
[คำแนะนำที่เกี่ยวข้อง: วิดีโอสอน JavaScript, ส่วนหน้าของเว็บ]
ไม่ว่าคุณจะใช้ภาษาการเขียนโปรแกรมใด สตริงก็เป็นประเภทข้อมูลที่สำคัญ ติดตามฉันเพื่อเรียนรู้เพิ่มเติมเกี่ยวกับสตริง JavaScript !
สตริงคือสตริงที่ประกอบด้วยอักขระ หากคุณเคยศึกษา C และ Java คุณควรรู้ว่าอักขระเหล่านั้นสามารถกลายเป็นประเภทอิสระได้เช่นกัน อย่างไรก็ตาม JavaScript ไม่มีประเภทอักขระเดียว มีเพียงสตริงที่มีความยาว 1 เท่านั้น
สตริง JavaScript ใช้การเข้ารหัส UTF-16 แบบคงที่ ไม่ว่าเราจะใช้การเข้ารหัสแบบใดในการเขียนโปรแกรม ก็จะไม่ได้รับผลกระทบ
สตริง: เครื่องหมายคำพูดเดี่ยว เครื่องหมายคำพูดคู่ และ backticks
la single = 'abcdefg';//เครื่องหมายคำพูดเดี่ยว let double = "asdfghj";//เครื่องหมายคำพูดคู่ let backti = `zxcvbnm`;//Backticks
เครื่องหมายคำพูดเดี่ยวและเครื่องหมายคู่มีสถานะเดียวกัน เราไม่ได้สร้างความแตกต่าง
การจัดรูปแบบสตริง
backticks ช่วยให้เราสามารถจัดรูปแบบสตริงได้อย่างสวยงามโดยใช้ ${...} แทนที่จะใช้การเพิ่มสตริง
ให้ str = `ฉันอายุ ${Math.round(18.5)} ปี.`;console.log(str) ;

สตริงแบบหลายบรรทัด
ยังอนุญาตให้สตริงขยายบรรทัดได้ ซึ่งมีประโยชน์มากเมื่อเราเขียนสตริงแบบหลายบรรทัด
Let ques = `ผู้เขียนหล่อไหม? ก. หล่อมาก; ข. หล่อมาก; C. สุดยอดหล่อ;`;console.log(ques)
;
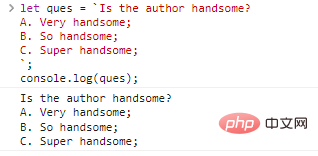
ดูเหมือนว่าจะไม่มีอะไรผิดปกติใช่ไหม? แต่สิ่งนี้ไม่สามารถทำได้โดยใช้เครื่องหมายคำพูดเดี่ยวและคู่ หากคุณต้องการผลลัพธ์ที่เหมือนกัน คุณสามารถเขียนดังนี้:
ให้ ques = 'ผู้เขียนหล่อไหม?nA. หล่อมาก;nC. หล่อสุดๆ;'; console.log(ques);
โค้ดด้านบนมีอักขระพิเศษ n ซึ่งเป็นอักขระพิเศษที่พบบ่อยที่สุดในขั้นตอนการเขียนโปรแกรมของเรา
n หรือที่เรียกว่า "อักขระขึ้นบรรทัดใหม่" รองรับเครื่องหมายคำพูดเดี่ยวและคู่เพื่อส่งออกสตริงหลายบรรทัด เมื่อเครื่องยนต์ส่งออกสตริง หากพบ n เครื่องยนต์ก็จะส่งออกต่อไปในบรรทัดอื่น ดังนั้นจึงรับรู้ถึงสตริงหลายบรรทัด
แม้ว่า n จะปรากฏเป็นอักขระสองตัว แต่จะใช้ตำแหน่งอักขระเดียวเท่านั้น เนื่องจาก เป็น อักขระหลีก ในสตริง และอักขระที่แก้ไขโดยอักขระหลีกกลายเป็นอักขระพิเศษ
รายการอักขระพิเศษ
| คำอธิบาย | อักขระพิเศษ | |
|---|---|---|
n | อักขระขึ้นบรรทัดใหม่ ใช้เพื่อเริ่มบรรทัดใหม่ของข้อความเอาต์พุต | |
r | จะเลื่อนเคอร์เซอร์ไปที่จุดเริ่มต้นของบรรทัด ในระบบ Windows rn ถูกใช้เพื่อแสดงการขึ้นบรรทัดใหม่ ซึ่งหมายความว่าเคอร์เซอร์จะต้องไปที่จุดเริ่มต้นของบรรทัดก่อน จากนั้น ไปยังบรรทัดถัดไปก่อนที่จะสามารถเปลี่ยนเป็นบรรทัดใหม่ได้ ระบบอื่นสามารถใช้งาน n ได้โดยตรง | |
' " | เครื่องหมายคำพูดเดี่ยวและคู่ สาเหตุหลักมาจากเครื่องหมายคำพูดเดี่ยวและเครื่องหมายคำพูดคู่เป็นอักขระพิเศษ หากเราต้องการใช้เครื่องหมายคำพูดเดี่ยวและเครื่องหมายคำพูดคู่ในสตริง เราจะต้องหลีกเลี่ยงเครื่องหมายเหล่านั้น | |
\ | แบ็กสแลช เนื่องจาก | |
| backspace, ฟีดเพจ, ป้ายกำกับแนวตั้ง - มันไม่ได้ถูกใช้ | f b v | |
xXX | เป็นอักขระ Unicode เลขฐานสิบหกที่เข้ารหัสเป็น XX เป็นต้น : x7A หมายถึง z (การเข้ารหัส Unicode เลขฐานสิบหกของ z คือ 7A ) | |
uXXXX | ถูกเข้ารหัสเป็นอักขระ Unicode เลขฐานสิบหกของ XXXX เช่น: u00A9 หมายถึง © | |
UTF-32 | อักขระฐานสิบ 1-6 u{X...X} | encoding เป็นสัญลักษณ์ Unicode ของ X...X |
ตัวอย่างเช่น:
console.log('I'ma Student.');// 'console.log(""I love U. "");/ / "console.log("\n เป็นอักขระขึ้นบรรทัดใหม่");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// รหัส ผลการดำเนินการ:
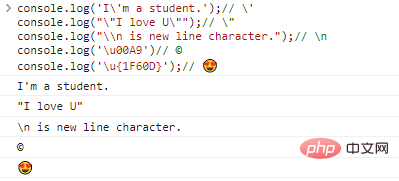
ด้วยการมีอยู่ของอักขระหลีก ในทางทฤษฎีแล้ว เราสามารถส่งออกอักขระใดๆ ก็ได้ ตราบใดที่เราพบการเข้ารหัสที่สอดคล้องกัน
หลีกเลี่ยงการใช้ ' และ "
สำหรับเครื่องหมายคำพูดเดี่ยวและคู่ในสตริง เราสามารถใช้เครื่องหมายคำพูดคู่ภายในเครื่องหมายคำพูดเดี่ยวได้อย่างชาญฉลาด ใช้เครื่องหมายคำพูดเดี่ยวภายในเครื่องหมายคำพูดคู่ หรือใช้เครื่องหมายคำพูดเดี่ยวและเครื่องหมายคู่โดยตรงภายใน backticks หลีกเลี่ยงการใช้อักขระหลีก เช่น:
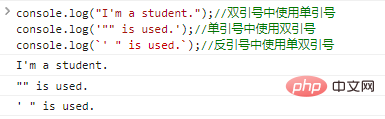
console.log("ฉันเป็นนักเรียน");
//ใช้เครื่องหมายคำพูดเดี่ยวภายในเครื่องหมายคำพูดคู่ console.log('"" is used.');
//ใช้เครื่องหมายคำพูดคู่ภายในเครื่องหมายคำพูดเดี่ยว console.log(`' " is used.`);
// ผลลัพธ์การเรียกใช้โค้ดโดยใช้เครื่องหมายคำพูดเดี่ยวและคู่ใน backticks มีดังนี้:
ด้วยคุณสมบัติ .length ของสตริง เราสามารถรับความยาวของสตริงได้:
console.log("HelloWorldn".length);//11 n ที่นี่ใช้อักขระเพียงตัวเดียวเท่านั้น
ในบท "วิธีการประเภทพื้นฐาน" เราได้สำรวจว่าทำไมประเภทพื้นฐานใน
JavaScriptจึงมีคุณสมบัติและวิธีการ คุณยังจำได้ไหม
string คือสตริงของอักขระ เราสามารถเข้าถึงอักขระตัวเดียวผ่าน [字符下标] ได้ ตัวห้อยอักขระเริ่มต้นจาก 0 :
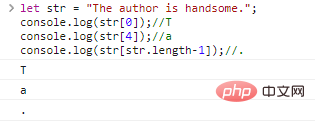
la str = "ผู้เขียนหล่อ"; console.log(str[0]);//Tconsole.log(str[4]);//aconsole.log(str[str.length-1]);//
ผลการเรียกใช้โค้ด:
เรายังสามารถใช้ฟังก์ชัน charAt(post) เพื่อรับอักขระได้:
la str = "The author is suitable";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.
เอฟเฟกต์การดำเนินการของทั้งสองจะเหมือนกันทุกประการ ข้อแตกต่างเพียงอย่างเดียวคือเมื่อเข้าถึงอักขระนอกขอบเขต:
ให้ str = "01234"; console.log(str[ 9]);//unknownconsole.log(str.charAt(9));//"" (สตริงว่าง)
เรายังสามารถใช้ for ..of เพื่อสำรวจสตริง:
for(let c of '01234'){
console.log(c);} JavaScript
JavaScript สามารถเปลี่ยนแปลงได้เมื่อถูกกำหนดแล้ว ตัวอย่างเช่น:
ให้ str = "Const";str[0] = 'c' ;console.log(str);
ผลลัพธ์:
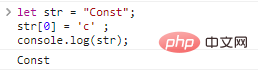
หากคุณต้องการได้สตริงอื่น คุณสามารถสร้างสตริงใหม่ได้เท่านั้น:
ให้ str = "Const";str = str.replace('C','c');console.log(str) ; ได้เปลี่ยนอักขระ String แล้ว จริงๆ แล้วสตริงเดิมไม่ได้เปลี่ยนแปลง สิ่งที่เราได้รับคือสตริงใหม่ที่ส่งคืนโดยเมธอด replace
แปลงตัวพิมพ์ของสตริง หรือแปลงตัวพิมพ์ของอักขระตัวเดียวในสตริง
เมธอดสำหรับสองสตริงนี้ค่อนข้างง่าย ดังที่แสดงในตัวอย่าง:
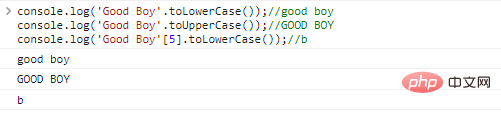
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('เด็กดี'.toUpperCase());//GOOD
BOYconsole.log('Good Boy'[5].toLowerCase());//b ผลลัพธ์การเรียกใช้โค้ด:
ฟังก์ชัน . .indexOf(substr,idx) เริ่มต้นจากตำแหน่ง idx ของสตริง ค้นหาตำแหน่งของ substr ย่อย substr และส่งกลับตัวห้อยของอักขระตัวแรกของ สตริงย่อยหากสำเร็จ หรือ -1 หากล้มเหลว
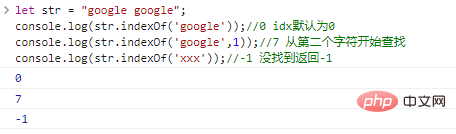
ให้ str = "google google";console.log(str.indexOf('google'));
//0 idx มีค่าเริ่มต้นเป็น 0console.log(str.indexOf('google',1));
//7 ค้นหา console.log(str.indexOf('xxx')); เริ่มต้นจากอักขระตัวที่สอง
//-1 ไม่พบส่งคืน ผลการเรียกใช้โค้ด -1:
หากเราต้องการสอบถามตำแหน่งของสตริงย่อยทั้งหมดในสตริง เราสามารถใช้การวนซ้ำได้:
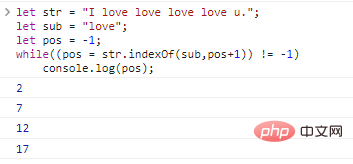
Let str = "I love love love love u.";let sub = "love";let pos = -1; While((pos = str.indexOf (ย่อย,pos+1)) != -1)
console.log(pos); ผลการรันโค้ดมีดังนี้:
.lastIndexOf(substr,idx) ค้นหาสตริงย่อยแบบย้อนกลับ ก่อนอื่นให้ค้นหาสตริงที่ตรงกันสุดท้าย:
ให้ str = "google google";console.log(str.lastIndexOf('google'));//7 idx มีค่าเริ่มต้นเป็น 0 เนื่องจากเมธอด indexOf() และ lastIndexOf() จะส่งกลับ -1 เมื่อการสืบค้นไม่สำเร็จ และ ~-1 === 0 กล่าวคือ การใช้ ~ จะเป็นจริงก็ต่อเมื่อผลลัพธ์การค้นหาไม่ใช่ -1 ดังนั้นเราสามารถ:
ให้ str = "google google";if(~indexOf('google',str)){
...} โดยปกติ เราไม่แนะนำให้ใช้ไวยากรณ์ที่ไม่สามารถสะท้อนถึงลักษณะไวยากรณ์ได้อย่างชัดเจน เนื่องจากจะส่งผลต่อความสามารถในการอ่าน โชคดีที่โค้ดด้านบนจะปรากฏเฉพาะในโค้ดเวอร์ชันเก่าเท่านั้น โดยจะมีการกล่าวถึงไว้ที่นี่ เพื่อให้ทุกคนไม่สับสนเมื่ออ่านโค้ดเก่า
ภาคผนวก:
~เป็นตัวดำเนินการปฏิเสธระดับบิต ตัวอย่างเช่น รูปแบบไบนารี่ของเลขฐานสิบ2คือ0010และรูปแบบไบนารี่ของ~2คือ1101(ส่วนเสริม) ซึ่งก็คือ-3วิธีทำความเข้าใจง่ายๆ
~nเทียบเท่ากับ-(n+1)ตัวอย่างเช่น:~2 === -(2+1) === -3
idx
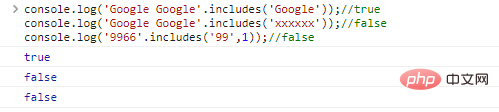
.includes(substr,idx) ใช้เพื่อกำหนดว่า substr อยู่ในสตริงหรือ idx
'Google Google'. include('xxxxxx'));//falseconsole.log('9966'.includes('99',1));// ผลการเรียกใช้โค้ดเท็จ:
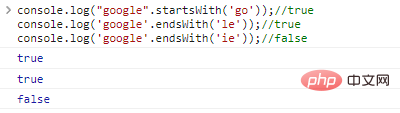
.startsWith('substr') และ .endsWith('substr') กำหนดตามลำดับว่าสตริงเริ่มต้นหรือลงท้ายด้วย substr
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));// ผลการรันโค้ดเท็จ:
.substr() , .substring() , .slice() ล้วนใช้เพื่อรับสตริงย่อยของสตริง แต่การใช้งานต่างกัน
.substr(start,len)
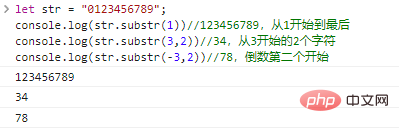
ส่งคืนสตริงที่ประกอบด้วยอักขระ len ที่เริ่มต้นจาก start หากละเว้น len จะถูกดักจับที่จุดสิ้นสุดของสตริงดั้งเดิม start อาจเป็นตัวเลขลบ โดยระบุอักขระ start จากด้านหลังไปด้านหน้า
ให้ str = "0123456789";console.log(str.substr(1))//123456789 โดยเริ่มจาก 1 ถึง end console.log(str.substr(3,2))//34, 2 โดยเริ่มจาก 3 ตัวอักษร console.log(str.substr(-3,2))//78
ผลลัพธ์การเรียกใช้โค้ดเริ่มต้นสุดท้าย:
.slice(start,end)
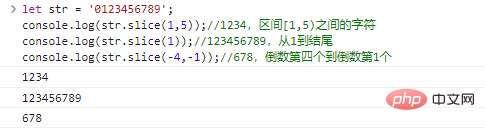
