เรารวบรวมข้อมูลของหน้าเว็บทั้งหมดในส่วนที่แล้ว ตอนนี้ เราต้องค้นหาเนื้อหาที่ต้องการในโค้ด html ดังนั้นเราจึงต้องเข้าสู่เว็บไซต์ตามปัญหาและแยกวิเคราะห์ข้อมูลในหน้าเว็บ
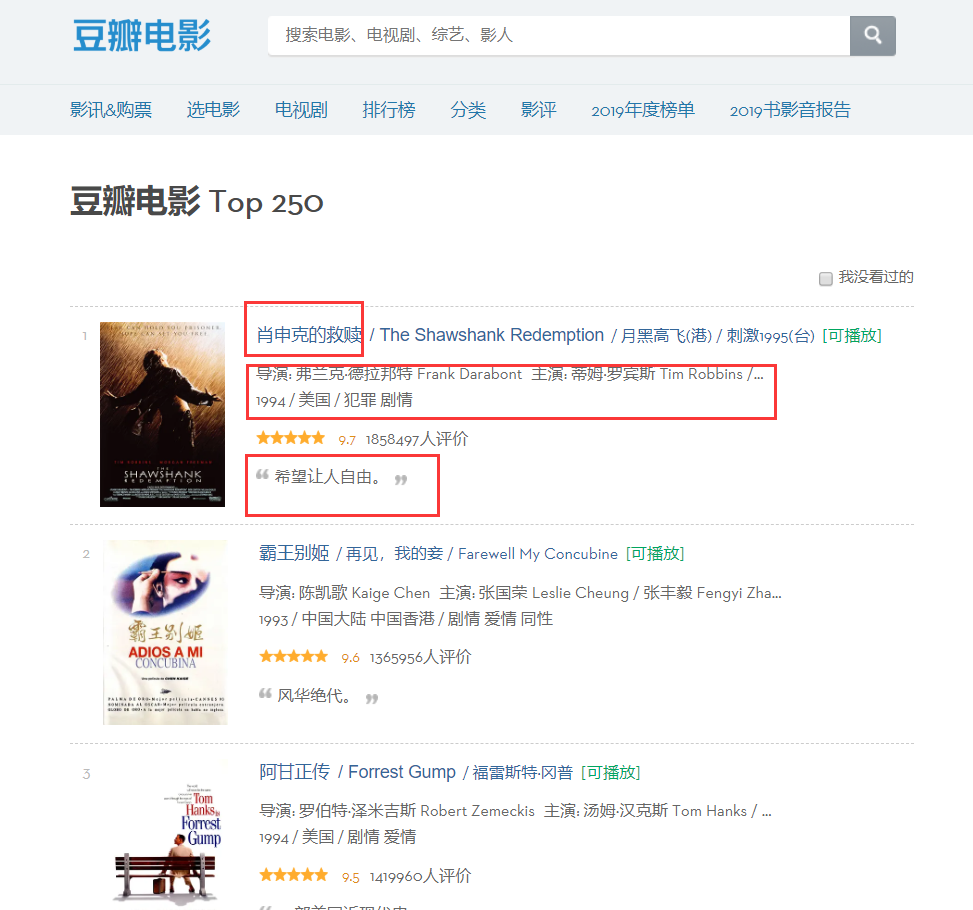
จะพบได้จากหน้าเว็บว่าข้อมูลที่เราต้องรวบรวมข้อมูลมีอยู่ในพาร์ติชั่นต่างๆ ดังนั้น เรามาตรวจสอบองค์ประกอบของหน้ากันดีกว่า คลิกขวาที่หน้า เพื่อตรวจสอบซอร์สโค้ดของหน้าเว็บหรือ F12

ก่อนที่จะวิเคราะห์หน้าเว็บ ก่อนอื่นเราจะระบุวิธีการจัดเก็บหลังจากแยกวิเคราะห์ ที่นี่เราใช้รายการเพื่อจัดเก็บข้อมูลทั้งหมด จากนั้นแต่ละรายการในรายการจะสอดคล้องกับพจนานุกรม และแต่ละพจนานุกรมจะสอดคล้องกับข้อมูลหลายประเภท
movies=[]#ขั้นแรกให้กำหนดรายการเพื่อเก็บข้อมูลทั้งหมด
จากการวิเคราะห์ เราสามารถระบุได้ว่าตำแหน่งของชื่อเรื่องคือ 'span' ตัวแรกใน 'a' ตัวแรกใต้ 'div' ชื่อ 'hd' เพื่อให้เราสามารถล็อกชื่อของภาพยนตร์แต่ละเรื่องด้วยโค้ดต่อไปนี้ จากนั้น ลงในพจนานุกรม
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#รายการในพจนานุกรมในทำนองเดียวกัน ซอร์สโค้ดของชื่อผู้กำกับสามารถพบได้ตามตำแหน่ง แต่ซอร์สโค้ดนี้มีข้อมูลจำนวนมาก ดังนั้นเราจึงจำเป็นต้องกรองโดยใช้นิพจน์ทั่วไป
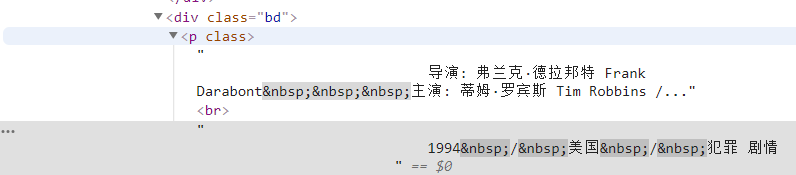
ข้อมูล=each.find('div',class_='bd').p.text.strip()ขั้นแรก เราจะค้นหาเนื้อหาทั้งหมดภายใต้แท็กนี้ จากนั้นจึงกรองข้อมูลที่ไม่เกี่ยวข้องออกโดยใช้นิพจน์ทั่วไป
info=info.replace('n',)#Filter Carriage ส่งคืน info=info.replace(,)#Filter spaces info=info.replace(xa0,)#Filter non-breaking whitespace character Director=re.findall( r '[ผู้กำกับ:].+[นำแสดงโดย:]',ข้อมูล)[0]ผู้กำกับ=ผู้กำกับ[3:len(ผู้กำกับ)-6]แล้วกำหนดให้เป็นรายการในพจนานุกรม
movie['director']=director#รายการในพจนานุกรม
เราพบว่าประเภทภาพยนตร์อยู่ในแท็ก 'p' นี้ด้วย และเรายังได้รับข้อมูลนี้โดยตรงผ่านนิพจน์ทั่วไป
