ainovelprompter
1.0.0
AI Novel Prompter สามารถสร้างพรอมต์การเขียนสำหรับนวนิยายตามลักษณะที่ผู้ใช้ระบุ
AI Novel Prompter เป็นแอปพลิเคชั่นเดสก์ท็อปที่ออกแบบมาเพื่อช่วยให้นักเขียนสร้างพรอมต์ที่สอดคล้องและมีโครงสร้างที่ดีสำหรับผู้ช่วยการเขียน AI เช่น Chatgpt และ Claude เครื่องมือนี้ช่วยจัดการองค์ประกอบเรื่องราวรายละเอียดตัวละครและสร้างพรอมต์ที่จัดรูปแบบอย่างเหมาะสมสำหรับนวนิยายของคุณต่อไป
ปฏิบัติการอยู่ในการสร้าง/bin ที่สามารถเรียกใช้งานได้
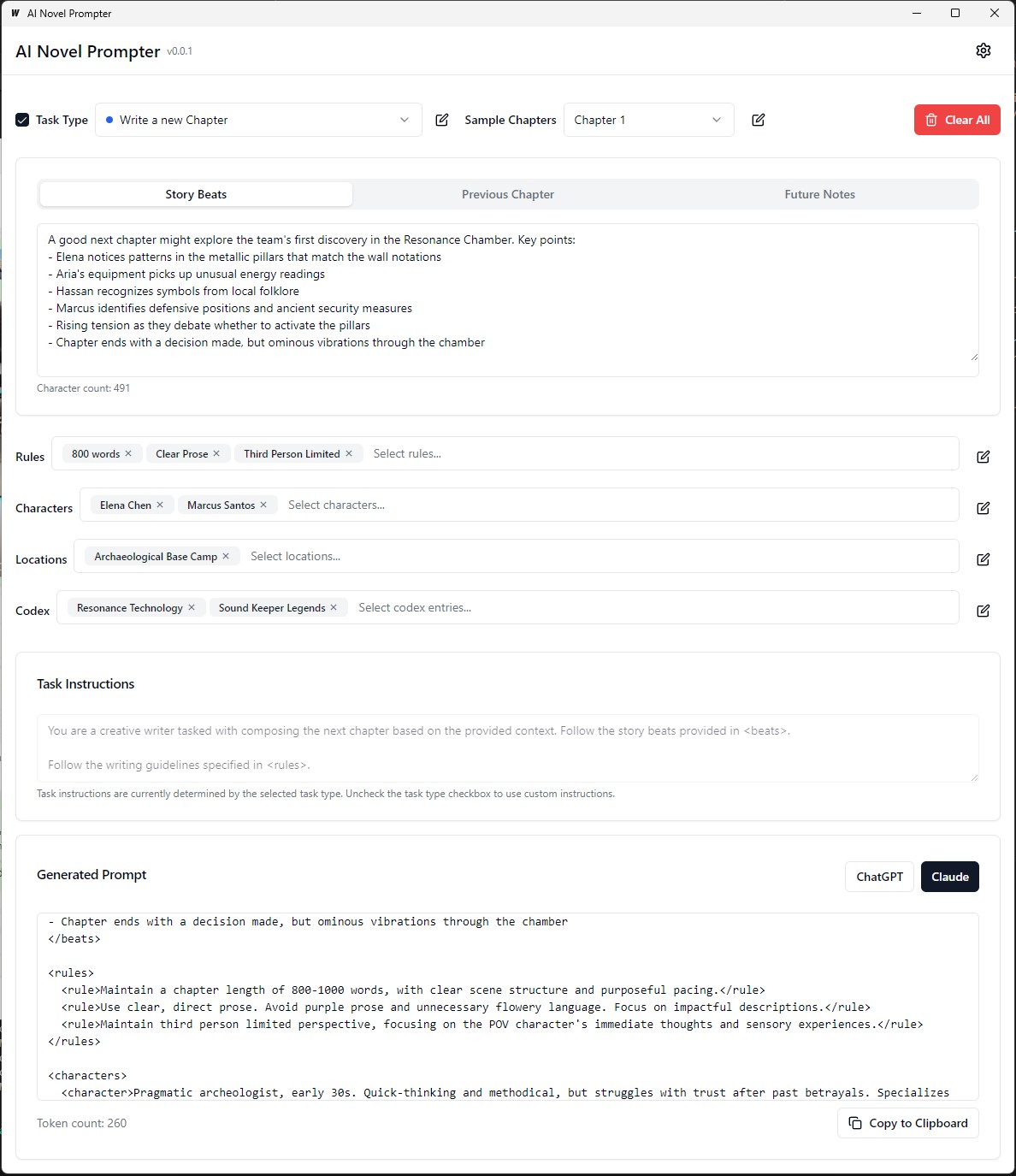
แต่ละหมวดหมู่สามารถแก้ไขบันทึกและนำกลับมาใช้ใหม่ได้ในพรอมต์ที่แตกต่างกัน:
ส่วนหน้า :
แบ็กเอนด์ :
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev ในการสร้างแพ็คเกจโหมดการผลิตที่แจกจ่าย wails build
wails buildปฏิบัติการอยู่ในการสร้าง/bin ที่สามารถเรียกใช้งานได้
หรือสร้างด้วย:
wails build -nsisสามารถทำได้สำหรับ Mac และดูส่วนล่าสุดของคู่มือนี้
แอปพลิเคชันที่สร้างขึ้นจะมีอยู่ในไดเรกทอรี build
การตั้งค่าเริ่มต้น :
การสร้างพรอมต์ :
การสร้างผลลัพธ์ :
ก่อนเรียกใช้แอปพลิเคชันตรวจสอบให้แน่ใจว่าคุณติดตั้งต่อไปนี้:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
นำทางไปยังไดเรกทอรี server :
cd server
ติดตั้งการพึ่งพา GO:
go mod download
อัปเดตไฟล์ config.yaml ด้วยการกำหนดค่าฐานข้อมูลของคุณ
เรียกใช้การย้ายฐานข้อมูล:
go run cmd/main.go migrate
เริ่มต้นเซิร์ฟเวอร์แบ็กเอนด์:
go run cmd/main.go
นำทางไปยังไดเรกทอรี client :
cd ../client
ติดตั้งการพึ่งพาส่วนหน้า:
npm install
เริ่มเซิร์ฟเวอร์การพัฒนาส่วนหน้า:
npm start
http://localhost:3000 เพื่อเข้าถึงแอปพลิเคชัน git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
อัปเดตไฟล์ docker-compose.yml ด้วยการกำหนดค่าฐานข้อมูลของคุณ
เริ่มแอปพลิเคชันโดยใช้ Docker Compose:
docker-compose up -d
http://localhost:3000 เพื่อเข้าถึงแอปพลิเคชัน server/config.yamlclient/src/config.ts ในการสร้างส่วนหน้าสำหรับการผลิตให้เรียกใช้คำสั่งต่อไปนี้ในไดเรกทอรี client :
npm run build
ไฟล์พร้อมการผลิตจะถูกสร้างขึ้นในไดเรกทอรี client/build
คู่มือขนาดเล็กนี้ให้คำแนะนำเกี่ยวกับวิธีการติดตั้ง PostgreSQL บนระบบย่อย Windows สำหรับ Linux (WSL) พร้อมกับขั้นตอนในการจัดการสิทธิ์ของผู้ใช้และแก้ไขปัญหาทั่วไป
เปิด WSL Terminal : เปิดการกระจาย WSL ของคุณ (แนะนำ Ubuntu)
อัปเดตแพ็คเกจ :
sudo apt updateติดตั้ง PostgreSQL :
sudo apt install postgresql postgresql-contribตรวจสอบการติดตั้ง :
psql --versionตั้งรหัสผ่านผู้ใช้ PostgreSQL :
sudo passwd postgresสร้างฐานข้อมูล :
createdb mydbฐานข้อมูลการเข้าถึง :
psql mydbนำเข้าตารางจากไฟล์ SQL :
psql -U postgres -q mydb < /path/to/file.sqlรายการฐานข้อมูลและตาราง :
l # List databases
dt # List tables in the current databaseสวิตช์ฐานข้อมูล :
c dbnameสร้างผู้ใช้ใหม่ :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;สิทธิพิเศษ :
ALTER USER your_db_user CREATEDB;บทบาทไม่มีข้อผิดพลาด : เปลี่ยนเป็นผู้ใช้ 'postgres':
sudo -i -u postgres
createdb your_db_nameการอนุญาตถูกปฏิเสธที่จะสร้างส่วนขยาย : เข้าสู่ระบบเป็น 'postgres' และดำเนินการ:
CREATE EXTENSION IF NOT EXISTS pg_trgm; ข้อผิดพลาดของผู้ใช้ที่ไม่รู้จัก : ตรวจสอบให้แน่ใจว่าคุณใช้ผู้ใช้ระบบที่ได้รับการยอมรับหรืออ้างถึงผู้ใช้ PostgreSQL ภายในสภาพแวดล้อม SQL อย่างถูกต้องไม่ใช่ผ่าน sudo
เพื่อสร้างข้อมูลการฝึกอบรมที่กำหนดเองสำหรับการปรับรูปแบบภาษาเพื่อเลียนแบบสไตล์การเขียนของ George MacDonald กระบวนการเริ่มต้นด้วยการได้รับข้อความทั้งหมดของนวนิยายเล่มหนึ่งของเขา "The Princess and the Goblin" จาก Project Gutenberg จากนั้นข้อความจะถูกแบ่งออกเป็นเรื่องราวของแต่ละเรื่องหรือช่วงเวลาสำคัญโดยใช้พรอมต์ที่สั่งให้ AI สร้างวัตถุ JSON สำหรับแต่ละจังหวะการจับผู้เขียนเสียงอารมณ์ประเภทการเขียนและข้อความที่ตัดตอนมาจริง
ถัดไป GPT-4 จะใช้ในการเขียนเรื่องราวแต่ละเรื่องเหล่านี้ในคำพูดของตัวเองสร้างชุดข้อมูล JSON แบบขนานกับตัวระบุที่ไม่ซ้ำกันซึ่งเชื่อมโยงแต่ละจังหวะที่เขียนใหม่เข้ากับคู่เดิม เพื่อให้ข้อมูลง่ายขึ้นและทำให้มีประโยชน์มากขึ้นสำหรับการฝึกอบรมโทนอารมณ์ที่หลากหลายจะถูกแมปกับชุดเสียงแกนขนาดเล็กโดยใช้ฟังก์ชั่น Python ไฟล์ JSON สองไฟล์ (Beats ดั้งเดิมและการเขียนใหม่) จะถูกใช้เพื่อสร้างพรอมต์การฝึกอบรมโดยที่โมเดลจะถูกขอให้ใช้ข้อความ GPT-4 ที่สร้างขึ้นใหม่ในรูปแบบของผู้เขียนต้นฉบับ ในที่สุดพรอมต์เหล่านี้และเอาต์พุตเป้าหมายของพวกเขาจะถูกจัดรูปแบบลงในไฟล์ JSONL และ JSON พร้อมที่จะใช้สำหรับการปรับรูปแบบภาษาเพื่อจับสไตล์การเขียนที่โดดเด่นของ MacDonald
ในตัวอย่างก่อนหน้านี้กระบวนการสร้างข้อความถอดความโดยใช้แบบจำลองภาษาที่เกี่ยวข้องกับงานด้วยตนเองบางอย่าง ผู้ใช้ต้องจัดทำข้อความอินพุตเรียกใช้สคริปต์จากนั้นตรวจสอบผลลัพธ์ที่สร้างขึ้นเพื่อให้แน่ใจว่ามีคุณภาพ หากผลลัพธ์ไม่เป็นไปตามเกณฑ์ที่ต้องการผู้ใช้จะต้องลองกระบวนการสร้างด้วยพารามิเตอร์ที่แตกต่างกันด้วยตนเองหรือทำการปรับเปลี่ยนข้อความอินพุต
อย่างไรก็ตามด้วยฟังก์ชั่น process_text_file เวอร์ชันที่อัปเดตกระบวนการทั้งหมดได้รับการอัตโนมัติอย่างสมบูรณ์ ฟังก์ชั่นดูแลการอ่านไฟล์ข้อความอินพุตแยกออกเป็นย่อหน้าและส่งแต่ละย่อหน้าไปยังแบบจำลองภาษาโดยอัตโนมัติเพื่อการถอดความ มันรวมการตรวจสอบและกลไกการลองใหม่เพื่อจัดการกรณีที่เอาต์พุตที่สร้างขึ้นไม่เป็นไปตามเกณฑ์ที่ระบุเช่นที่มีวลีที่ไม่ต้องการสั้นเกินไปหรือยาวเกินไปหรือประกอบด้วยหลายย่อหน้า
กระบวนการอัตโนมัติมีคุณสมบัติสำคัญหลายประการ:
การกลับมาใช้ใหม่จากย่อหน้าที่ประมวลผลล่าสุด: หากสคริปต์ถูกขัดจังหวะหรือจำเป็นต้องรันหลายครั้งจะตรวจสอบไฟล์เอาต์พุตโดยอัตโนมัติและดำเนินการประมวลผลต่อจากวรรคถอดความที่ประสบความสำเร็จครั้งล่าสุด สิ่งนี้ทำให้มั่นใจได้ว่าความคืบหน้าจะไม่หายไปและสคริปต์สามารถรับได้
กลไกการลองใหม่ด้วยเมล็ดพันธุ์สุ่มและอุณหภูมิ: หากการถอดความที่สร้างขึ้นไม่สามารถปฏิบัติตามเกณฑ์ที่ระบุสคริปต์จะให้กระบวนการสร้างเป็นจำนวนครั้งที่ระบุโดยอัตโนมัติ ด้วยการลองใหม่แต่ละครั้งมันจะเปลี่ยนค่าเมล็ดและอุณหภูมิแบบสุ่มเพื่อแนะนำการเปลี่ยนแปลงในการตอบสนองที่สร้างขึ้นซึ่งเพิ่มโอกาสในการได้รับผลผลิตที่น่าพอใจ
การบันทึกความคืบหน้า: สคริปต์บันทึกความคืบหน้าไปยังไฟล์เอาต์พุตทุกจำนวนย่อหน้าที่ระบุ (เช่นทุก ๆ 500 วรรค) การป้องกันการสูญเสียข้อมูลนี้ในกรณีที่มีการหยุดชะงักหรือข้อผิดพลาดใด ๆ ในระหว่างการประมวลผลไฟล์ข้อความขนาดใหญ่