ส่งคืนสตริงที่เริ่มต้นจาก start และสิ้นสุดที่ end (ไม่รวม) start และ end อาจเป็นตัวเลขติดลบ ซึ่งระบุอักขระ start/end สุดท้าย
la str = '0123456789';console.log(str.slice(1,5));//1234, อักขระระหว่างช่วงเวลา [1,5) console.log(str.slice(1));//123456789 , จาก 1 ถึง end console.log(str.slice(-4,-1));//678
ผลลัพธ์การเรียกใช้โค้ดที่สี่ถึงสุดท้าย:
.substring(start,end)
เกือบ
จะเหมือนกับ .slice() ความแตกต่างอยู่ในสองตำแหน่ง:
0end > start ;ให้ str = '0123456789'; console.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1, 3));//012, -1 ถือเป็น
ผลการเรียกใช้โค้ด Make 0:
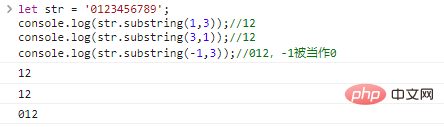
เปรียบเทียบความแตกต่างระหว่างสาม:
| พารามิเตอร์ | คำอธิบาย | เมธอด | .slice
|---|---|---|
.slice(start,end) | [start,end) | สามารถเป็นลบได้ substring |
.substring(start,end) | [start,end) | ค่าลบ 0 |
.substr(start,len) | เริ่มต้นจาก start len | มี |
วิธีการย่อยเชิงลบมากมายสำหรับ len ดังนั้นจึงเป็นเรื่องยากที่จะเลือกโดยธรรมชาติ .
.slice()ซึ่งมีความยืดหยุ่นมากกว่าอีกสองวิธี
เราได้กล่าวถึงการเปรียบเทียบสตริงในบทความที่แล้วแล้ว สตริงจะเรียงลำดับตามพจนานุกรม ด้านหลังอักขระแต่ละตัวจะมีโค้ด และโค้ด ASCII เป็นข้อมูลอ้างอิงที่สำคัญ
ตัวอย่างเช่น:
console.log('a'>'Z');// การเปรียบเทียบระหว่างอักขระจริงถือเป็นการเปรียบเทียบระหว่างการเข้ารหัสที่แสดงถึงอักขระ JavaScript ใช้ UTF-16 ในการเข้ารหัสสตริง อักขระแต่ละตัวเป็นโค้ด 16 บิต หากคุณต้องการทราบลักษณะของการเปรียบเทียบ คุณต้องใช้ .codePointAt(idx) เพื่อรับการเข้ารหัสอักขระ:
console.log('a '.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90 ผลลัพธ์การเรียกใช้โค้ด:
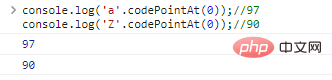
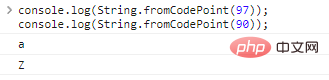
ใช้ String.fromCodePoint(code) เพื่อแปลงการเข้ารหัสเป็นอักขระ:
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90));
ผลลัพธ์การเรียกใช้โค้ดมีดังนี้:
กระบวนการนี้สามารถทำได้โดยใช้อักขระหลีก u ดังนี้:
console.log('u005a');//Z, 005a เป็นสัญกรณ์เลขฐานสิบหกของ 90 console.log('u0061');//a, 0061 เป็นเลขฐานสิบหกของ 97 มาสำรวจอักขระที่เข้ารหัสในช่วง [65,220] กันดีกว่า :
la str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); ผลลัพธ์ของส่วนการเรียกใช้โค้ดมีดังนี้:

ภาพด้านบนไม่ได้แสดงผลทั้งหมด ดังนั้น ไปลองดูครับ
เป็นไปตามมาตรฐานสากล ECMA-402 JavaScript ได้ใช้เมธอดพิเศษ ( .localeCompare() ) เพื่อเปรียบเทียบสตริงต่างๆ โดยใช้ str1.localeCompare(str2) :
str1 < str2 คืนค่าจำนวนลบstr1 > str2 ส่งคืนจำนวนบวกstr1 == str2 ส่งคืน 0;เช่น:
console.log("abc".localeCompare('def'));//-1 ทำไมไม่ใช้ตัวดำเนินการเปรียบเทียบโดยตรง
เนื่องจากอักขระภาษาอังกฤษมีวิธีการเขียนพิเศษบางอย่าง ตัวอย่างเช่น á เป็นรูปแบบหนึ่งของ a :
console.log('á' < 'z');// แม้ว่า false จะเป็น a เช่นกัน แต่ก็มีขนาดใหญ่กว่า z ! -
ในขณะนี้ คุณต้องใช้เมธอด .localeCompare() :
console.log('á'.localeCompare('z'));//-1 str.trim() จะลบอักขระช่องว่างก่อนและหลัง string, str.trimStart() , str.trimEnd() ลบช่องว่างที่จุดเริ่มต้นและจุดสิ้นสุด
ให้ str = " 999 "; console.log(str.trim()); //999
str.repeat(n) ซ้ำ สตริง n ครั้ง;
ให้ str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr) แทนที่สตริงย่อยแรก str.replaceAll() ใช้เพื่อแทนที่ทั้งหมด สตริงย่อย;
ให้ str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6ยังคงอยู่ มีวิธีการอื่นๆ อีกมากมาย ซึ่งเราสามารถเข้าไปดูคู่มือเพื่อดูข้อมูลเพิ่มเติมได้
JavaScript ใช้ UTF-16 ในการเข้ารหัสสตริง นั่นคือ 2 ไบต์ ( 16 บิต) ถูกใช้เพื่อแสดงอักขระหนึ่งตัว อย่างไรก็ตาม ข้อมูล 16 บิตสามารถแสดงได้เพียง 65536 อักขระเท่านั้น โดยทั่วไปจะไม่รวมอักขระทั่วไปไว้ด้วย เป็นเรื่องง่ายที่จะเข้าใจ แต่ไม่เพียงพอสำหรับอักขระที่หายาก (ภาษาจีน) emoji สัญลักษณ์ทางคณิตศาสตร์ที่หายาก ฯลฯ
ในกรณีนี้ คุณต้องขยายและใช้ตัวเลขที่ยาวขึ้น ( 32 บิต) เพื่อแสดงอักขระพิเศษ เช่น:
console.log(''.length);//2console.log('?'.length);//2 ผลการดำเนินการรหัส:
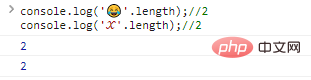
ผลลัพธ์ก็คือเราไม่สามารถประมวลผลพวกมันโดยใช้วิธีการทั่วไปได้ จะเกิดอะไรขึ้นถ้าเราส่งออกแต่ละไบต์แยกกัน
console.log(''[0]);console.log(''[1]); ผลการเรียกใช้โค้ด:
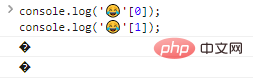
อย่างที่คุณเห็น ไบต์เอาท์พุตแต่ละรายการจะไม่ได้รับการยอมรับ
โชคดีที่เมธอด String.fromCodePoint() และ .codePointAt() สามารถจัดการกับสถานการณ์นี้ได้เนื่องจากมีการเพิ่มเข้ามาเมื่อเร็วๆ นี้ ใน JavaScript เวอร์ชันเก่า คุณสามารถใช้เมธอด String.fromCharCode() และ .charCodeAt() เพื่อแปลงการเข้ารหัสและอักขระได้เท่านั้น แต่ไม่เหมาะสำหรับอักขระพิเศษ