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#Add เป็นรายการในพจนานุกรมสุดท้าย ล็อคข้อมูลการให้คะแนน
star=each.find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()จากนั้นจึงบันทึกต่อไปในรูปแบบพจนานุกรม
ภาพยนตร์['ดาว']=ดาว
ท้ายที่สุดให้เพิ่มพจนานุกรมนี้ลงในรายการและวนซ้ำผลลัพธ์
movies.append(movie)#Add the Dictionary to the list foriinmovies:#Traverse the output print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#Simulate browser to access'user-agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537. 36','Host':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 ครั้ง r=requests.get(res ,headers=headers,timeout=10)#Set the timeout Soup=BeautifulSoup(r.text,html.parser)#Set the parsing method วิธีอื่นก็สามารถใช้ได้ div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()ภาพยนตร์['title']=movienamerank=each.find('div',class_='pic').em.text .strip()movie['rank']=rankinfo=each.find('div',class_='bd').p.text.strip()info=info.replace('n',)info=info .replace(,)info=info.replace(xa0,)director=re.findall(r'[ผู้กำกับ:].+[นำแสดงโดย:]',info)[0]ผู้กำกับ=ผู้กำกับ [3:len(director)-6]movie['director']=directorrelease_date=re.findall(r'[0-9]{4}',info)[0]movie['release_date']=release_dateplot=re .findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index(' /')+1:]plot=plot[plot.index('/')+1:]ภาพยนตร์['plot']=plotstar=each.find('div',class_='star')star=star find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print(i)คอนโซล:

ในตัวอย่างนี้ เราเรียนรู้วิธีค้นหาข้อมูลที่เกี่ยวข้องในซอร์สโค้ดของหน้าเว็บเป็นหลัก BeautifulSoup สามารถช่วยให้เราค้นหาได้อย่างรวดเร็ว จากนั้นจึงรวมเข้ากับนิพจน์ทั่วไปเพื่อจับคู่ข้อมูลให้สมบูรณ์ ในส่วนถัดไป จะบันทึกข้อมูลนี้ลงฐานข้อมูล