dalle flow
1.0.0


มนุษย์ในวง ? เวิร์กโฟลว์สำหรับการสร้างภาพ HD จากข้อความ
Dall · E Flow เป็นเวิร์กโฟลว์แบบโต้ตอบสำหรับการสร้างภาพความละเอียดสูงจากข้อความแจ้งข้อความ อันดับแรกมันใช้ประโยชน์จาก Dall · E-MEGA, GLID-3 XL และการแพร่กระจายที่เสถียรเพื่อสร้างผู้สมัครภาพจากนั้นเรียก clip-as-service เพื่อจัดอันดับผู้สมัคร WRT พร้อมท์ ผู้สมัครที่ต้องการจะถูกป้อนให้กับ GLID-3 XL สำหรับการแพร่กระจายซึ่งมักจะเพิ่มประสิทธิภาพของพื้นผิวและพื้นหลัง ในที่สุดผู้สมัครจะได้รับการลดขนาดถึง 1024x1024 ผ่าน Swinir
Dall · E Flow ถูกสร้างขึ้นด้วย Jina ในสถาปัตยกรรมไคลเอนต์-เซิร์ฟเวอร์ซึ่งให้ความยืดหยุ่นสูงการสตรีมมิ่งที่ไม่ปิดกั้นและอินเทอร์เฟซ Pythonic ที่ทันสมัย ไคลเอนต์สามารถโต้ตอบกับเซิร์ฟเวอร์ผ่าน GRPC/WebSocket/HTTP ด้วย TLS
ทำไมต้องเป็นมนุษย์? ศิลปะการกำเนิดเป็นกระบวนการสร้างสรรค์ ในขณะที่ความก้าวหน้าล่าสุดของ Dall · E ปลดปล่อยความคิดสร้างสรรค์ของผู้คน แต่การมี UX/UI ที่ได้รับการรับรองเพียงครั้งเดียวล็อคจินตนาการไปสู่ความเป็นไป ได้เดียว ซึ่งไม่ดีไม่ว่าผลลัพธ์เดียวนี้จะดีแค่ไหน Dall · E Flow เป็นทางเลือกหนึ่งสำหรับ One-Liner โดยการทำให้ศิลปะการกำเนิดเป็นแบบเป็นทางการเป็นขั้นตอนการวนซ้ำ
Dall · E Flow อยู่ในสถาปัตยกรรมไคลเอนต์-เซิร์ฟเวอร์
grpcs://api.clip.jina.ai:2096 (ต้องใช้ jina >= v3.11.0 ) คุณต้องได้รับโทเค็นการเข้าถึงก่อน ดูใช้ Clip-as Service สำหรับรายละเอียดเพิ่มเติมflow_parser.pygrpcs://dalle-flow.dev.jina.ai การเชื่อมต่อทั้งหมดอยู่ในขณะนี้ด้วยการเข้ารหัส TLS โปรด เปิด สมุดบันทึกใน Google Colab อีกครั้งp2.x8largeViT-L/14@336px จาก Clip-AS-Service steps 100->200















































การใช้ไคลเอนต์นั้นง่ายมาก ขั้นตอนต่อไปนี้ทำงานได้ดีที่สุดใน Jupyter Notebook หรือ Google Colab
คุณจะต้องติดตั้ง Docarray และ Jina ก่อน:
pip install " docarray[common]>=0.13.5 " jinaเราได้จัดเตรียมเซิร์ฟเวอร์ตัวอย่างให้คุณเล่น:
เนื่องจากคำขอจำนวนมากเซิร์ฟเวอร์ของเราอาจล่าช้าในการตอบสนอง แต่เรามีความมั่นใจ มาก ในการรักษาเวลาให้สูงขึ้น คุณสามารถปรับใช้เซิร์ฟเวอร์ของคุณเองได้โดยทำตามคำสั่งที่นี่
server_url = 'grpcs://dalle-flow.dev.jina.ai'ตอนนี้เรามากำหนดพรอมต์:
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'มาส่งไปยังเซิร์ฟเวอร์และแสดงภาพผลลัพธ์:
from docarray import Document
doc = Document ( text = prompt ). post ( server_url , parameters = { 'num_images' : 8 })
da = doc . matches
da . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) ที่นี่เราสร้างผู้สมัคร 24 คน 8 จาก Dalle-Mega, 8 จาก Glid3 XL และ 8 จากการแพร่กระจายที่เสถียรซึ่งกำหนดไว้ใน num_images ซึ่งใช้เวลาประมาณ 2 นาที คุณสามารถใช้ค่าที่เล็กกว่าถ้ามันยาวเกินไปสำหรับคุณ

ผู้สมัคร 24 คนถูกจัดเรียงโดยคลิป-ตามบริการโดยมีดัชนี 0 เป็นผู้สมัครที่ดีที่สุดที่ตัดสินโดยคลิป แน่นอนคุณอาจคิดแตกต่างกัน สังเกตหมายเลขที่มุมบนซ้าย? เลือกอันที่คุณชอบมากที่สุดและรับมุมมองที่ดีกว่า:
fav_id = 3
fav = da [ fav_id ]
fav . embedding = doc . embedding
fav . display ()
ตอนนี้เรามาส่งผู้สมัครที่เลือกไปยังเซิร์ฟเวอร์เพื่อการแพร่กระจาย
diffused = fav . post ( f' { server_url } ' , parameters = { 'skip_rate' : 0.5 , 'num_images' : 36 }, target_executor = 'diffusion' ). matches
diffused . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) สิ่งนี้จะให้ 36 ภาพตามภาพที่เลือก คุณอาจอนุญาตให้โมเดลโพล่งออกมาได้มากขึ้นโดยให้ค่า skip_rate ค่าใกล้ศูนย์หรือค่าใกล้หนึ่งเพื่อบังคับให้ใกล้ชิดกับภาพที่กำหนด ขั้นตอนทั้งหมดใช้เวลาประมาณ 2 นาที

เลือกภาพที่คุณชอบมากที่สุดและให้ดูใกล้ชิดยิ่งขึ้น:
dfav_id = 34
fav = diffused [ dfav_id ]
fav . display ()
สุดท้ายส่งไปยังเซิร์ฟเวอร์สำหรับขั้นตอนสุดท้าย: การเพิ่มอัตราการเพิ่มขึ้นถึง 1024 x 1024px
fav = fav . post ( f' { server_url } /upscale' )
fav . display ()แค่ไหน! มันเป็น หนึ่ง หากไม่พอใจโปรดทำซ้ำขั้นตอน

BTW, Docarray เป็นโครงสร้างข้อมูลที่ทรงพลังและใช้งานง่ายสำหรับข้อมูลที่ไม่มีโครงสร้าง มันเป็นประโยชน์สูงสุดสำหรับนักวิทยาศาสตร์ข้อมูลที่ทำงานในโดเมนข้าม/หลายโหมด หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ Docarray โปรดตรวจสอบเอกสาร
คุณสามารถโฮสต์เซิร์ฟเวอร์ของคุณเองโดยทำตามคำสั่งด้านล่าง
Dall · E Flow ต้องการหนึ่ง GPU ที่มี 21GB VRAM ที่จุดสูงสุด บริการทั้งหมดถูกบีบลงใน GPU นี้ซึ่งรวมถึง (ประมาณ)
config.yml , 512x512)เทคนิคที่สมเหตุสมผลต่อไปนี้สามารถใช้เพื่อลด VRAM เพิ่มเติม:
ต้องใช้พื้นที่ว่างอย่างน้อย 50GB บนฮาร์ดไดรฟ์ส่วนใหญ่สำหรับการดาวน์โหลดรุ่นที่ผ่านการฝึกอบรม
ต้องใช้อินเทอร์เน็ตความเร็วสูง อินเทอร์เน็ตช้า/ไม่เสถียรอาจทำให้หมดเวลาที่น่าผิดหวังเมื่อดาวน์โหลดรุ่น
สภาพแวดล้อม CPU เท่านั้นไม่ได้ทดสอบและมีแนวโน้มว่าจะไม่ทำงาน Google Colab มีแนวโน้มที่จะโยน oom ดังนั้นจึงไม่ทำงาน

หากคุณติดตั้ง Jina แล้วผังงานด้านบนสามารถสร้างได้ผ่าน:
# pip install jina
jina export flowchart flow.yml flow.svgหากคุณต้องการใช้การแพร่กระจายที่มั่นคงคุณจะต้องลงทะเบียนบัญชีบนเว็บไซต์ HuggingFace และยอมรับข้อกำหนดและเงื่อนไขสำหรับรุ่น หลังจากเข้าสู่ระบบคุณสามารถค้นหารุ่นของรุ่นที่ต้องการได้โดยไปที่นี่:
compvis / sd-v1-5-inpainting.ckpt
ภายใต้ส่วน ดาวน์โหลด The Weights คลิกลิงก์สำหรับ sd-v1-x.ckpt น้ำหนักล่าสุดในเวลาที่เขียนคือ sd-v1-5.ckpt
ผู้ใช้ Docker : ใส่ไฟล์นี้ลงในโฟลเดอร์ชื่อ ldm/stable-diffusion-v1 และเปลี่ยนชื่อ It model.ckpt ทำตามคำแนะนำด้านล่างอย่างระมัดระวังเนื่องจาก SD ไม่ได้เปิดใช้งานโดยค่าเริ่มต้น
ผู้ใช้เนทีฟ : ใส่ไฟล์นี้ลงใน dalle/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt หลังจากเสร็จสิ้นขั้นตอนที่เหลือภายใต้ "Run Natively" ทำตามคำแนะนำด้านล่างอย่างระมัดระวังเนื่องจาก SD ไม่ได้เปิดใช้งานโดยค่าเริ่มต้น
เราได้จัดทำอิมเมจนักเทียบท่า prebuilt ที่สามารถดึงได้โดยตรง
docker pull jinaai/dalle-flow:latestเราได้จัดเตรียม DockerFile ซึ่งช่วยให้คุณเรียกใช้เซิร์ฟเวอร์ออกจากกล่อง
DockerFile ของเราใช้ CUDA 11.6 เป็นภาพพื้นฐานคุณอาจต้องการปรับมันตามระบบของคุณ
git clone https://github.com/jina-ai/dalle-flow.git
cd dalle-flow
docker build --build-arg GROUP_ID= $( id -g ${USER} ) --build-arg USER_ID= $( id -u ${USER} ) -t jinaai/dalle-flow .อาคารจะใช้เวลา 10 นาทีโดยมีความเร็วอินเทอร์เน็ตโดยเฉลี่ยซึ่งส่งผลให้เกิดภาพนักเทียบท่า 18GB
เพื่อเรียกใช้เพียงทำ:
docker run -p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowหรือคุณอาจทำงานกับเวิร์กโฟลว์บางอย่างที่เปิดใช้งานหรือปิดใช้งานเพื่อป้องกันการล่มของหน่วยความจำนอกหน่วยความจำ ในการทำเช่นนั้นให้ผ่านตัวแปรสภาพแวดล้อมหนึ่งเหล่านี้:
DISABLE_DALLE_MEGA
DISABLE_GLID3XL
DISABLE_SWINIR
ENABLE_STABLE_DIFFUSION
ENABLE_CLIPSEG
ENABLE_REALESRGAN
ตัวอย่างเช่นหากคุณต้องการปิดใช้งานเวิร์กโฟลว์ glid3xl ให้เรียกใช้:
docker run -e DISABLE_GLID3XL= ' 1 '
-p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow-v $HOME/.cache:/root/.cache หลีกเลี่ยงการดาวน์โหลดโมเดลซ้ำ ๆ ในการเรียกใช้ Docker ทุกครั้ง-p 51005:51005 เป็นพอร์ตสาธารณะโฮสต์ของคุณ ตรวจสอบให้แน่ใจว่าผู้คนสามารถเข้าถึงพอร์ตนี้ได้หากคุณให้บริการสาธารณะ พาร์ที่สองของมันคือพอร์ตที่กำหนดไว้ใน flow.ymlENABLE_STABLE_DIFFUSIONENABLE_CLIPSEGENABLE_REALESRGAN การแพร่กระจายที่เสถียรสามารถเปิดใช้งานได้เฉพาะในกรณีที่คุณดาวน์โหลดน้ำหนักและทำให้พวกเขาสามารถใช้เป็นระดับเสียงเสมือนจริงในขณะที่เปิดใช้งานธงสิ่งแวดล้อม ( ENABLE_STABLE_DIFFUSION ) สำหรับ SD
