kubeai
helm-chart-models-0.9.0
รับการอนุมานการทำงานบน Kubernetes: LLMS, EMBEDDINGS, คำพูดเป็นข้อความ
✅การแทนที่แบบดรอปอินสำหรับ OpenAI ด้วยความเข้ากันได้ของ API
⚖สเกลจากศูนย์อัตโนมัติตามโหลด
- ให้บริการรุ่นการสร้างข้อความ (LLMS, VLMS ฯลฯ )
คำพูดถึงข้อความ API
- การฝัง/เวกเตอร์ API
Multi-Platform: CPU-only, GPU, TPU
- การแคชแบบจำลองด้วยระบบไฟล์ที่ใช้ร่วมกัน (EFS, Filestore ฯลฯ )
การพึ่งพาศูนย์ (ไม่ได้ขึ้นอยู่กับ istio, Knative, ฯลฯ )
ui แชทรวม (openwebui)
- ใช้งานเซิร์ฟเวอร์ OSS Model (VLLM, Ollama, Fasterwhisper, Infinity)
✉การอนุมานสตรีม/แบทช์ผ่านการรวมการส่งข้อความ (Kafka, Pubsub ฯลฯ )
คำคมจากชุมชน:
โซลูชันที่ใช้ซ้ำได้และเป็นนามธรรมในการเรียกใช้ LLM - Mike Ensor
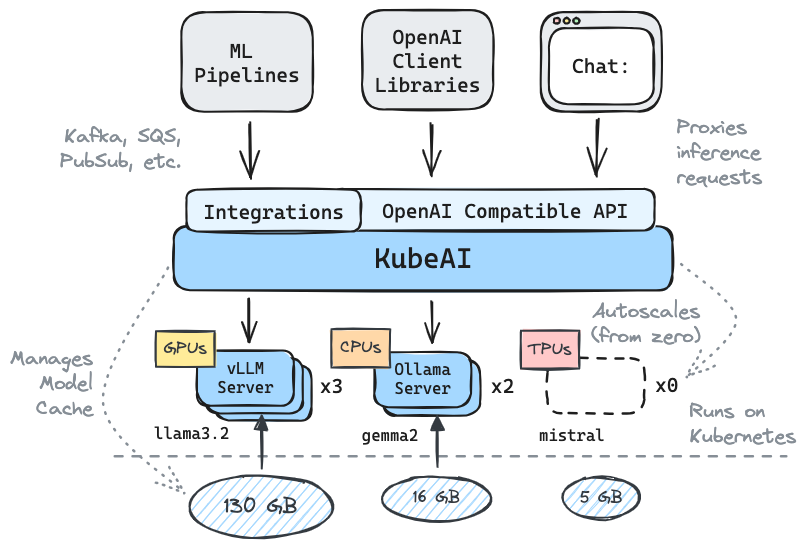
Kubeai ให้บริการ HTTP API ที่เข้ากันได้ของ OpenAI ผู้ดูแลระบบสามารถกำหนดค่าโมเดล ML ผ่าน kind: Model Kubernetes ทรัพยากรที่กำหนดเอง Kubeai สามารถคิดว่าเป็นตัวดำเนินการจำลอง (ดูรูปแบบของผู้ปฏิบัติงาน) ที่จัดการเซิร์ฟเวอร์ VLLM และ Ollama
สร้างคลัสเตอร์ท้องถิ่นโดยใช้ชนิดหรือ minikube
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startเพิ่มพื้นที่เก็บข้อมูล Kubeai Helm
helm repo add kubeai https://www.kubeai.org
helm repo updateติดตั้ง Kubeai และรอให้ส่วนประกอบทั้งหมดพร้อม (อาจใช้เวลาสักครู่)
helm install kubeai kubeai/kubeai --wait --timeout 10mติดตั้งรุ่นที่กำหนดไว้ล่วงหน้า
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlก่อนที่จะก้าวไปสู่ขั้นตอนถัดไปให้เริ่มดูพ็อดในเทอร์มินัลแบบสแตนด์อโลนเพื่อดูว่า Kubeai ปรับใช้โมเดลอย่างไร
kubectl get pods --watch เพราะเราตั้งค่า minReplicas: 1 สำหรับรุ่น Gemma คุณควรเห็นพ็อดโมเดลมาแล้ว
เริ่มต้นพอร์ตในท้องถิ่นไปยัง UI แชทแบบรวม
kubectl port-forward svc/openwebui 8000:80ตอนนี้เปิดเบราว์เซอร์ของคุณไปที่ LocalHost: 8000 และเลือกรุ่น Gemma เพื่อเริ่มการแชทด้วย
หากคุณกลับไปที่เบราว์เซอร์และเริ่มแชทกับ Qwen2 คุณจะสังเกตเห็นว่าจะต้องใช้เวลาสักครู่ในการตอบกลับในตอนแรก นี่เป็นเพราะเราตั้งค่า minReplicas: 0 สำหรับรุ่นนี้และ Kubeai จำเป็นต้องหมุนพ็อดใหม่ (คุณสามารถตรวจสอบได้ด้วย kubectl get models -oyaml qwen2-500m-cpu )
ชำระเงินเอกสารของเราเกี่ยวกับ kubeai.org เพื่อค้นหาข้อมูลเกี่ยวกับ:
รายชื่อผู้ใช้ที่รู้จัก:
| ชื่อ | คำอธิบาย | การเชื่อมโยง |
|---|---|---|
| กล้องโทรทรรศน์ | กล้องโทรทรรศน์ใช้ kubeai สำหรับการอนุมาน LLM แบบหลายภูมิภาคขนาดใหญ่ | trytelescope.ai |
| Google Cloud Distributed Edge | Kubeai รวมอยู่ในสถาปัตยกรรมอ้างอิงสำหรับการอนุมานที่ขอบ | LinkedIn, Gitlab |
| แลมบ์ดา | คุณสามารถลอง Kubeai บนคลาวด์นักพัฒนา Lambda AI ดูการสอนและวิดีโอของแลมบ์ดา | แลมบ์ดา |
หากคุณใช้ Kubeai และต้องการที่จะอยู่ในรายการเป็นผู้ใช้โปรดทำ PR
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* หมายเหตุ: Kubeai เกิดจากโครงการที่เรียกว่า Lingo ซึ่งเป็นพร็อกซี Kubernetes LLM ที่เรียบง่ายพร้อมการปรับสภาพอัตโนมัติ เราเปิดตัวโครงการใหม่เป็น Kubeai (ปลายเดือนสิงหาคม 2567) และขยายแผนงานไปสู่สิ่งที่เป็นอยู่ในปัจจุบัน
- อย่าลืมที่จะวางดาวให้เราบน GitHub และติดตาม repo เพื่อติดตามข่าวสารล่าสุด!
แจ้งให้เราทราบเกี่ยวกับคุณสมบัติที่คุณสนใจที่จะเห็นหรือติดต่อกับคำถาม เยี่ยมชมช่อง Discord ของเราเพื่อเข้าร่วมการสนทนา!
หรือเพียงแค่ติดต่อ LinkedIn หากคุณต้องการเชื่อมต่อ:


