Reading_groups
1.0.0
พลังของการคำนวณ : หลักฐานจำนวนมากแสดงให้เห็นว่าความก้าวหน้าในการเรียนรู้ของเครื่องจักรส่วนใหญ่เป็นแรงผลักดันจากการคำนวณไม่ใช่การวิจัยโปรดดูที่ "บทเรียนที่ขมขื่น" และมักจะเกิดขึ้นและปรากฏการณ์การทำให้เป็นเนื้อเดียวกัน การศึกษาแสดงให้เห็นว่าการใช้การคำนวณปัญญาประดิษฐ์เป็นสองเท่าในทุก ๆ 3.4 เดือนในขณะที่การปรับปรุงประสิทธิภาพเพียงสองเท่าทุก ๆ 16 เดือน ในหมู่พวกเขาปริมาณการคำนวณส่วนใหญ่ขับเคลื่อนด้วยกำลังการคำนวณในขณะที่ประสิทธิภาพจะถูกขับเคลื่อนโดยการวิจัย ซึ่งหมายความว่าการเติบโตของคอมพิวเตอร์มีความก้าวหน้าในอดีตในการเรียนรู้ของเครื่องจักรและฟิลด์ย่อย สิ่งนี้ได้รับการพิสูจน์เพิ่มเติมจากการเกิดขึ้นของ GPT-4 อย่างไรก็ตามเรื่องนี้เรายังต้องให้ความสนใจว่าจะมีสถาปัตยกรรมที่ล้มล้างมากขึ้นในอนาคตเช่น S4 หรือไม่ ฮอตสปอตการวิจัย NLP ปัจจุบันส่วนใหญ่ขึ้นอยู่กับ LLM ขั้นสูง (~ 100b
สำหรับเอกสารหัวข้อ LLM เพิ่มเติมโปรดดูที่นี่และที่นี่
เอกสาร ( หมวดหมู่หยาบ )
ทรัพยากร
【การทดสอบเกี่ยวกับ GPT-4, ข้อ จำกัด 】ประกายไฟของหน่วยสืบราชการลับทั่วไปประดิษฐ์: การทดลองในช่วงต้นด้วย GPT-4
【เอกสารแนะนำรวมถึง SFT, PPO ฯลฯ หนึ่งในบทความที่สำคัญที่สุด】แบบจำลองภาษาการฝึกอบรมเพื่อทำตามคำแนะนำกับข้อเสนอแนะของมนุษย์
【การกำกับดูแลที่ปรับขนาดได้: มนุษย์จะปรับปรุงแบบจำลองของพวกเขาต่อไปได้อย่างไรหลังจากโมเดลของพวกเขาเกินงานของพวกเขาเองได้อย่างไร? 】การวัดความคืบหน้าในการกำกับดูแลที่ปรับขนาดได้สำหรับแบบจำลองภาษาขนาดใหญ่
【คำจำกัดความของการจัดตำแหน่งที่ผลิตโดย DeepMind 】การจัดตำแหน่งของตัวแทนภาษา
ผู้ช่วยภาษาทั่วไปเป็นห้องปฏิบัติการสำหรับการจัดตำแหน่ง
[กระดาษย้อนยุคแบบจำลองที่ค้นหาโดยใช้ CCA+] การปรับปรุงแบบจำลองภาษาโดยการดึงโทเค็นจากล้านล้าน
แบบจำลองภาษาที่ปรับแต่งจากการตั้งค่าของมนุษย์
การฝึกอบรมผู้ช่วยที่เป็นประโยชน์และไม่เป็นอันตรายด้วยการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์
【รุ่นใหญ่ในภาษาจีนและภาษาอังกฤษเกิน GPT-3 】 GLM-130B: แบบเปิดสองภาษาแบบเปิด
【การเพิ่มประสิทธิภาพเป้าหมายก่อนการฝึกอบรม】 UL2: การรวมกระบวนทัศน์การเรียนรู้ภาษา
benchmarks ใหม่ของการจัดตำแหน่งห้องสมุดแบบจำลองและวิธีการใหม่】คือการเรียนรู้การเสริมแรง (ไม่ใช่) สำหรับการประมวลผลภาษาธรรมชาติหรือไม่: การวัดประสิทธิภาพพื้นฐานและการสร้างบล็อกสำหรับการเพิ่มประสิทธิภาพนโยบายภาษาธรรมชาติ
【 MLM โดยไม่มีแท็ก [MASK] ผ่านเทคโนโลยี】การขาดการเป็นตัวแทนในการสร้างแบบจำลองภาษาที่สวมหน้ากาก
text text to Image Training ช่วยลดความต้องการของคำศัพท์และต่อต้านการโจมตีบางอย่าง】การสร้างแบบจำลองภาษาด้วยพิกเซล
Lexmae: การเตรียมการพจนานุกรมพจนานุกรม
Incoder: แบบจำลองการกำเนิดสำหรับการแทรกซึมของรหัสและการสังเคราะห์
[ค้นหาภาพที่เกี่ยวข้องกับข้อความสำหรับรูปแบบภาษาก่อนการฝึกอบรม] การสร้างแบบจำลองภาษาที่มีการมองเห็นด้วยสายตา
รูปแบบภาษาที่ไม่ใช้โมโนโทนิก
【การเปรียบเทียบและการปรับแต่งข้อเสนอแนะเชิงลบผ่านการออกแบบแบบ propt 】โซ่ของการปรับรูปแบบของรูปแบบภาษากับข้อเสนอแนะ
【โมเดลสแปร์โรว์】การปรับปรุงการจัดตำแหน่งตัวแทนการสนทนาผ่านการตัดสินของมนุษย์เป้าหมาย
[ใช้พารามิเตอร์โมเดลขนาดเล็กเพื่อเร่งกระบวนการฝึกอบรมของแบบจำลองขนาดใหญ่ (ไม่เริ่มต้นจากศูนย์)] การเรียนรู้ที่จะเติบโตแบบจำลองที่ได้รับการฝึกฝนสำหรับการฝึกอบรมหม้อแปลงที่มีประสิทธิภาพ
[โมเดลความรู้แบบกึ่งพารามิเตอร์ MOE สำหรับแหล่งความรู้หลายแหล่ง] ความรู้ในบริบท: ไปสู่แบบจำลองภาษากึ่งพารามิเตอร์ที่มีความรู้
【วิธีการผสานสำหรับการรวมโมเดลที่ผ่านการฝึกอบรมหลายแบบในชุดข้อมูลที่แตกต่าง
[เป็นแรงบันดาลใจอย่างมากที่กลไกการค้นหาแทนที่สถาปัตยกรรมทั่วไปของ FFN ในหม้อแปลง (เวลา× 2.54) เพื่อแยกความรู้ที่เก็บไว้ในพารามิเตอร์แบบจำลอง] โมเดลภาษาพร้อมปลั๊กอินความรู้
【สร้างข้อมูลการปรับแต่งคำสั่งโดยอัตโนมัติสำหรับการฝึกอบรม GPT-3 】การสอนด้วยตนเอง: การจัดรูปแบบภาษาให้สอดคล้องกับคำแนะนำที่สร้างขึ้นด้วยตนเอง
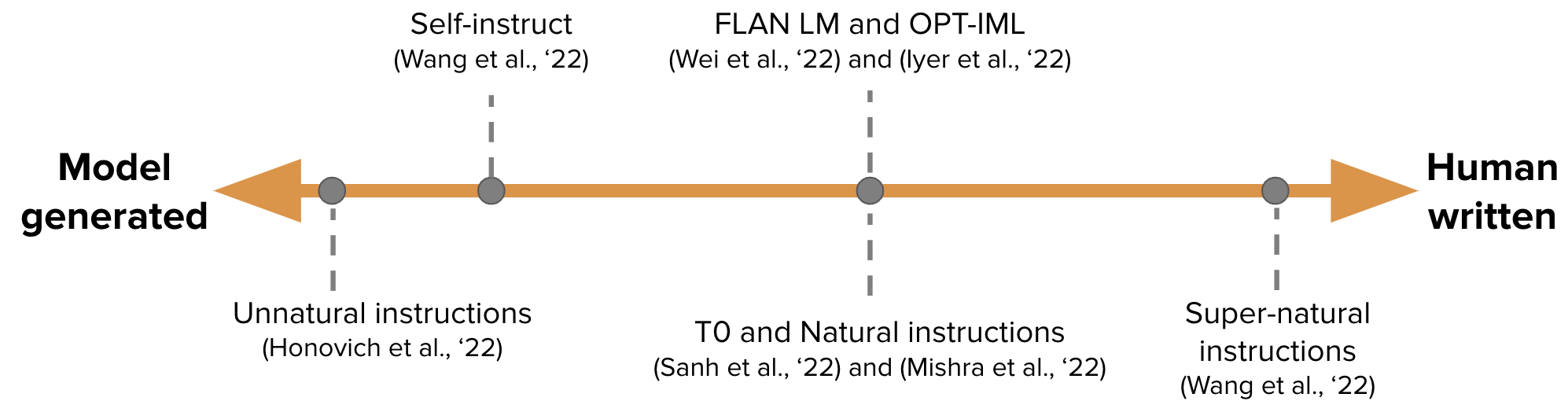
- 
ไปสู่แบบจำลองภาษาที่สวมหน้ากากตามเงื่อนไข
【การปรับเทียบการตรวจสอบอิสระที่สร้างขึ้นอย่างไม่สมบูรณ์แบบซ้ำ ๆ บทความติดตามผลของ Sean Weleck 】สร้างลำดับโดยการเรียนรู้ที่จะแก้ไขตนเอง
[การเรียนรู้อย่างต่อเนื่อง: เพิ่ม propt สำหรับงานใหม่และ propt ของงานก่อนหน้าและโมเดลขนาดใหญ่ยังคงไม่เปลี่ยนแปลง] การแจ้งเตือนแบบก้าวหน้า: การเรียนรู้อย่างต่อเนื่องสำหรับแบบจำลองภาษาโดยไม่ลืม
[EMNLP 2022, การอัปเดตอย่างต่อเนื่องของโมเดล] memprompt: การแก้ไขพรอมต์หน่วยความจำช่วยด้วยความคิดเห็นของผู้ใช้
【สถาปัตยกรรมระบบประสาทใหม่ (Folnet) ซึ่งมีอคติการเหนี่ยวนำตรรกะลำดับแรก】การเรียนรู้ภาษาการเรียนรู้ด้วยอคติเชิงตรรกะ
GANLM: การฝึกอบรมการเข้ารหัสล่วงหน้าด้วยการเลือกปฏิบัติเสริม
【แบบจำลองภาษาที่ใช้ก่อนหน้านี้ตามแบบจำลองพื้นที่ของรัฐเกินกว่าเบิร์ต】การเตรียมการโดยไม่สนใจ
[พิจารณาข้อเสนอแนะของมนุษย์ในระหว่างการฝึกอบรมก่อน] แบบจำลองภาษาที่มีความชอบของมนุษย์
[รุ่นโอเพนซอร์ส Llama ของ Meta, 7b-65b, รถไฟรุ่นเล็กที่มีป้ายกำกับมากกว่าปกติ, บรรลุประสิทธิภาพที่ดีที่สุดภายใต้งบประมาณการอนุมานที่หลากหลาย] llama: แบบเปิดและมีประสิทธิภาพ
[การสอนแบบจำลองภาษาขนาดใหญ่เพื่อการลบตัวเองและอธิบายรหัสที่สร้างขึ้นผ่านตัวอย่างจำนวนน้อย แต่พวกเขาถูกนำมาใช้เช่นนี้ในขณะนี้] การสอนแบบจำลองภาษาขนาดใหญ่เพื่อการลบตัวเอง
อูฐสามารถไปได้ไกลแค่ไหน?
ลิมา: น้อยกว่าสำหรับการจัดตำแหน่งมากขึ้น
tree Tree-of-Thout
【วิธีการให้เหตุผลหลายขั้นตอนสำหรับการใช้ ICL นั้นเป็นแรงบันดาลใจอย่างมาก】ตอบสนอง: การทำงานร่วมกันการใช้เหตุผลและทำหน้าที่ในรูปแบบภาษา
【 COT สร้างรหัสโปรแกรมโดยตรงจากนั้นให้ Python Interpreter ดำเนินการ】โปรแกรมของความคิดที่แจ้งเตือน: disentangling การคำนวณจากการให้เหตุผลสำหรับการใช้เหตุผลเชิงตัวเลข
[โมเดลขนาดใหญ่สร้างบริบทหลักฐานโดยตรง] สร้างแทนที่จะดึง: โมเดลภาษาขนาดใหญ่เป็นเครื่องกำเนิดบริบทที่แข็งแกร่ง
【รูปแบบการเขียนที่มีการดำเนินการเฉพาะ 4 การดำเนินการ】เพียร์: รูปแบบภาษาที่ทำงานร่วมกัน
【การรวม Python, SQL Executors และรุ่นใหญ่】โมเดลภาษาที่มีผลผูกพันในภาษาสัญลักษณ์
[ดึงรหัสการสร้างเอกสาร] DocPrompting: การสร้างรหัสโดยการดึงเอกสาร
[จะมีบทความมากมายในการต่อสายดิน+LLM ในซีรี่ส์ถัดไป] LLM-Planner: การวางแผนที่มีพื้นฐานไม่กี่นัดสำหรับตัวแทนที่เป็นตัวเป็นตนด้วยรูปแบบภาษาขนาดใหญ่
【การสร้างทัศนะด้วยตนเอง (ตรวจสอบโดยใช้ข้อมูลการฝึกอบรม Python) แบบจำลองภาษาสามารถสอนตัวเองให้โปรแกรมได้ดีขึ้น
บทความที่เกี่ยวข้อง: เชี่ยวชาญรูปแบบภาษาขนาดเล็กต่อการใช้เหตุผลหลายขั้นตอน
STAR: การใช้เหตุผลในการใช้เหตุผลด้วยการใช้เหตุผลจาก Neurips 22 (สร้างข้อมูล COT สำหรับการปรับแต่งแบบจำลอง) ทำให้เกิดชุดของบทความ COT ที่ตามมาสอนโมเดลขนาดเล็กที่ตามมา
ความคิดที่คล้ายกัน [การกลั่นความรู้] การสอนแบบจำลองภาษาขนาดเล็กเพื่อเหตุผลและการเรียนรู้โดยการกลั่นบริบท
ความคิดที่คล้ายกัน Kaist และ Xiang Ren Groups ([การปรับแต่งเหตุผลของ Cot (ศาสตราจารย์)] Pinto: การใช้เหตุผลภาษาที่ซื่อสัตย์โดยใช้เหตุผลที่สร้างขึ้นมาอย่างรวดเร็ว ฯลฯ ) และแบบจำลองภาษาขนาดใหญ่
ETH [COT Data Trains การสลายตัวของปัญหาการสลายตัวและแบบจำลองการแก้ปัญหาแยกกัน] กลั่นความสามารถในการใช้เหตุผลหลายขั้นตอนของแบบจำลองภาษาขนาดใหญ่เป็นแบบจำลองขนาดเล็กผ่านการสลายตัวทางความหมาย
【ให้แบบจำลองขนาดเล็กเรียนรู้ความสามารถของ COT 】การกลั่นการเรียนรู้ในบริบท: การถ่ายโอนความสามารถในการเรียนรู้ไม่กี่ครั้งของแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อน
【โมเดลขนาดใหญ่สอนรูปแบบขนาดเล็ก cot 】แบบจำลองภาษาขนาดใหญ่คือการให้เหตุผลครู
[โมเดลขนาดใหญ่สร้างหลักฐาน (การบรรยาย) จากนั้นดำเนินการคำถามและคำตอบในหนังสือตัวอย่างขนาดเล็ก] แบบจำลองภาษาที่มีการท่องจำ
[วิธีการภาษาธรรมชาติของเหตุผลเชิงอุปนัย] แบบจำลองภาษาเป็นเหตุผลเชิงอุปนัย
[GPT-3 ใช้สำหรับคำอธิบายประกอบข้อมูล (เช่นการจำแนกทางอารมณ์)] GPT-3 เป็นคำอธิบายประกอบข้อมูลที่ดีหรือไม่?