ก่อนหน้านี้คุณควรใส่น้ำหนักลงในโฟลเดอร์ชื่อ ldm/stable-diffusion-v1 และระบุว่า model.ckpt แทนที่ YOUR_MODEL_PATH/ldm ด้านล่างด้วยเส้นทางในระบบของคุณเองเพื่อส่งน้ำหนักลงในอิมเมจนักเทียบท่า
docker run -e ENABLE_STABLE_DIFFUSION= " 1 "
-e DISABLE_DALLE_MEGA= " 1 "
-e DISABLE_GLID3XL= " 1 "
-p 51005:51005
-it
-v YOUR_MODEL_PATH/ldm:/dalle/stable-diffusion/models/ldm/
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowคุณควรเห็นหน้าจอเช่นติดตามเมื่อทำงาน:
โปรดทราบว่าแตกต่างจากการทำงานโดยธรรมชาติการทำงานภายใน Docker อาจให้ความก้าวหน้าที่สดใสน้อยลงแท่นบันทึกสีและการพิมพ์ นี่เป็นเพราะข้อ จำกัด ของเทอร์มินัลในคอนเทนเนอร์ Docker มันไม่ส่งผลกระทบต่อการใช้งานจริง
การวิ่งตามธรรมชาติต้องใช้ขั้นตอนด้วยตนเองบางอย่าง แต่มักจะดีกว่าในการดีบัก
mkdir dalle && cd dalle
git clone https://github.com/jina-ai/dalle-flow.git
git clone https://github.com/jina-ai/SwinIR.git
git clone --branch v0.0.15 https://github.com/AmericanPresidentJimmyCarter/stable-diffusion.git
git clone https://github.com/CompVis/latent-diffusion.git
git clone https://github.com/jina-ai/glid-3-xl.git
git clone https://github.com/timojl/clipseg.gitคุณควรมีโครงสร้างโฟลเดอร์ต่อไปนี้:
dalle/
|
|-- Real-ESRGAN/
|-- SwinIR/
|-- clipseg/
|-- dalle-flow/
|-- glid-3-xl/
|-- latent-diffusion/
|-- stable-diffusion/
cd dalle-flow
python3 -m virtualenv env
source env/bin/activate && cd -
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pip install numpy tqdm pytorch_lightning einops numpy omegaconf
pip install https://github.com/crowsonkb/k-diffusion/archive/master.zip
pip install git+https://github.com/AmericanPresidentJimmyCarter/[email protected]
pip install basicsr facexlib gfpgan
pip install realesrgan
pip install https://github.com/AmericanPresidentJimmyCarter/xformers-builds/raw/master/cu116/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl &&
cd latent-diffusion && pip install -e . && cd -
cd stable-diffusion && pip install -e . && cd -
cd SwinIR && pip install -e . && cd -
cd glid-3-xl && pip install -e . && cd -
cd clipseg && pip install -e . && cd -มีสองสามรุ่นที่เราต้องดาวน์โหลดสำหรับ GLID-3-XL หากคุณใช้สิ่งนั้น:
cd glid-3-xl
wget https://dall-3.com/models/glid-3-xl/bert.pt
wget https://dall-3.com/models/glid-3-xl/kl-f8.pt
wget https://dall-3.com/models/glid-3-xl/finetune.pt