การบันทึกรายละเอียดและสรุป: สคริปต์ให้ข้อมูลการบันทึกรายละเอียดรวมถึงวรรคอินพุตเอาต์พุตที่สร้างขึ้นความพยายามลองใหม่และเหตุผลสำหรับความล้มเหลว นอกจากนี้ยังสร้างบทสรุปในตอนท้ายแสดงจำนวนย่อหน้าทั้งหมด, ย่อหน้าที่ประสบความสำเร็จในการถอดความย่อหน้าที่ข้ามย่อหน้าและจำนวนการลองใหม่ทั้งหมด
เพื่อสร้างข้อมูลการฝึกอบรมที่กำหนดเอง ORPO สำหรับการปรับแต่งรูปแบบภาษาเพื่อเลียนแบบสไตล์การเขียนของ George MacDonald
ข้อมูลอินพุตควรอยู่ในรูปแบบ JSONL โดยแต่ละบรรทัดที่มีวัตถุ JSON ที่มีการตอบกลับที่ได้รับพร้อมท์และเลือก (จากการปรับแต่งก่อนหน้านี้) เพื่อใช้สคริปต์คุณต้องตั้งค่าไคลเอนต์ OpenAI ด้วยคีย์ API ของคุณและระบุเส้นทางไฟล์อินพุตและเอาต์พุต การรันสคริปต์จะประมวลผลไฟล์ JSONL และสร้างไฟล์ CSV ด้วยคอลัมน์สำหรับพรอมต์การตอบกลับที่เลือกและการตอบกลับที่ถูกสร้างขึ้น สคริปต์บันทึกความคืบหน้าทุก 100 บรรทัดและสามารถกลับมาทำงานต่อจากที่ที่มันทิ้งไว้หากถูกขัดจังหวะ เมื่อเสร็จสิ้นจะมีการสรุปของบรรทัดทั้งหมดที่ประมวลผลบรรทัดที่เป็นลายลักษณ์อักษรบรรทัดที่ข้ามและรายละเอียดลองอีกครั้ง
เรื่องคุณภาพชุดข้อมูล: 95% ของผลลัพธ์ขึ้นอยู่กับคุณภาพชุดข้อมูล ชุดข้อมูลที่สะอาดเป็นสิ่งจำเป็นเนื่องจากแม้แต่ข้อมูลที่ไม่ดีเล็กน้อยก็สามารถทำร้ายโมเดลได้
การทบทวนข้อมูลด้วยตนเอง: การทำความสะอาดและประเมินชุดข้อมูลสามารถปรับปรุงโมเดลได้อย่างมาก นี่เป็นขั้นตอนที่ใช้เวลานาน แต่จำเป็นเนื่องจากไม่มีการปรับพารามิเตอร์จำนวนมากสามารถแก้ไขชุดข้อมูลที่มีข้อบกพร่องได้
พารามิเตอร์การฝึกอบรมไม่ควรปรับปรุง แต่ป้องกันการย่อยสลายแบบจำลอง ในชุดข้อมูลที่แข็งแกร่งเป้าหมายควรหลีกเลี่ยงผลกระทบเชิงลบในขณะที่กำกับโมเดล ไม่มีอัตราการเรียนรู้ที่ดีที่สุด
ข้อ จำกัด มาตราส่วนของแบบจำลองและฮาร์ดแวร์: รุ่นที่ใหญ่กว่า (พารามิเตอร์ 33B) อาจช่วยให้การปรับแต่งได้ดีขึ้น แต่ต้องใช้อย่างน้อย 48GB VRAM ทำให้ไม่สามารถทำได้สำหรับการตั้งค่าบ้านส่วนใหญ่
การสะสมการไล่ระดับสีและขนาดแบทช์: การสะสมการไล่ระดับสีช่วยลดการยืดตัวมากเกินไปโดยการเพิ่มลักษณะทั่วไปในชุดข้อมูลที่แตกต่างกัน แต่อาจลดคุณภาพหลังจากสองสามชุด