【โมเดลสำหรับการเพิ่มข้อมูลตามการฝึกอบรมมัลติทาสกิ้งสำหรับการเพิ่มข้อมูลตัวอย่างที่น้อยลง】 Knowda: แบบจำลองการผสมความรู้แบบ all-in-one สำหรับการเพิ่มข้อมูลใน NLP ที่มีทรัพยากรต่ำ
【งานการวางแผนขั้นตอนไม่สนใจเวลาที่】การวางแผนขั้นตอน neuro-symbolic ด้วยการแจ้งเตือนแบบทั่วไป
[วัตถุประสงค์: สร้างบทความที่ถูกต้องตามข้อเท็จจริงสำหรับการสอบถามโดยการลงดินบนเว็บคลังข้อมูลขนาดใหญ่
【การรวมผลลัพธ์ของตัวจำลองฟิสิกส์ภายนอกในบริบท】สายตาของจิตใจ: แบบจำลองภาษาที่มีเหตุผลการให้เหตุผลผ่านการจำลอง
[เรียกคืน COT ที่ได้รับการปรับปรุงเพื่อทำภารกิจที่ต้องใช้ความรู้] การดึงข้อมูล interleave ด้วยการใช้เหตุผลที่ใช้ความรู้สำหรับคำถามหลายขั้นตอนความรู้ที่ใช้ความรู้มาก
【เปรียบเทียบความรู้ที่มีศักยภาพ (ไบนารี) ในรูปแบบภาษาการรับรู้ที่ไม่ได้รับการยอมรับ】การค้นพบความรู้แฝงในรูปแบบภาษาโดยไม่มีการกำกับดูแล
[Percy Liang Group, เครื่องมือค้นหาที่เชื่อถือได้มีเพียง 51.5% ของประโยคที่สร้างขึ้นได้รับการสนับสนุนอย่างเต็มที่จากการอ้างอิง] การประเมินความสามารถในการตรวจสอบในเครื่องมือค้นหาทั่วไป
การเปิดใช้งานแบบก้าวหน้าช่วยปรับปรุงการใช้เหตุผลในรูปแบบภาษาขนาดใหญ่
การจัดตำแหน่งตนเองของแบบจำลองภาษาที่ขับเคลื่อนด้วยหลักการตั้งแต่เริ่มต้นด้วยการกำกับดูแลของมนุษย์น้อยที่สุด
ตัดสิน LLM-as-a-Judge กับ MT-Bench และ Chatbot Arena
[ในความคิดของฉันมันเป็นหนึ่งในบทความที่สำคัญที่สุด การฝึกอบรมและความกว้างและความลึกของรายละเอียดสถาปัตยกรรมเช่นความกว้างและความลึก
[หนึ่งในบทความที่สำคัญที่สุดอื่น ๆ คือ Chinchilla ภายใต้การคำนวณที่ จำกัด โมเดลที่ดีที่สุดไม่ใช่โมเดลที่ใหญ่ที่สุด แต่เป็นโมเดลขนาดเล็กที่ได้รับการฝึกฝนด้วยข้อมูลเพิ่มเติม (60-70B)] การฝึกอบรมแบบจำลองการคำนวณที่ดีที่สุด
[สถาปัตยกรรมและเป้าหมายการเพิ่มประสิทธิภาพใดที่ช่วยให้ภาพรวมตัวอย่างเป็นศูนย์] สถาปัตยกรรมแบบจำลองภาษาใดและวัตถุประสงค์การเตรียมการที่ดีที่สุดสำหรับการวางนัยทั่วไป
【 grokking กระบวนการเรียนรู้กระบวนการเรียนรู้“ Epiphany”-> การก่อตัวของวงจร-> การทำความสะอาด】มาตรการความคืบหน้าสำหรับการ grokking ผ่านการตีความกลไก
[ตรวจสอบลักษณะของโมเดลการค้นหาและพบว่าทั้งสองมีเหตุผลที่ จำกัด ] สามารถตอบกลับแบบจำลองภาษาที่มีเหตุผลได้หรือไม่?
[กรอบการประเมินการปฏิสัมพันธ์ภาษาของมนุษย์-เอ] การประเมินการปฏิสัมพันธ์แบบจำลองภาษามนุษย์
อัลกอริทึมการเรียนรู้อะไรคือการเรียนรู้ในบริบท?
【การแก้ไขแบบจำลองนี่เป็นหัวข้อร้อน】หน่วยความจำการแก้ไขมวลชนในหม้อแปลง
[ความอ่อนไหวของโมเดลต่อบริบทที่ไม่เกี่ยวข้องเพิ่มข้อมูลที่ไม่เกี่ยวข้องกับตัวอย่างในการแจ้งเตือนและเพิ่มคำแนะนำที่ไม่สนใจบริบทที่ไม่เกี่ยวข้องบางส่วน] โมเดลภาษาขนาดใหญ่สามารถเบี่ยงเบนความสนใจได้ง่ายโดยบริบทที่ไม่เกี่ยวข้อง
cot Zero-shot จะแสดงอคติและความเป็นพิษภายใต้ปัญหาที่ละเอียดอ่อน】ในความคิดที่สองอย่าคิดทีละขั้นตอน!
cot ของโมเดลขนาดใหญ่มีความสามารถข้ามภาษา】โมเดลภาษาเป็นเหตุผลหลายภาษาที่หลากหลาย
[ยิ่งระดับความสับสนลดลงของลำดับที่แตกต่างกันเท่าใดประสิทธิภาพที่ดีกว่า] การแจ้งเตือนการส่งเสียงในแบบจำลองภาษาผ่านการประมาณความงุนงง
[ภารกิจการแก้ไขความหมายของไบนารีของโมเดลขนาดใหญ่ข้อเสนอแนะนี้เป็นเรื่องยากและไม่มีปรากฏการณ์การปรับขนาด] แบบจำลองภาษาขนาดใหญ่ไม่ใช่นักสื่อสารที่ไม่ได้เป็นศูนย์ (https://github.com/google/big-bench/tree/main/bigbench/ Benchmark_tasks/ Implicity)
【การแจ้งเตือนตามความซับซ้อนสำหรับการใช้เหตุผลหลายขั้นตอน
สิ่งที่สำคัญในการตัดแต่งกิ่งที่มีโครงสร้างของแบบจำลองภาษากำเนิด?
[ชุดข้อมูล Ambibench, ความคลุมเครือของงาน: โมเดลการปรับขนาด RLHF ทำงานได้ดีที่สุดในการทำงานที่ไม่น่าเชื่อ การปรับแต่งมีประโยชน์มากกว่าการกระตุ้นไม่กี่ครั้ง】ความคลุมเครือของงานในมนุษย์และโมเดลภาษา
【การทดสอบ GPT-3 รวมถึงหน่วยความจำการสอบเทียบอคติ ฯลฯ 】การแจ้งเตือน GPT-3 ให้ความน่าเชื่อถือ
[การศึกษา OSU ส่วนใดของ COT นั้นมีประสิทธิภาพสำหรับการปฏิบัติงาน] ต่อการทำความเข้าใจการกระตุ้นด้วยความคิดของห่วงโซ่: การศึกษาเชิงประจักษ์เกี่ยวกับสิ่งที่สำคัญ
[การวิจัยเกี่ยวกับรูปแบบข้ามภาษาของพรอมต์แบบไม่ต่อเนื่อง] การสกัดข้อมูลแบบไม่ต่อเนื่องสามารถแจ้งให้ทั่วไปทราบในแบบจำลองภาษาได้หรือไม่?
【อัตราหน่วยความจำคือความสัมพันธ์เชิงเส้นลอการิทึมกับขนาดของรุ่นความยาวคำนำหน้าและอัตราการทำซ้ำในการฝึกอบรม】การท่องจำเชิงปริมาณในแบบจำลองภาษาประสาท
【มันเป็นแรงบันดาลใจอย่างมากสลายปัญหาเป็นคำถามย่อยผ่านการทำซ้ำ GPT และตอบว่าการวัดและการ จำกัด ช่องว่างการเรียงความในรูปแบบภาษา
[การทดสอบแบบอะนาล็อกของ GPT-3 คล้ายกับคำถามข่าวกรองของข้าราชการพลเรือน] การใช้เหตุผลแบบอะนาล็อกที่เกิดขึ้นในแบบจำลองภาษาขนาดใหญ่
【การฝึกอบรมข้อความสั้นการทดสอบข้อความยาวการประเมินความยาวตัวแปรแบบจำลองความยาวการปรับตัว】หม้อแปลงความยาวที่มีความยาว
[เมื่อไม่เชื่อถือแบบจำลองภาษา: การตรวจสอบประสิทธิภาพและข้อ จำกัด ของความทรงจำแบบพารามิเตอร์และไม่ใช่พารามิเตอร์
【 ICL เป็นอีกรูปแบบหนึ่งของการอัปเดตการไล่ระดับสี】ทำไม GPT สามารถเรียนรู้ในบริบทได้หรือไม่?
GPT-3 เป็นโรคจิตหรือไม่?
