rl 6 nimmt
1.0.0
6 nimmt! เป็นเกมไพ่ที่ได้รับรางวัลสำหรับผู้เล่นสองถึงสิบคนจากปี 1994 อ้างถึงวิกิพีเดีย:
เกมดังกล่าวมีไพ่ 104 ใบแต่ละใบมีสัญลักษณ์หัวของวัวหนึ่งถึงเจ็ดตัวที่แสดงถึงจุดโทษ รอบสิบรอบถูกเล่นโดยผู้เล่นทุกคนวางการ์ดหนึ่งใบที่พวกเขาเลือกไว้บนโต๊ะ การ์ดที่วางจะถูกจัดเรียงในสี่แถวตามกฎที่คงที่ หากวางไว้ในแถวที่มีไพ่ห้าใบแล้วผู้เล่นจะได้รับไพ่ห้าใบซึ่งนับเป็นคะแนนโทษที่มีค่ารวมในตอนท้ายของรอบ
6 nimmt! เป็นเกมที่แข่งขันได้ของข้อมูลที่ไม่สมบูรณ์และการสุ่มจำนวนมาก การเล่นที่ดีต้องใช้การวางแผนที่ยุติธรรม เกมเล่นพร้อมกันทำให้ตัวเองเป็นเกมที่คิดและทู่ในขณะที่กลยุทธ์ระยะยาวบางอย่างจำเป็นเพื่อหลีกเลี่ยงการสิ้นสุดในตำแหน่งเกมที่ยากลำบาก
เราใช้รุ่นที่ง่ายขึ้นเล็กน้อยของ 6 NIMMT! เป็นสภาพแวดล้อมของ Openai Gym ซึ่งแตกต่างจากในเกมดั้งเดิมเมื่อเล่นไพ่ต่ำกว่าการ์ดใบสุดท้ายในทุกสแต็คผู้เล่นไม่สามารถเลือกสแต็กที่จะเปลี่ยนได้อย่างอิสระ แต่แทนที่จะใช้สแต็กด้วยคะแนนโทษน้อยที่สุด
จนถึงตอนนี้เราได้นำตัวแทนดังต่อไปนี้มาใช้:
ในการทดสอบครั้งแรกเราวิ่งทัวร์นาเมนต์เล่นเองง่าย ๆ เริ่มต้นด้วยตัวแทนที่ไม่ได้รับการฝึกฝนห้าคนเราเล่นเกมทั้งหมด 4,000 เกม สำหรับแต่ละเกมเราสุ่มเลือกตัวแทนสองสามหรือสี่ตัวเพื่อเล่น (และเรียนรู้) ทุก ๆ 400 เกมที่เราโคลนเอเจนต์ที่มีประสิทธิภาพดีที่สุดและเตะเกมที่มีประสิทธิภาพต่ำกว่า ในที่สุดเราก็เก็บอินสแตนซ์ที่ดีที่สุดของแต่ละประเภทตัวแทน
ผลลัพธ์มากกว่าเกมทั้งหมด:
| ตัวแทน | เล่นเกม | คะแนนเฉลี่ย | ชนะเศษส่วน | เอโล |
|---|---|---|---|---|
| Alpha0.5 | 2246 | -7.79 | 0.42 | 2349 |
| MCS | 2314 | -8.06 | 0.40 | 2288 |
| ACER | 1408 | -12.28 | 0.18 | 1629 |
| D3QN | 1151 | -13.32 | 0.17 | ค.ศ. 1577 |
| แบบสุ่ม | 1382 | -13.49 | 0.19 | ค.ศ. 1556 |
นี่คือวิธีที่ประสิทธิภาพ (วัดใน ELO) ของแบบจำลองที่พัฒนาขึ้นในระหว่างการแข่งขัน:
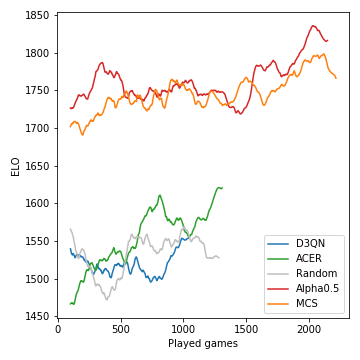
การค้นหาต้นไม้ Monte-Carlo เป็นสิ่งสำคัญและนำไปสู่ผู้เล่นที่แข็งแกร่ง ในทางกลับกันตัวแทน RL ที่ปราศจากโมเดลพยายามดิ้นรนเพื่อให้ชัดเจนกว่าพื้นฐานแบบสุ่ม เนื่องจากลักษณะสุ่มของเกมความน่าจะเป็นที่ชนะและความแตกต่างของ ELO ไม่รุนแรงเท่าที่ควรจะเป็นสำหรับหมากรุก โปรดทราบว่าเรายังไม่ได้ปรับพารามิเตอร์ไฮเปอร์พารามิเตอร์ใด ๆ
หลังจากเฟสเล่นเองนี้ตัวแทน Alpha0.5 เผชิญหน้ากับเมิร์ลซึ่งเป็นหนึ่งใน 6 NIMMT ที่ดีที่สุด! ผู้เล่นในกลุ่มเพื่อนของเราสำหรับ 5 เกม นี่คือคะแนน:
| เกม | 1 | 2 | 3 | 4 | 5 | ผลรวม |
|---|---|---|---|---|---|---|
| เมิน | -10 | -16 | -11 | -3 | -4 | -44 |
| Alpha0.5 | -1 | -3 | -14 | -8 | -6 | -32 |
สมมติว่าคุณติดตั้ง Anaconda แล้วโคลน repo ด้วย
git clone [email protected]:johannbrehmer/rl-6nimmt.git
และสร้างสภาพแวดล้อมเสมือนจริงด้วย
conda env create -f environment.yml
conda activate rl
ทั้งตัวแทนเล่นเองและเกมระหว่างผู้เล่นมนุษย์และตัวแทนที่ผ่านการฝึกอบรมจะแสดงให้เห็นใน simple_tournament.ipynb
รวบรวมโดย Johann Brehmer และ Marcel Gutsche