ขนาดของชุดข้อมูลมีความสำคัญมากกว่าสำหรับการปรับแต่งโมเดลฐานมากกว่ารุ่นที่ปรับแต่งได้ดี การใช้โมเดลที่มีการปรับแต่งมากเกินไปด้วยข้อมูลที่มากเกินไปอาจทำให้การปรับแต่งก่อนหน้านี้ลดลง
ตารางอัตราการเรียนรู้ในอุดมคติเริ่มต้นด้วยขั้นตอนการอุ่นเครื่องถือคงที่สำหรับยุคแล้วค่อยๆลดลงโดยใช้ตารางโคไซน์
อันดับรุ่นและการวางนัยทั่วไป: จำนวนพารามิเตอร์ที่สามารถฝึกอบรมได้มีผลต่อรายละเอียดและการวางนัยทั่วไปของโมเดล โมเดลระดับต่ำกว่าทั่วไปดีกว่า แต่สูญเสียรายละเอียด
การบังคับใช้ของ LORA: การปรับแต่งพารามิเตอร์-ประสิทธิภาพ (PEFT) ใช้กับโมเดลภาษาขนาดใหญ่ (LLMS) และระบบเช่นการแพร่กระจายที่เสถียร (SD) แสดงให้เห็นถึงความเก่งกาจ
ชุมชน unsloth ได้ช่วยแก้ไขปัญหาต่าง ๆ เกี่ยวกับ Finetuning LLAMA3 นี่คือประเด็นสำคัญบางประการที่ควรทราบ:
โทเค็น Double BOS : โทเค็น Double BOS ในระหว่างการ finetuning สามารถทำลายสิ่งต่าง ๆ ได้ unsloth แก้ไขปัญหานี้โดยอัตโนมัติ
การแปลง GGUF : การแปลง GGUF เสีย ระวัง Double BOS และใช้ CPU แทน GPU สำหรับการแปลง Unsloth มีการแปลง GGUF อัตโนมัติในตัว
น้ำหนักฐานบั๊กกี้ : บางส่วนของฐานของ Llama 3 (ไม่ใช่คำสั่ง) น้ำหนักคือ "buggy" (ไม่ได้รับการฝึกฝน): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> สิ่งนี้สามารถทำให้ Nans และ Buggy ผลลัพธ์ unsloth จะแก้ไขสิ่งนี้โดยอัตโนมัติ
ระบบพรอมต์ : ตามชุมชนที่ไม่เคยมีมาก่อนการเพิ่มพรอมต์ระบบจะทำให้การปรับแต่งของเวอร์ชันคำสั่ง (และอาจเป็นรุ่นพื้นฐาน) ดีกว่ามาก
ปัญหาเชิงปริมาณ : ปัญหาเชิงปริมาณเป็นเรื่องปกติ ดูการเปรียบเทียบนี้ซึ่งแสดงให้เห็นว่าคุณสามารถได้รับประสิทธิภาพที่ดีกับ LLAMA3 แต่การใช้ปริมาณที่ไม่ถูกต้องอาจส่งผลกระทบต่อประสิทธิภาพการทำงาน สำหรับ finetuning ให้ใช้ Bitsandbytes NF4 เพื่อเพิ่มความแม่นยำ สำหรับ GGUF ให้ใช้เวอร์ชัน I ให้มากที่สุด
แบบจำลองบริบทยาว : แบบจำลองบริบทยาวได้รับการฝึกฝนมาไม่ดี พวกเขาเพียงแค่ขยายเชือก theta บางครั้งไม่มีการฝึกอบรมใด ๆ จากนั้นฝึกในชุดข้อมูลที่ต่อกันแปลก ๆ เพื่อให้เป็นชุดข้อมูลที่ยาว วิธีการนี้ทำงานได้ไม่ดี การปรับขนาดบริบทที่ราบรื่นและต่อเนื่องจะดีขึ้นมากหากปรับขนาดจากความยาวบริบท 8K ถึง 1M
ในการแก้ไขปัญหาเหล่านี้ให้ใช้ unsloth สำหรับ finetuning llama3
