Deep RL Keras
1.0.0
การใช้งานแบบแยกส่วนของอัลกอริทึมการเรียนรู้การเสริมแรงลึกที่เป็นที่นิยมใน Keras:
การใช้งานนี้ต้องใช้ Keras 2.1.6 เช่นเดียวกับ Openai Gym
$ pip install gym keras==2.1.6อัลกอริทึมนักแสดงนักแสดงเป็นวิธีการที่ปราศจากโมเดลนโยบายที่นักวิจารณ์ทำหน้าที่เป็นตัวประมาณค่าฟังก์ชั่นค่าและนักแสดงเป็นตัวประมาณค่านโยบาย เมื่อการฝึกอบรมนักวิจารณ์ทำนายข้อผิดพลาด TD และนำทางการเรียนรู้ของทั้งตัวเองและนักแสดง ในทางปฏิบัติเราประมาณ TD-error โดยใช้ฟังก์ชัน Advantage เพื่อความมั่นคงมากขึ้นเราใช้กระดูกสันหลังการคำนวณที่ใช้ร่วมกันในทั้งสองเครือข่ายรวมถึงสูตร N ขั้นตอนของรางวัลลดราคา นอกจากนี้เรายังรวมคำศัพท์การทำให้เป็นมาตรฐานของเอนโทรปี ("อ่อนนุ่ม") เพื่อส่งเสริมการสำรวจ ในขณะที่ A2C นั้นเรียบง่ายและมีประสิทธิภาพ แต่การเรียกใช้เกม Atari อย่างรวดเร็วกลายเป็นเรื่องยากเนื่องจากเวลาการคำนวณที่ยาวนาน
ในทำนองเดียวกันกับอัลกอริทึม A2C การใช้งานของ A3C รวมเอาการอัปเดตน้ำหนักแบบอะซิงโครนัสทำให้สามารถคำนวณได้เร็วขึ้นมาก เราใช้เอเจนต์หลายตัวเพื่อทำการไล่ระดับสีแบบอะซิงโครนัสมากกว่าหลายเธรด เราทดสอบ A3C เกี่ยวกับสภาพแวดล้อมการฝ่าวงล้อมอาตาริ
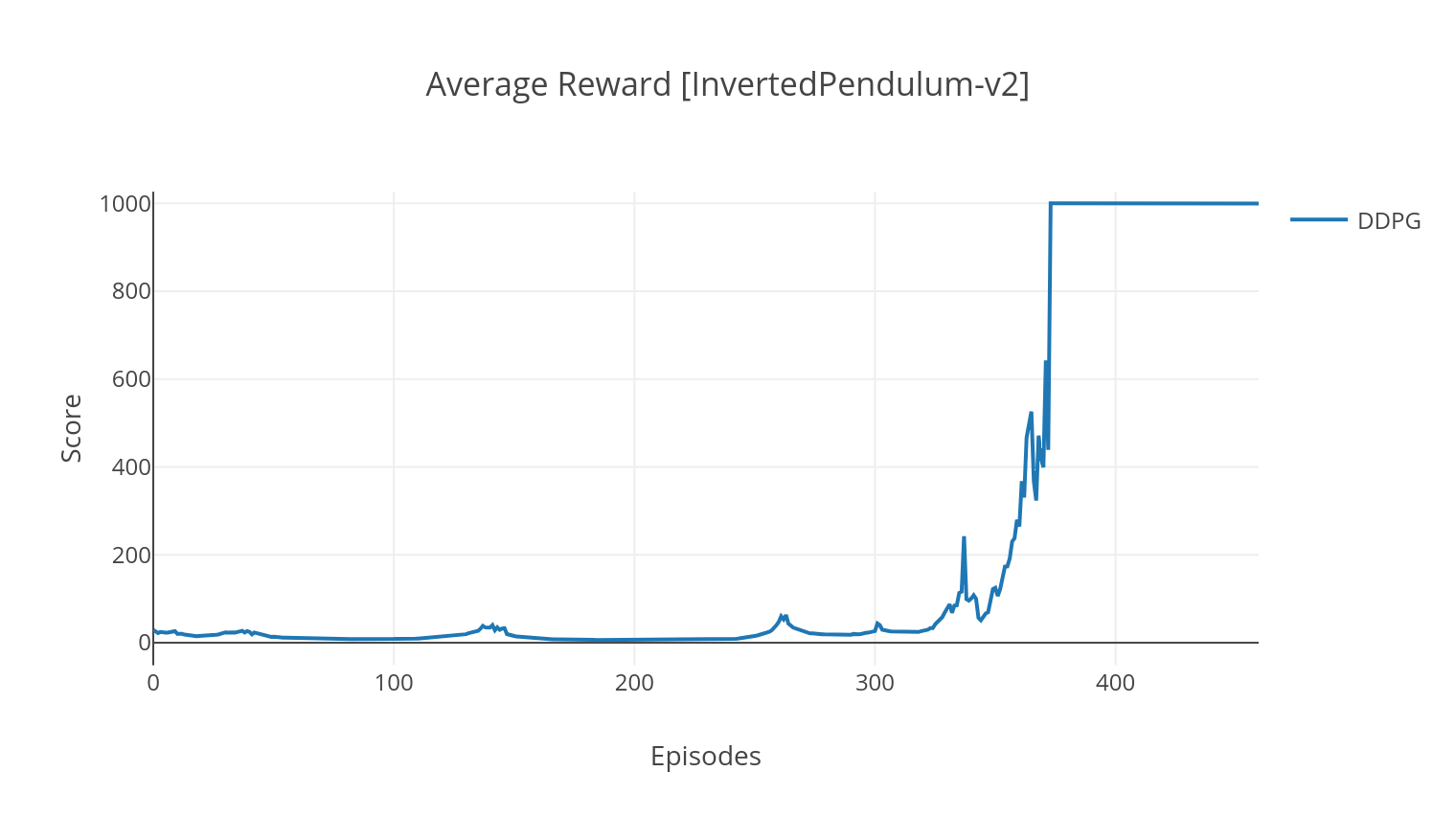
อัลกอริทึม DDPG เป็นอัลกอริทึมแบบจำลองนอกนโยบายสำหรับพื้นที่แอ็คชั่นต่อเนื่อง ในทำนองเดียวกันกับ A2C มันเป็นอัลกอริทึมนักแสดงนักแสดงที่นักแสดงได้รับการฝึกฝนเกี่ยวกับนโยบายเป้าหมายที่กำหนดและนักวิจารณ์ทำนายค่า Q เพื่อลดความแปรปรวนและเพิ่มเสถียรภาพเราใช้ประสบการณ์การเล่นซ้ำและเครือข่ายเป้าหมายแยกต่างหาก ยิ่งกว่านั้นตามคำแนะนำของ OpenAI เราสนับสนุนการสำรวจผ่านเสียงอวกาศพารามิเตอร์ (ตรงข้ามกับเสียงอวกาศแบบดั้งเดิม) เราทดสอบ DDPG เกี่ยวกับสภาพแวดล้อมทางจันทรคติ Lander
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2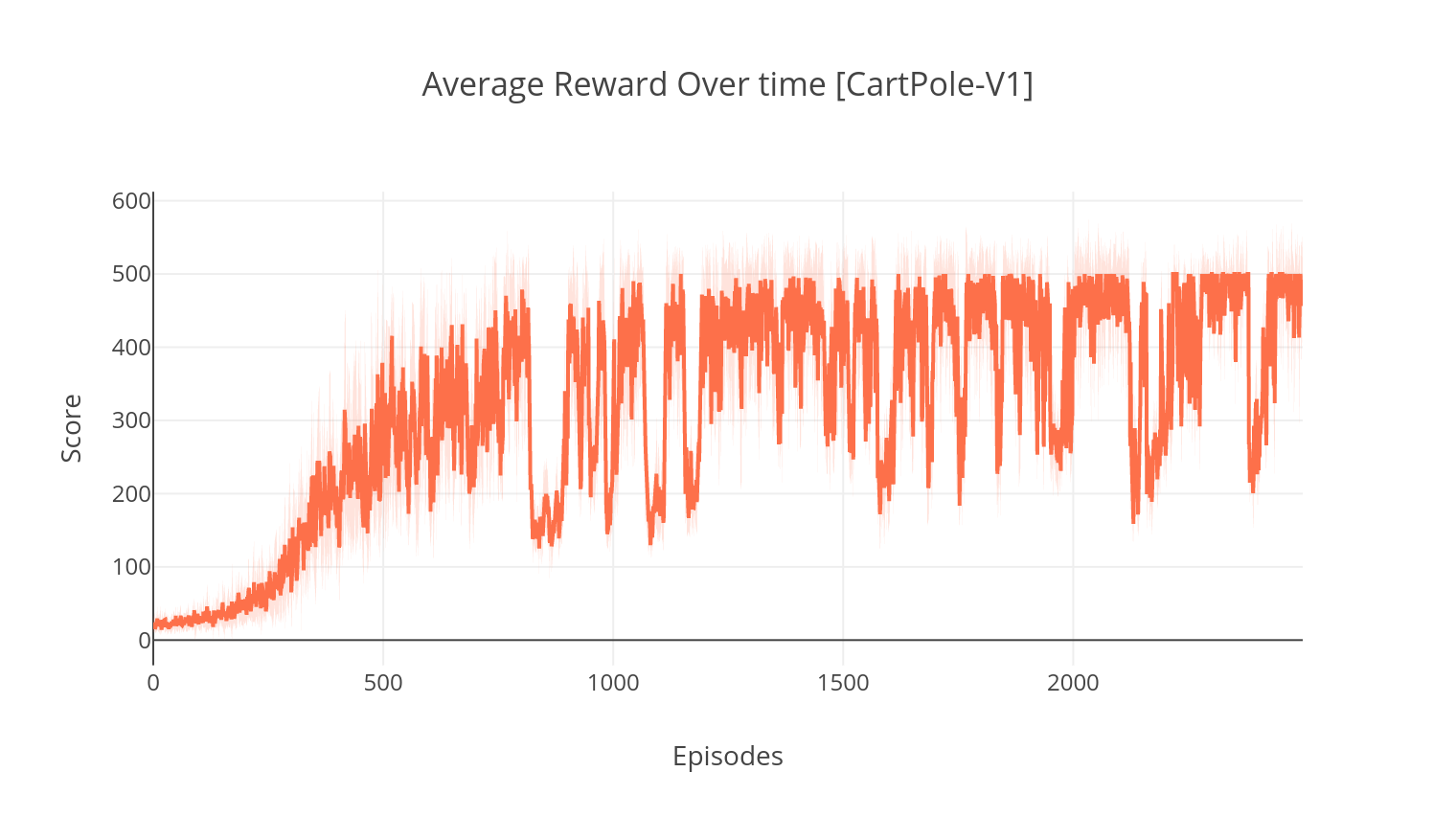
อัลกอริทึม DQN เป็นอัลกอริทึม Q-Learning ซึ่งใช้เครือข่ายประสาทลึกเป็นตัวประมาณฟังก์ชั่น Q-value เราประเมินค่า q เป้าหมายโดยใช้ประโยชน์จากสมการ Bellman และรวบรวมประสบการณ์ผ่านนโยบาย Epsilon-Greedy เพื่อความเสถียรมากขึ้นเราได้ลองชิมประสบการณ์ที่ผ่านมาแบบสุ่ม (ประสบการณ์เล่นซ้ำ) ตัวแปรของอัลกอริทึม DQN คือ double-DQN (หรือ DDQN) สำหรับการประมาณค่า Q ที่แม่นยำยิ่งขึ้นเราใช้เครือข่ายที่สองเพื่อปรับค่าการประเมินค่าสูงเกินไปของค่า Q โดยเครือข่ายดั้งเดิม เครือข่าย เป้าหมาย นี้ได้รับการอัปเดตในอัตราเอกภาพที่ช้าลงในทุกขั้นตอนการฝึกอบรม
เราสามารถปรับปรุงอัลกอริทึม DDQN ของเราได้โดยการเพิ่มประสบการณ์การเล่นซ้ำ (ต่อ) ซึ่งมีจุดมุ่งหมายในการสุ่มตัวอย่างที่สำคัญในประสบการณ์ที่รวบรวมได้ ประสบการณ์ได้รับการจัดอันดับโดย TD-error และเก็บไว้ในโครงสร้าง sumtree ซึ่งช่วยให้การดึง (s, a, r, s ') มีประสิทธิภาพ
ในตัวแปรการดวลของ DQN เราได้รวมเลเยอร์กลางใน Q-network เพื่อประเมินทั้งค่าสถานะและฟังก์ชันความได้เปรียบขึ้นอยู่กับสถานะ หลังจากการปฏิรูป (ดูอ้างอิง) ปรากฎว่าเราสามารถแสดงค่า q โดยประมาณเป็นค่าของรัฐซึ่งเราเพิ่มการประเมินความได้เปรียบและลบค่าเฉลี่ยของมัน การแยกตัวประกอบของค่านิยมที่ไม่ขึ้นอยู่กับรัฐและขึ้นอยู่กับรัฐช่วยลดการเรียนรู้ข้ามการกระทำและให้ผลลัพธ์ที่ดีขึ้น
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling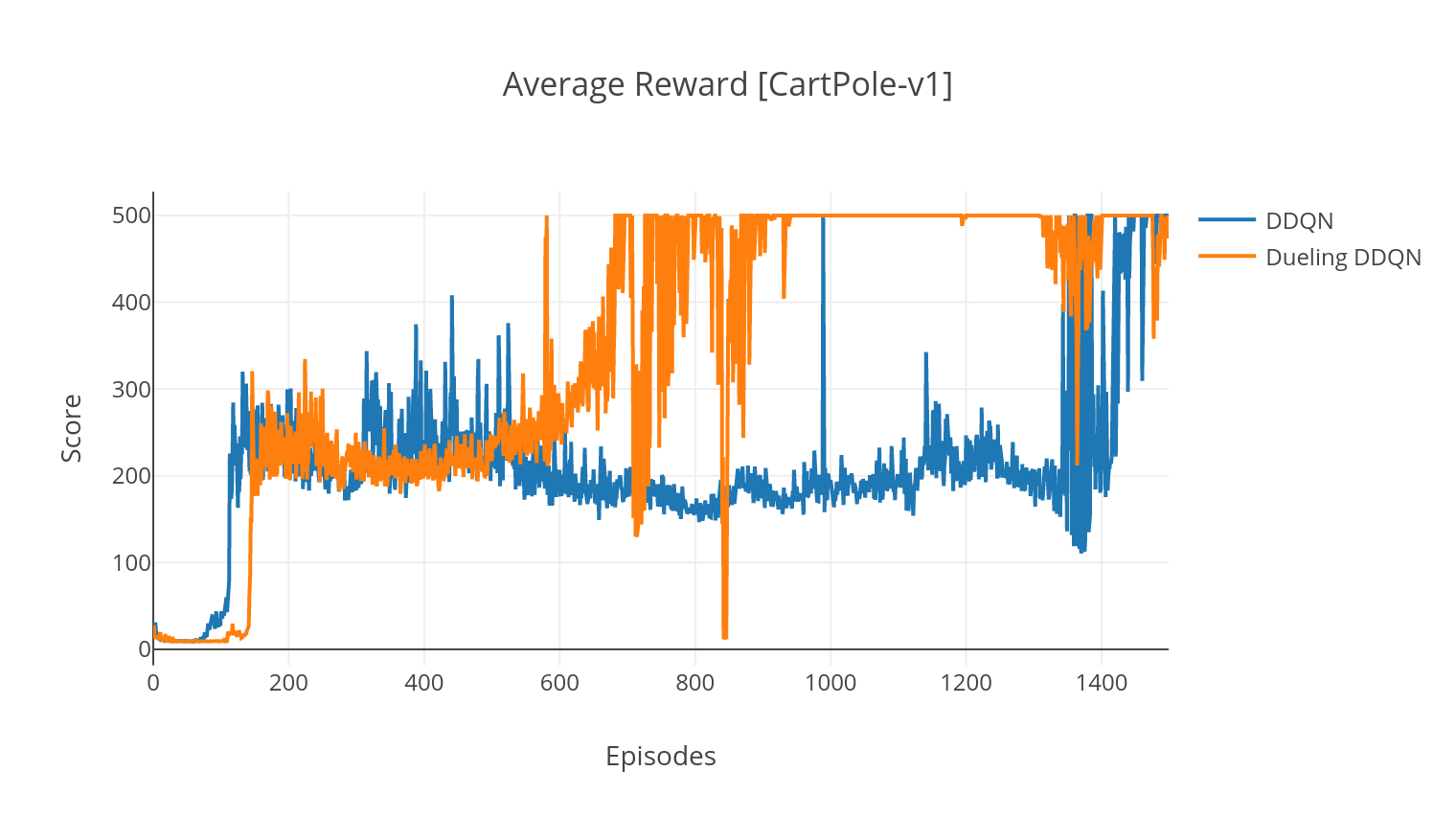