[การวิจัยเกี่ยวกับกระบวนการฝึกอบรมแบบจำลอง OPT ในขนาดที่แตกต่างกันและพบว่าความสับสนเป็นตัวบ่งชี้ของ ICL] วิถีการฝึกอบรมของแบบจำลองภาษาในระดับสเกล
[EMNLP 2022, คลังภาษาอังกฤษบริสุทธิ์ที่ผ่านการฝึกอบรมมาก่อนมีภาษาอื่น ๆ และความสามารถข้ามภาษาของโมเดลอาจมาจากการรั่วไหลของข้อมูล] การปนเปื้อนภาษาช่วยอธิบายความสามารถข้ามภาษาของแบบจำลองภาษาอังกฤษ
[การเอาชนะนักบวช semantic และการใช้ข้อมูลใน ProPT เป็นความสามารถในการเพิ่มขึ้น] แบบจำลองภาษาขนาดใหญ่ทำในบริบทการเรียนรู้ที่แตกต่างกัน
【 EMNLP 2022 การค้นพบ】รูปแบบภาษาใดที่จะฝึกอบรมถ้าคุณมีหนึ่งล้าน GPU ชั่วโมง?
[แนะนำเทคโนโลยี CFG ในระหว่างการให้เหตุผลช่วยปรับปรุงความสามารถในการปฏิบัติตามคำสั่งของโมเดลขนาดเล็กอย่างมาก] อยู่ในหัวข้อด้วยคำแนะนำที่ปราศจากตัวจําแนก
【ฝึกอบรมนางแบบ Llama ของคุณเองด้วย GPT-4 ของ OpenAi และฉันสามารถพูดได้ว่าฉันชื่นชมคุณ】การปรับแต่งคำแนะนำด้วย GPT-4
Reflexion: ตัวแทนอิสระที่มีหน่วยความจำแบบไดนามิกและการสะท้อนตนเอง
【การเรียนรู้สไตล์ที่เป็นส่วนตัวเลือกใช้ profts extensible สำหรับโมเดลภาษา
[เร่งการถอดรหัสแบบจำลองขนาดใหญ่โดยใช้ฉันทามติโดยตรงระหว่างรุ่นขนาดเล็กและรุ่นขนาดใหญ่ที่จะใช้หลายครั้งในแต่ละครั้งหลังจากทั้งหมดอินพุตจะช้ามากถ้ามันยาว] เร่งการถอดรหัสแบบจำลองภาษาขนาดใหญ่พร้อมการสุ่มตัวอย่างพิเศษ
[ใช้ Soft Prompt เพื่อลดการลดลงของความสามารถของ ICL ที่เกิดจากการปรับแต่งอย่างละเอียดการปรับระยะแรกการปรับระยะที่สอง] รักษาความสามารถในการเรียนรู้ในบริบทในรูปแบบภาษาขนาดใหญ่ปรับแต่งการปรับแต่งการปรับแต่ง
【งานการแยกวิเคราะห์ความหมายวิธีการเลือกตัวอย่างของ ICL, Codex และ T5 ขนาดใหญ่】การสาธิตที่หลากหลายปรับปรุงการปรับแต่งทั่วไปในบริบท
【วิธีการเพิ่มประสิทธิภาพใหม่สำหรับการสร้างข้อความ】โมเดลการสร้างภาษาที่ปรับแต่งภายใต้ระยะการเปลี่ยนแปลงทั้งหมด
[การประเมินความไม่แน่นอนของการสร้างแบบมีเงื่อนไขโดยใช้การจัดกลุ่มความหมายรวมกับเอาต์พุตการสุ่มตัวอย่างหลายรายการเพื่อประเมินเอนโทรปีของกลุ่ม] ความไม่แน่นอนเชิงความหมาย: ค่าคงที่ภาษาศาสตร์เพื่อการประมาณความไม่แน่นอนในการสร้างภาษาธรรมชาติ
Go-tuning: การปรับปรุงความสามารถในการเรียนรู้แบบไม่ยิงของแบบจำลองภาษาขนาดเล็ก
【วิธีการสร้างข้อความที่สร้างแรงบันดาลใจอย่างมากภายใต้ข้อ จำกัด ข้อความฟรี】การสร้างข้อความที่ควบคุมได้พร้อมข้อ จำกัด ด้านภาษา
[เมื่อสร้างการทำนายให้ใช้ความคล้ายคลึงกันเพื่อเลือกวลีแทนโทเค็น softmax] การสร้างแบบจำลองภาษาที่ไม่ใช่พารามิเตอร์
[วิธี ICL สำหรับข้อความยาว] หน้าต่างบริบทแบบขนานปรับปรุงการเรียนรู้ในบริบทของแบบจำลองภาษาขนาดใหญ่
[ตัวอย่างของ Model InstructGPT ที่สร้าง ICL ด้วยตัวเอง] การเตรียมแบบจำลองภาษาขนาดใหญ่สำหรับการเปิดโดเมน QA ด้วยตนเอง
[ICL สามารถป้อนตัวอย่างคำอธิบายประกอบได้มากขึ้นผ่านการจัดกลุ่มและกลไกความสนใจ] การแจ้งเตือนที่มีโครงสร้าง: การปรับขนาดการเรียนรู้ในบริบทเป็น 1,000 ตัวอย่าง
การสอบเทียบโมเมนตัมสำหรับการสร้างข้อความ
【วิธีการเลือกตัวอย่าง ICL สองวิธีการทดลองตาม OPT และ GPTJ 】การดูแลข้อมูลอย่างระมัดระวังทำให้การเรียนรู้ในบริบทมีความเสถียร
【การวิเคราะห์ตัวบ่งชี้การประเมินของ MAUVE (Pundla et al.) 】เกี่ยวกับประโยชน์ของการฝังตัวกลุ่มและสตริงสำหรับการประเมินการสร้างข้อความ
PreftingAgator: การดึงข้อมูลหนาแน่นไม่กี่ครั้งจาก 8 ตัวอย่าง
[สาม Cobblers, Zhuge Liang] ความสม่ำเสมอ
[Invert, Input และ Label สร้างคำแนะนำสำหรับเงื่อนไข] เดาคำสั่ง!
【การตรวจสอบตนเองแบบย้อนกลับของ LLM แบบจำลองภาษาขนาดใหญ่เป็นเหตุผลในการตรวจสอบตนเอง
【วิธีการในการค้นหา - สถานการณ์ความปลอดภัยภายใต้กระบวนการสร้างหลักฐาน】 foveate, คุณลักษณะและการหาเหตุผลเข้าข้างตนเอง: ไปสู่ความปลอดภัยและความน่าเชื่อถือ AI
[การประเมินความเชื่อมั่นของชิ้นส่วนการสกัดข้อมูลที่สร้างขึ้นจากข้อความตามการค้นหาลำแสง] การค้นหาลำแสงช่วยปรับปรุงการประมาณความเชื่อมั่นระดับในระดับในการติดฉลากลำดับกำเนิดได้อย่างไร
SPT: การปรับจูนแบบกึ่งพารามิเตอร์สำหรับมัลติทาสก์แจ้งเตือนการเรียนรู้
【การอภิปรายเกี่ยวกับฉลากทองคำสรุปที่แยกออกมา】การสรุปข้อความด้วยความคาดหวังของ Oracle
【วิธีการตรวจจับ Ood ตามระยะทางของดาวอังคาร】การตรวจจับนอกการกระจายและการสร้างแบบเลือกสำหรับแบบจำลองภาษาแบบมีเงื่อนไข
[โมดูลความสนใจรวมพร้อมกันเพื่อทำนายระดับตัวอย่าง] โมเดลชุดแทนที่จะเป็นฟิวชั่นที่รวดเร็ว: วิธีการถ่ายโอนความรู้เฉพาะตัวอย่างสำหรับการปรับแต่ง
【พร้อมท์สำหรับงานหลายงานโดยการสลายตัวและการกลั่นเป็นหนึ่งเดียวกับการปรับจูนแบบมัลติทาสก์
[ตัวบ่งชี้การประเมินผลของข้อความที่สร้างขึ้นทีละขั้นตอนข้อความที่สร้างขึ้นสามารถใช้เป็นหัวข้อที่จะแบ่งปันในครั้งต่อไป] Roscoe: ชุดตัวชี้วัดสำหรับการให้คะแนนการใช้เหตุผลทีละขั้นตอน
[การสอบเทียบลำดับความน่าจะเป็นช่วยปรับปรุงการสร้างภาษาแบบมีเงื่อนไข]
【วิธีการโจมตีข้อความตามการเพิ่มประสิทธิภาพการไล่ระดับสี】 TextGRAD: การประเมินความแข็งแกร่งในการเพิ่มความแข็งแกร่งใน NLP โดยการเพิ่มประสิทธิภาพที่ขับเคลื่อนด้วยการไล่ระดับสี
[การสร้างแบบจำลอง GMM การจำแนกประเภทการตัดสินใจของ ICL เพื่อสอบเทียบ] การสอบเทียบต้นแบบสำหรับการเรียนรู้แบบจำลองภาษาไม่กี่แบบ
【ปัญหาการเขียนใหม่และวิธีการรวม ICL ที่ใช้กราฟ】ถามฉันทุกอย่าง: กลยุทธ์ง่ายๆสำหรับการแจ้งรูปแบบภาษา
[ฐานข้อมูลสำหรับการเลือกผู้สมัครที่ดีเป็น ICLs จากกลุ่มตัวอย่างที่ไม่ได้บันทึกไว้] คำอธิบายประกอบที่เลือกทำให้แบบจำลองภาษาดีขึ้นผู้เรียนไม่กี่คน
พรอมต์ BOOSTING: การจำแนกข้อความกล่องดำด้วยบัตรผ่านไปข้างหน้าสิบครั้ง
การโจมตีแบ็คดอร์ที่ได้รับความสนใจจาก Transformers
【ตำแหน่งหน้ากากการเลือกฉลากอัตโนมัติตำแหน่ง】โมเดลภาษาที่ผ่านการฝึกอบรมมาก่อนสามารถเป็นศูนย์ผู้เรียนได้อย่างสมบูรณ์
[บีบอัดความยาวของเวกเตอร์อินพุต FID และจัดลำดับใหม่เมื่อเอาท์พุทไปยังการจัดอันดับเอกสารเอาต์พุต] FID-LIGHT: การสร้างข้อความที่มีประสิทธิภาพและมีประสิทธิภาพและมีประสิทธิภาพ
【คำอธิบายเกี่ยวกับการสร้างโมเดลขนาดใหญ่】ปินโต: การใช้เหตุผลภาษาที่ซื่อสัตย์โดยใช้เหตุผลที่ได้รับแจ้ง
【ค้นหาชุดย่อยของผลกระทบก่อนการฝึกอบรม】 orca: การตีความโมเดลภาษาที่ได้รับแจ้งผ่านหลักฐานที่สนับสนุนสถานที่ในมหาสมุทรแห่งข้อมูลการเตรียมการ