เมื่อปรับแต่งรูปแบบภาษาสำหรับการถอดความในสไตล์ของผู้เขียนสิ่งสำคัญคือการประเมินคุณภาพและประสิทธิผลของการถอดความที่สร้างขึ้น
ตัวชี้วัดการประเมินผลต่อไปนี้สามารถใช้เพื่อประเมินประสิทธิภาพของโมเดล:
bleu (การประเมินสองภาษา underdudy):
sacrebleu ใน Pythonfrom sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge (underdudy ที่มุ่งเน้นการเรียกคืนสำหรับการประเมินผล):
rouge ใน Pythonfrom rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)ความงุนงง:
perplexity = model.perplexity(generated_paraphrases)มาตรการเชิงโวหาร:
stylometry ใน Pythonfrom stylometry import extract_features; features = extract_features(generated_paraphrases)หากต้องการรวมตัวชี้วัดการประเมินเหล่านี้เข้ากับท่อ Axolotl ของคุณให้ทำตามขั้นตอนเหล่านี้:
เตรียมข้อมูลการฝึกอบรมของคุณโดยการสร้างชุดข้อมูลของย่อหน้าจากผลงานของผู้เขียนเป้าหมายและแยกออกเป็นชุดการฝึกอบรมและการตรวจสอบความถูกต้อง
ปรับรูปแบบภาษาของคุณโดยใช้ชุดการฝึกอบรมตามวิธีการที่กล่าวถึงก่อนหน้านี้
สร้างถอดความสำหรับย่อหน้าในชุดการตรวจสอบความถูกต้องโดยใช้แบบจำลองที่ปรับแต่ง
ใช้ตัวชี้วัดการประเมินผลโดยใช้ไลบรารีที่เกี่ยวข้อง ( sacrebleu , rouge , stylometry ) และคำนวณคะแนนสำหรับการถอดความแต่ละครั้ง
ดำเนินการประเมินผลของมนุษย์โดยการรวบรวมการจัดอันดับและข้อเสนอแนะจากผู้ประเมินของมนุษย์
วิเคราะห์ผลการประเมินเพื่อประเมินคุณภาพและรูปแบบของการถอดความที่สร้างขึ้นและทำการตัดสินใจอย่างชาญฉลาดเพื่อปรับปรุงกระบวนการปรับจูนของคุณ
นี่คือตัวอย่างของวิธีที่คุณสามารถรวมตัวชี้วัดเหล่านี้เข้ากับไปป์ไลน์ของคุณ:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )อย่าลืมติดตั้งไลบรารีที่จำเป็น (Sacrebleu, Rouge, Stylometry) และปรับรหัสให้เหมาะกับการใช้งานของคุณใน Axolotl หรือคล้ายกัน
ในการทดลองนี้ฉันสำรวจความสามารถและความแตกต่างระหว่างโมเดล AI ต่างๆในการสร้างข้อความ 1500 คำตามพรอมต์โดยละเอียด ฉันทดสอบโมเดลจาก https://chat.lmsys.org/, chatgpt4, Claude 3 Opus และรุ่นท้องถิ่นบางรุ่นใน LM Studio แต่ละรุ่นสร้างข้อความสามครั้งเพื่อสังเกตความแปรปรวนในผลลัพธ์ของพวกเขา ฉันยังสร้างพรอมต์แยกต่างหากสำหรับการประเมินการเขียนการทำซ้ำครั้งแรกจากแต่ละรุ่นและถาม Chatgpt 4 และ Claude Opus 3 เพื่อให้ข้อเสนอแนะ
ผ่านกระบวนการนี้ฉันสังเกตว่าบางรุ่นมีความแปรปรวนที่สูงขึ้นระหว่างการประหารชีวิตในขณะที่คนอื่นมักจะใช้ถ้อยคำที่คล้ายกัน นอกจากนี้ยังมีความแตกต่างอย่างมีนัยสำคัญในจำนวนคำที่สร้างขึ้นและปริมาณของบทสนทนาคำอธิบายและย่อหน้าที่ผลิตโดยแต่ละรุ่น ข้อเสนอแนะการประเมินผลเปิดเผยว่า Chatgpt แนะนำร้อยแก้วที่ "กลั่น" มากขึ้นในขณะที่ Claude แนะนำร้อยแก้วสีม่วงน้อยลง จากการค้นพบเหล่านี้ฉันได้รวบรวมรายการของประเด็นต่าง ๆ เพื่อรวมเข้ากับพรอมต์ถัดไปโดยมุ่งเน้นไปที่ความแม่นยำโครงสร้างประโยคที่หลากหลายคำกริยาที่แข็งแกร่งการบิดที่ไม่ซ้ำกันในลวดลายแฟนตาซีเสียงที่สอดคล้องกันเสียงบรรยายที่แตกต่างกัน อีกเทคนิคที่ต้องพิจารณาคือการขอข้อเสนอแนะจากนั้นเขียนข้อความขึ้นอยู่กับข้อเสนอแนะนั้นอีกครั้ง
ฉันเปิดให้ร่วมมือกับผู้อื่นเพื่อปรับการปรับแต่งให้ดีขึ้นสำหรับแต่ละรุ่นและสำรวจความสามารถของพวกเขาในงานเขียนเชิงสร้างสรรค์
แบบจำลองมีอคติการจัดรูปแบบโดยธรรมชาติ บางรุ่นชอบยัติภังค์สำหรับรายการและอื่น ๆ เครื่องหมายดอกจัน เมื่อใช้โมเดลเหล่านี้จะมีประโยชน์ในการสะท้อนการตั้งค่าของพวกเขาสำหรับผลลัพธ์ที่สอดคล้องกัน
การจัดรูปแบบแนวโน้ม:
Llama 3 ชอบรายการที่มีส่วนหัวและเครื่องหมายดอกจัน
ตัวอย่าง: หัวเรื่องชื่อเรื่องตัวหนา
รายการรายการที่มีเครื่องหมายดอกจันหลังจากสองสายใหม่
รายการคั่นด้วยหนึ่งบรรทัดใหม่
รายการถัดไป
รายการเพิ่มเติม
ฯลฯ ...
ตัวอย่างไม่กี่ตัวอย่าง:
ระบบการยึดมั่นที่รวดเร็ว:
หน้าต่างบริบท:
การเซ็นเซอร์:
ปัญญา:
ความสอดคล้อง:
รายการและการจัดรูปแบบ:
การตั้งค่าแชท:
การตั้งค่าท่อ:
Llama 3 มีความยืดหยุ่นและชาญฉลาด แต่มีข้อ จำกัด บริบทและการเสนอราคา ปรับวิธีการแจ้งเตือนตามนั้น
ยินดีต้อนรับความคิดเห็นทั้งหมด เปิดปัญหาหรือส่งคำขอดึงหากคุณพบข้อบกพร่องหรือมีคำแนะนำสำหรับการปรับปรุง
โครงการนี้ได้รับใบอนุญาตภายใต้: Attribution-noncommercial-noderivatives (by-nc-nd) ใบอนุญาตดู: https://creativeCommons.org/licenses/by-nc-nd/4.0/deed.en