cd - ทั้ง clipseg และ RealESRGAN ต้องการให้คุณตั้งค่าเส้นทางโฟลเดอร์แคชที่ถูกต้องโดยทั่วไปจะเป็น $ HOME/
cd dalle-flow
pip install -r requirements.txt
pip install jax~=0.3.24 ตอนนี้คุณอยู่ภายใต้ dalle-flow/ รันคำสั่งต่อไปนี้:
# Optionally disable some generative models with the following flags when
# using flow_parser.py:
# --disable-dalle-mega
# --disable-glid3xl
# --disable-swinir
# --enable-stable-diffusion
python flow_parser.py
jina flow --uses flow.tmp.ymlคุณควรเห็นหน้าจอนี้ทันที:

ในการเริ่มต้นครั้งแรกจะใช้เวลา ~ 8 นาทีในการดาวน์โหลดโมเดล Mega Dall · E และรุ่นที่จำเป็นอื่น ๆ การดำเนินการดำเนินการควรใช้เวลาประมาณ 1 นาทีในการเข้าถึงข้อความความสำเร็จ
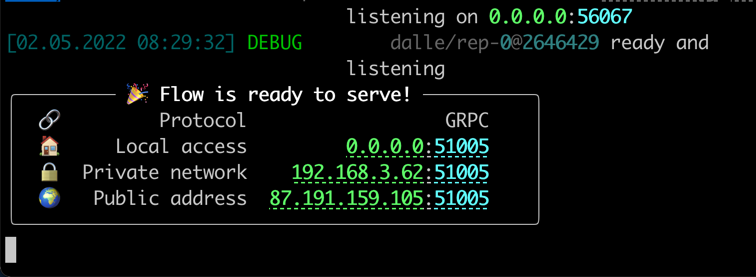
เมื่อทุกอย่างพร้อมคุณจะเห็น:
ยินดีด้วย! ตอนนี้คุณควรจะสามารถเรียกใช้ไคลเอนต์ได้
คุณสามารถแก้ไขและขยายการไหลของเซิร์ฟเวอร์ตามที่คุณต้องการเช่นการเปลี่ยนโมเดลเพิ่มการคงอยู่หรือแม้กระทั่งการโพสต์อัตโนมัติเป็น Instagram/OpenSea ด้วย Jina และ Docarray คุณสามารถสร้าง Dall · E Flow Cloud-Native ได้อย่างง่ายดายและพร้อมสำหรับการผลิต
เพื่อลดการใช้งาน VRAM คุณสามารถใช้ CLIP-as-service เป็นผู้ดำเนินการภายนอกได้อย่างอิสระที่ grpcs://api.clip.jina.ai:2096
ก่อนอื่นตรวจสอบให้แน่ใจว่าคุณได้สร้างโทเค็นการเข้าถึงจากเว็บไซต์คอนโซลหรือ CLI ดังต่อไปนี้
jina auth token create < name of PAT > -e < expiration days > จากนั้นคุณต้องเปลี่ยนการกำหนดค่าที่เกี่ยวข้องกับผู้บริหาร ( host , port , external , tls และ grpc_metadata ) จาก flow.yml
...
- name : clip_encoder
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [gateway]
...
- name : rerank
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
uses_requests :
' / ' : rank
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [dalle, diffusion] นอกจากนี้คุณยังสามารถใช้ flow_parser.py เพื่อสร้างและเรียกใช้โฟลว์โดยใช้ CLIP-as-service เป็นผู้ดำเนินการภายนอกโดยอัตโนมัติ:
python flow_parser.py --cas-token " <your access token>'
jina flow --uses flow.tmp.yml
grpc_metadataใช้ได้หลังจาก Jinav3.11.0เท่านั้น หากคุณใช้เวอร์ชันเก่าโปรดอัปเกรดเป็นเวอร์ชันล่าสุด
ตอนนี้คุณสามารถใช้ CLIP-as-service ฟรีในการไหลของคุณ
Dall · E Flow ได้รับการสนับสนุนโดย Jina Ai และได้รับใบอนุญาตภายใต้ Apache-2.0 เรากำลังจ้างวิศวกร AI วิศวกรโซลูชันเพื่อสร้างระบบนิเวศการค้นหาประสาทต่อไปในโอเพนซอร์ซ


