยทั่วไปฟังก์ชั่นหน้าต่างความยาวฮอปและพารามิเตอร์อื่น ๆ ควรจะเหมือนกับใน STFT ซึ่งส่วนใหญ่นำไปสู่การสร้างสัญญาณใหม่ที่สมบูรณ์แบบจาก STFT_MATRIX ที่ไม่ได้แก้ไข
def _amp_to_db (x): ส่งคืน librosa.core.amplitude_to_db (x, ref = 1.0, amin = 1e-20, top_db = 80.0)
1. คอนเวอร์เวอร์สเปคตรัมแอมพลิจูดไปยังสเปกโตรแกรมที่ปรับขนาด DB ซึ่งเทียบเท่ากับ POWER_TO_DB (S ** 2) แต่มีไว้เพื่อความสะดวก
ส่งคืน librosa.core.db_to_amplitude (x, ref = 1.0)
แปลงสเปกโตรแกรมที่ปรับขนาด DB เป็นสเปกตรัมแอมพลิจูด
สิ่งนี้จะกลับมามีประสิทธิภาพได้อย่างมีประสิทธิภาพ amplitude_to_db:
db_to_amplitude (s_db) ~ = 10.0 (0.5* (s_db + log10 (อ้างอิง)/10)) **
def plot_spectrogram (สัญญาณ, ชื่อ): รูป, ax = plt.subplots (figsize = (20, 4)) cax = ax.matshow (สัญญาณ, ต้นกำเนิด = "ล่าง", แง่มุม = "auto", cmap = plt.cm แผ่นดินไหว, vmin = -1 * np.max (np.abs (สัญญาณ)), vmax = np.max (np.abs (สัญญาณ)),
-พล็อต spectogram ด้วยสัญญาณเป็นอินพุต
คลาสแกนประกอบด้วยองค์ประกอบรูปส่วนใหญ่: แกน, เห็บ, line2d, ข้อความ, รูปหลายเหลี่ยม ฯลฯ และตั้งค่าระบบพิกัด
มันมีแผนที่สีหลายสีใน Matplotlib ที่สามารถเข้าถึงได้ผ่านฟังก์ชั่นนี้ .o ค้นหาการแสดงที่ดีใน 3D Colorspace สำหรับชุดข้อมูลของคุณ
Fig.Colorbar (CAX) AX.SET_TITLE (ชื่อ)
วิธีที่ดีที่สุดในการดูว่าเกิดอะไรขึ้นคือการเพิ่ม Colorbar (Plt.Colorbar () หลังจากสร้างพล็อตกระจาย) คุณจะทราบว่าค่าของคุณระหว่าง 0 ถึง 10,000 นั้นต่ำกว่าส่วนต่ำสุดของบาร์ซึ่งสิ่งต่าง ๆ เป็นสีเขียวที่เบามาก
โดยทั่วไปค่าด้านล่าง VMIN จะมีสีด้วยสีต่ำสุดและค่าเหนือ VMAX จะได้รับสีสูงสุด
หากคุณตั้งค่า VMAX ที่เล็กกว่า VMIN ภายในพวกเขาจะถูกเปลี่ยน แม้ว่าขึ้นอยู่กับรุ่นที่แน่นอนของ Matplotlib และฟังก์ชั่นที่แม่นยำที่เรียกว่า Matplotlib อาจให้คำเตือนข้อผิดพลาด ดังนั้นควรตั้งค่า vmin ต่ำกว่า VMAX เสมอ
def plot_statistics_and_filter (mean_freq_noise, std_freq_noise, noise_thresh, smoothing_filter): รูป, ax = plt.subplots (ncols = 2, figsize = (20, 4)) plt_std, = ax [0] ของเสียง ")
plt_std, = ax [0] .plot (noise_thresh, label = "Noise Threshold (โดยความถี่)") AX [0] .set_title ("Threshold สำหรับ Mask")