| การโต้แย้ง | คำอธิบาย | ค่า |
|---|---|---|
| --พิมพ์ | ประเภทของอัลกอริทึม RL ที่จะทำงาน | เลือกจาก {A2C, A3C, DDQN, DDPG} |
| -Env | ระบุสภาพแวดล้อม | BreakoutNoframeskip-V4 (ค่าเริ่มต้น) |
| -nb_episodes | จำนวนตอนที่จะวิ่ง | 5000 (ค่าเริ่มต้น) |
| -batch_size | ขนาดแบทช์ (DDQN, DDPG) | 32 (ค่าเริ่มต้น) |
| --conesecutive_frames | จำนวนเฟรมติดต่อกันแบบซ้อนกัน | 4 (ค่าเริ่มต้น) |
| -is_atari | ไม่ว่าสภาพแวดล้อมจะเป็นเกมอาตาริที่มีอินพุตพิกเซล | - |
| --with_per | ไม่ว่าจะใช้ประสบการณ์การเล่นซ้ำที่จัดลำดับความสำคัญ (กับ DDQN) | - |
| -การดลส์ | ไม่ว่าจะใช้เครือข่ายการดวล (กับ DDQN) | - |
| -n_threads | จำนวนเธรด (A3C) | 16 (ค่าเริ่มต้น) |
| -gather_stats | ไม่ว่าจะคำนวณสถิติคะแนนเฉลี่ยมากกว่า 10 เกม (ช้าดูด้านล่าง) | - |
| -แสดงผล | ไม่ว่าจะทำให้สภาพแวดล้อมเป็นอย่างไร | - |
| -gpu | ดัชนี GPU | 0 |