[โครงการพรอมต์มุ่งเป้าไปที่การเรียนการสอนสร้างขั้นตอนแรกและการกรองการเรียงลำดับสองขั้นตอน] แบบจำลองภาษาขนาดใหญ่เป็นวิศวกรที่มีระดับมนุษย์
ความรู้ที่ไม่ได้รับรู้เพื่อลดความเสี่ยงด้านความเป็นส่วนตัวในรูปแบบภาษา
แบบจำลองการแก้ไขด้วยเลขคณิตงาน
[อย่าป้อนคำแนะนำและตัวอย่างทุกครั้งแปลงเป็นโมดูลที่มีประสิทธิภาพพารามิเตอร์] คำใบ้: การปรับแต่งคำสั่ง Hypernetwork
[วิธีการสร้างการแสดงผล ICL โดยไม่ต้องเลือกตัวอย่างด้วยตนเอง] Z-ICL: การเรียนรู้แบบไม่ต้องใช้ในบริบทด้วยการหลอกแบบหลอก
[คำสั่งงานและข้อความสร้างการฝังอยู่ด้วยกัน] หนึ่ง EMBEDDER งานใด ๆ : การฝังข้อความคำสั่ง
【โมเดลขนาดใหญ่การสอนรูปแบบขนาดเล็ก cot 】มีด: การกลั่นความรู้ด้วยเหตุผลข้อความฟรี
[ปัญหาของความไม่สอดคล้องกันระหว่างแหล่งที่มาและการแบ่งส่วนคำเป้าหมายของโมเดลการสร้างการสกัดข้อมูล] ความสอดคล้องของโทเค็นการทำให้เกิดความสอดคล้องสำหรับแบบจำลองการกำเนิดในงาน NLP สกัด
Parsel: กรอบภาษาธรรมชาติแบบครบวงจรสำหรับการใช้เหตุผลอัลกอริทึม
[การเลือกตัวอย่าง ICL, การเลือกระยะแรกและการเรียงลำดับระยะที่สอง] การปรับเปลี่ยนการเรียนรู้ด้วยตนเองในบริบท
[การอ่านอย่างเข้มข้น, วิธีการเลือกที่ไม่ได้รับอนุญาตที่อ่านได้, GPT-2] ไปยังการปรับจูนพร้อมที่มนุษย์อ่านได้: Kubrick's The Shining เป็นภาพยนตร์ที่ดีและเป็นพรอมต์ที่ดีเช่นกัน
【ชุดข้อมูล Prontoqa ทดสอบความสามารถในการอนุมานของ COT และพบว่าความสามารถในการวางแผนยังคงมีข้อ จำกัด 】แบบจำลองภาษาสามารถ (ชนิดของ) เหตุผล: การวิเคราะห์อย่างเป็นทางการอย่างเป็นระบบของห่วงโซ่ของความคิด
【ชุดข้อมูลการใช้เหตุผล】 wikiwhy: การตอบและอธิบายคำถามสาเหตุและผลกระทบ
【ชุดข้อมูลการใช้เหตุผล】 Street: การใช้เหตุผลเชิงโครงสร้างแบบหลายงานและมาตรฐานคำอธิบาย
【ชุดข้อมูลการใช้เหตุผลเปรียบเทียบการฝึกอบรมก่อนการฝึกอบรมและการปรับแต่งอย่างละเอียดรวมถึงรูปแบบการปรับแต่ง COT 】การแจ้งเตือน: การปรับรูปแบบภาษาให้เข้ากับงานให้เหตุผล
[บทสรุปของการใช้เหตุผลล่าสุดโดยทีมจางหนิงวของมหาวิทยาลัยเจ้อเจียง] การให้เหตุผลด้วยการกระตุ้นแบบจำลองภาษา: การสำรวจ
[สรุปเทคโนโลยีการสร้างข้อความและทิศทางโดยทีมงานของ Xiao Yanghua ใน Fudan] การควบคุมความรู้และการให้เหตุผลสำหรับการสร้างภาษาธรรมชาติเหมือนมนุษย์: บทวิจารณ์สั้น ๆ
[สรุปบทความเหตุผลล่าสุด Jie Huang จาก UIUC] ไปสู่การให้เหตุผลในรูปแบบภาษาขนาดใหญ่: การสำรวจ
【การทบทวนงานชุดข้อมูลและวิธีการใช้เหตุผลทางคณิตศาสตร์และ DL 】การสำรวจการเรียนรู้อย่างลึกซึ้งสำหรับการใช้เหตุผลทางคณิตศาสตร์
การสำรวจการประมวลผลภาษาธรรมชาติสำหรับการเขียนโปรแกรม
ชุดข้อมูลการสร้างแบบจำลองรางวัล:
Red-teaming数据集,harmless vs. helpful, RLHF +scale更难被攻击(另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