AX [0] .legend () CAX = AX [1] .MatShow (Smoothing_Filter, Origin = "Lower") Fig.Colorbar (CAX) AX [1] .set_title ("ตัวกรองสำหรับหน้ากากปรับให้เรียบ")))))))แปลงสถิติพื้นฐานของการลดเสียงรบกวน
อัตราส่วนสัญญาณต่อเสียงรบกวน (SNR หรือ S/N) เป็นมาตรการที่ใช้ในวิทยาศาสตร์และวิศวกรรมที่เปรียบเทียบระดับของสัญญาณที่ต้องการกับระดับเสียงรบกวนพื้นหลัง
SNR ถูกกำหนดให้เป็นอัตราส่วนของพลังสัญญาณต่อกำลังเสียงรบกวนซึ่งมักแสดงในเดซิเบล
อัตราส่วนที่สูงกว่า 1: 1 (มากกว่า 0 dB) หมายถึงสัญญาณมากกว่าเสียงรบกวน
การตั้งค่าความถี่ threshhold สำหรับการปิดบังเสียง
เกณฑ์การปิดบังหมายถึงกระบวนการที่มีเสียงหนึ่งเสียงไม่ได้ยินเนื่องจากการปรากฏตัวของเสียงอื่น
ดังนั้นเกณฑ์การปิดบังคือระดับความดันเสียงของเสียงที่จำเป็นในการทำให้เสียงได้ยินเมื่อมีเสียงอื่นที่เรียกว่า "masker"
เพิ่มเกณฑ์
สัญญาณเสียงเบลอด้วยตัวกรองผ่านต่ำต่างๆ
ใช้ตัวกรองที่ทำเองกับรูปภาพ (2D convolution)
def ลบออก ( # ถึงค่าเฉลี่ยสัญญาณ (แรงดันไฟฟ้า) ของส่วนความลาดเชิงบวก (เพิ่มขึ้น) ของคลื่นสามเหลี่ยมเพื่อพยายามลบเสียงรบกวนให้ได้มากที่สุดเท่าที่จะเป็นไปได้ การดำเนินการ noise_clip, n_grad_freq = 2, # ช่องความถี่กี่ช่องที่จะราบรื่นด้วย mask.n_grad_time = 4, # กี่ช่องเวลาในการราบ 2048, # แต่ละเฟรมของเสียงถูกหน้าต่างโดย `window ()` N_STD_THRESH = 1.5, # ค่าเบี่ยงเบนมาตรฐานจำนวนเท่าใดที่ดังกว่าค่าเฉลี่ย dB ของเสียง (ในแต่ละระดับความถี่) ที่จะพิจารณา signalProp_decrease = 1.0, # ถึงระดับเสียงที่คุณควรลดเสียงรบกวน (1 = ทั้งหมด, 0 = ไม่มี) verbose = false , # Flag ช่วยให้คุณเขียนนิพจน์ทั่วไปที่ดู presentablevisual = false, # ไม่ว่าจะพล็อตขั้นตอนของอัลกอริทึม):
DEF ลบออก ( โดยเฉลี่ยสัญญาณ (แรงดันไฟฟ้า) ของส่วนที่ลาดชัน (เพิ่มขึ้น) ของคลื่นสามเหลี่ยมเพื่อพยายามกำจัดเสียงรบกวนให้ได้มากที่สุด
AUDIO_CLIP
คลิปเหล่านี้เป็นพารามิเตอร์ที่เราจะดำเนินการตามลำดับ
Noise_clip, N_GRAD_FREQ = 2 ช่องความถี่กี่ช่องที่จะราบรื่นด้วยหน้ากาก
N_GRAD_TIME = 4 มีช่องเวลากี่ช่องที่จะราบรื่นด้วยหน้ากาก
n_fft = 2048
หมายเลขเสียงของเฟรมระหว่างคอลัมน์ STFT
win_length = 2048 แต่ละเฟรมของเสียงจะถูกหน้าต่างทาง window() หน้าต่างจะมีความยาว win_length จากนั้นเบาะด้วยศูนย์เพื่อให้ตรงกับ n_fft ..