ทุกรุ่นจะถูกบันทึกภายใต้ <algorithm_folder>/models/ เมื่อการฝึกอบรมเสร็จสิ้น คุณสามารถเห็นภาพพวกเขาทำงานในสภาพแวดล้อมเดียวกันกับที่พวกเขาได้รับการฝึกฝนโดยใช้สคริปต์ load_and_run.py สำหรับโมเดล DQN คุณควรระบุเส้นทางไปยังโมเดลที่ต้องการในอาร์กิวเมนต์ --model_path สำหรับโมเดลนักแสดง-นักวิจารณ์คุณต้องระบุไฟล์น้ำหนักทั้งสองในข้อโต้แย้ง --actor_path และ --critic_path
การใช้ Tensorboard คุณสามารถตรวจสอบคะแนนของตัวแทนได้เนื่องจากเป็นการฝึกอบรม เมื่อการฝึกอบรมโฟลเดอร์บันทึกที่มีชื่อตรงกับสภาพแวดล้อมที่เลือกจะถูกสร้างขึ้น ตัวอย่างเช่นในการติดตามความก้าวหน้าของ A2C บน cartpole-V1 เพียงแค่เรียกใช้:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ เมื่อการฝึกอบรมกับอาร์กิวเมนต์ --gather_stats ไฟล์บันทึกจะถูกสร้างขึ้นที่มีคะแนนเฉลี่ยมากกว่า 10 เกมในทุกตอน: logs.csv การใช้พล็อตคุณสามารถเห็นภาพรางวัลเฉลี่ยต่อตอน ในการทำเช่นนั้นคุณจะต้องติดตั้งพล็อตและรับใบอนุญาตฟรี
pip3 install plotlyในการตั้งค่าข้อมูลรับรองของคุณ Run:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )ในที่สุดเพื่อพล็อตผลลัพธ์เรียกใช้:
python3 utils/plot_results.py < path_to_your_log_file >