เราสามารถจัดการกับอักขระพิเศษได้โดยการตัดสินช่วงการเข้ารหัสของอักขระเพื่อพิจารณาว่าเป็นอักขระพิเศษหรือไม่ หากโค้ดของอักขระอยู่ระหว่าง 0xd800~0xdbff แสดงว่าเป็นส่วนแรกของอักขระ 32 บิต และส่วนที่สองควรอยู่ระหว่าง 0xdc00~0xdfff
ตัวอย่างเช่น:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));// ผลการเรียกใช้โค้ด de02:

ในภาษาอังกฤษ มีหลายรูปแบบที่ใช้ตัวอักษร เช่น ตัวอักษร a อาจเป็นอักขระพื้นฐานของ àáâäãåā สัญลักษณ์รูปแบบต่างๆ เหล่านี้ไม่ได้จัดเก็บไว้ในการเข้ารหัส UTF-16 เนื่องจากมีรูปแบบผสมกันมากเกินไป
เพื่อรองรับการผสมผสานรูปแบบทั้งหมด อักขระ Unicode หลายตัวยังถูกใช้เพื่อแสดงอักขระรูปแบบเดียวในระหว่างขั้นตอนการเขียนโปรแกรม เราสามารถใช้อักขระพื้นฐานบวกกับ "สัญลักษณ์ตกแต่ง" เพื่อแสดงอักขระพิเศษ:
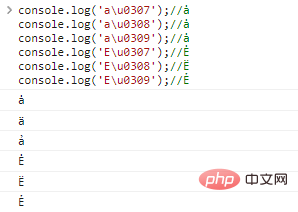
console.log('au0307 ' );//ช
console.log('au0308');//ŧ
console.log('au0309');//ŧ
console.log('Eu0307');//Ė
console.log('Eu0308');//E
console.log('Eu0309');//Ẻ ผลการดำเนินการโค้ด:
ตัวอักษรพื้นฐานสามารถมีการตกแต่งได้หลายแบบ เช่น:
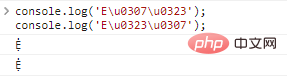
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');//Ẹ̇ ผลการเรียกใช้โค้ด:
มีปัญหาตรงนี้ ในกรณีที่มีการตกแต่งหลายแบบ การตกแต่งจะเรียงลำดับต่างกัน แต่จริงๆ แล้วตัวละครที่แสดงจะเหมือนกัน
หากเราเปรียบเทียบการแทนค่าทั้งสองนี้โดยตรง เราจะได้ผลลัพธ์ที่ผิด:
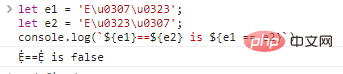
ให้ e1 = 'Eu0307u0323';
ให้ e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} is ${e1 == e2}`) ผลลัพธ์การเรียกใช้โค้ด:
เพื่อที่จะแก้ไขสถานการณ์นี้ มี ** อัลกอริธึมการทำให้เป็นมาตรฐาน Unicode ที่สามารถแปลงสตริงเป็น รูปแบบสากล ** ใช้งานโดย str.normalize() :
la e1 = 'Eu0307u0323';
ให้ e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} คือ ${e1.normalize() == e2.normalize()}`)
ผลการรันโค้ด:

[คำแนะนำที่เกี่ยวข้อง: วิดีโอสอน JavaScript, ส่วนหน้าของเว็บ]
ด้านบนคือเนื้อหาโดยละเอียดของวิธีการพื้นฐานทั่วไปของสตริง JavaScript สำหรับข้อมูลเพิ่มเติม โปรดใส่ใจกับบทความอื่น ๆ ที่เกี่ยวข้องบนเว็บไซต์ภาษาจีน PHP!