hop_length = 512, หมายเลขเสียงของเฟรมระหว่างคอลัมน์ STFT
N_STD_THRESH = 1.5 ค่าเบี่ยงเบนมาตรฐานดังกว่าค่าเฉลี่ยของเสียงรบกวน (ในแต่ละระดับความถี่) ที่จะพิจารณาสัญญาณ
prop_decrease = 1.0 คุณควรลดเสียงรบกวน (1 = ทั้งหมด, 0 = ไม่มี)
verbose = เท็จ
Flag ช่วยให้คุณเขียนนิพจน์ทั่วไปที่ดู Visual = False, #ไม่ว่าจะพล็อตขั้นตอนของอัลกอริทึม):
noise_stft = _stft (noise_clip, n_fft, hop_length, win_length) noise_stft_db = _amp_to_db (np.abs (noise_stft))
STFT มากกว่าเสียงรบกวน
แปลงเป็น db
mean_freq_noise = np.mean (noise_stft_db, axis = 1) std_freq_noise = np.std (noise_stft_db, axis = 1) noise_thesh = mean_freq_noise + std_freq_noise * n_std_thresh
คำนวณสถิติมากกว่าเสียงรบกวน
ที่นี่เราสำหรับเสียง Thresh เราเพิ่มค่าเฉลี่ยและเสียงรบกวนมาตรฐานและเสียง N_STD
SIG_STFT = _STFT (AUDIO_CLIP, N_FFT, HOP_LENGTH, Win_Length) SIG_STFT_DB = _AMP_TO_DB (NP.ABS (SIG_STFT))
STFT Over Signal
mask_gain_db = np.min (_amp_to_db (np.abs (sig_stft))))
คำนวณค่าเป็นหน้ากาก DB ถึง
Smoothing_filter = np.outer (np.concatenate (
[np.linspace (0, 1, n_grad_freq + 1, endpoint = false), np.linspace (1, 0, n_grad_freq + 2),
-
) [1: -1], np.concatenate (
[np.linspace (0, 1, n_grad_time + 1, endpoint = false), np.linspace (1, 0, n_grad_time + 2),
-
) [1: -1]
) Smoothing_Filter = Smoothing_Filter / NP.Sum (Smoothing_Filter)สร้างตัวกรองที่เรียบสำหรับหน้ากากในเวลาและความถี่
db_thresh = np.repeat (np.reshape (noise_thresh, [1, len (mean_freq_noise)]), np.shape (sig_stft_db) [1], axis = 0,
) .Tคำนวณเกณฑ์สำหรับถังความถี่/เวลาแต่ละถัง
sig_mask = sig_stft_db <db_thresh
หน้ากากสำหรับสัญญาณ
sig_mask = scipy.signal.fftconvolve (sig_mask, smoothing_filter, mode = "same") sig_mask = sig_mask * prop_decrease
หน้ากาก convolution ด้วยตัวกรองที่ราบรื่น
# หน้ากากสัญญาณ _stft_db_masked = (sig_stft_db * (1 - sig_mask)+ np.ones (np.shape (mask_gain_db)) * mask_gain_db * sig_mask) _to_amp (sig_stft_db_masked) * np.sign (sig_stft)) + (1j * sig_imag_masked)
ปกปิดสัญญาณ
# กู้คืน signalRecovered_signal = _istft (sig_stft_amp, hop_length, win_length) กู้คืน _spec = _amp_to_db (np.abs (_stft (กู้คืน _signal, n_fft, hop_length, win_length))
-กู้คืนสัญญาณ
ใช้หน้ากากหากสัญญาณอยู่เหนือเกณฑ์
โน้มน้าวหน้ากากด้วยตัวกรองที่ราบรื่น
การใช้อัลกอริทึมการลดเสียงรบกวนสำหรับไฟล์ WAV ที่ดาวน์โหลดมาแล้ว
การใช้ FFT ผ่านการบันทึกสดของสัญญาณเสียง
การใช้ AI อย่างลึกซึ้งยิ่งขึ้นสำหรับการยกเลิกเสียงรบกวน
การใช้อัลกอริทึมการลดเสียงรบกวนสำหรับไฟล์เสียงรูปแบบต่างๆ
สัญญาณเสียงสดพร้อมไมโครโฟนและ ESP32 และจะได้รับไฟล์ WAV สำหรับการคำนวณเพิ่มเติมและการประมวลผลสัญญาณ
Dhriti Mabian
Priyal Awankar
*SRA VJTI_EKLAVYA 2021
Shreyas Atre
Shah รุนแรง
ความกล้าหาญ
วิธีการยกเลิกเสียงรบกวน
เอาหม้อต้มจาก Martin Heinz
ทิม Sainburg
ใบอนุญาต


