ความเข้าใจวิดีโอที่มีความยาวเป็นพิเศษเป็นปัญหาที่ยากมาโดยตลอดสำหรับโมเดลภาษาขนาดใหญ่หลายรูปแบบ (MLLM) โมเดลที่มีอยู่นั้นยากต่อการประมวลผลข้อมูลวิดีโอที่เกินความยาวบริบทสูงสุด และการลดทอนข้อมูลและต้นทุนการคำนวณที่สูงก็เป็นความท้าทายที่สำคัญเช่นกัน บรรณาธิการของ Downcodes ได้เรียนรู้ว่าสถาบันวิจัย Zhiyuan และมหาวิทยาลัยหลายแห่งได้เสนอโมเดลภาษาภาพที่มีความยาวเป็นพิเศษที่เรียกว่า Video-XL ซึ่งออกแบบมาเพื่อจัดการกับปัญหาการทำความเข้าใจวิดีโอในระดับชั่วโมงอย่างมีประสิทธิภาพ เทคโนโลยีหลักของโมเดลนี้คือ "การสรุปบริบทแฝงของภาพ" ซึ่งใช้ความสามารถในการสร้างโมเดลบริบทของ LLM อย่างชาญฉลาด เพื่อบีบอัดการนำเสนอด้วยภาพขนาดยาวให้อยู่ในรูปแบบที่กะทัดรัดมากขึ้น คล้ายกับการควบแน่นวัวทั้งตัวลงในชามที่ใส่เนื้อวัว ทำให้เกิดแบบจำลอง ดูดซับข้อมูลสำคัญได้อย่างมีประสิทธิภาพมากขึ้น
ปัจจุบัน โมเดลภาษาขนาดใหญ่หลายรูปแบบ (MLLM) มีความก้าวหน้าอย่างมากในด้านความเข้าใจเกี่ยวกับวิดีโอ แต่การประมวลผลวิดีโอที่ยาวมากยังคงเป็นความท้าทาย เนื่องจากโดยทั่วไปแล้ว MLLM จะต้องดิ้นรนในการจัดการกับโทเค็นภาพนับพันที่เกินความยาวบริบทสูงสุดและทนทุกข์ทรมานจากการสลายตัวของข้อมูลที่เกิดจากการรวมโทเค็น ในขณะเดียวกัน แท็กวิดีโอจำนวนมากก็จะทำให้ต้นทุนการคำนวณสูงเช่นกัน
เพื่อแก้ไขปัญหาเหล่านี้ Zhiyuan Research Institute ร่วมมือกับ Shanghai Jiao Tong University, Renmin University of China, Peking University, Beijing University of Post and Telecommunications และมหาวิทยาลัยอื่นๆ เพื่อเสนอ Video-XL ซึ่งเป็นระบบความละเอียดสูงพิเศษที่ออกแบบมาสำหรับ ความเข้าใจวิดีโอระดับชั่วโมงที่มีประสิทธิภาพ แกนหลักของ Video-XL อยู่ที่เทคโนโลยี "การสรุปบริบทแฝงด้วยภาพ" ซึ่งใช้ประโยชน์จากความสามารถในการสร้างแบบจำลองบริบทโดยธรรมชาติของ LLM เพื่อบีบอัดการแสดงภาพขนาดยาวให้อยู่ในรูปแบบที่กะทัดรัดยิ่งขึ้นได้อย่างมีประสิทธิภาพ
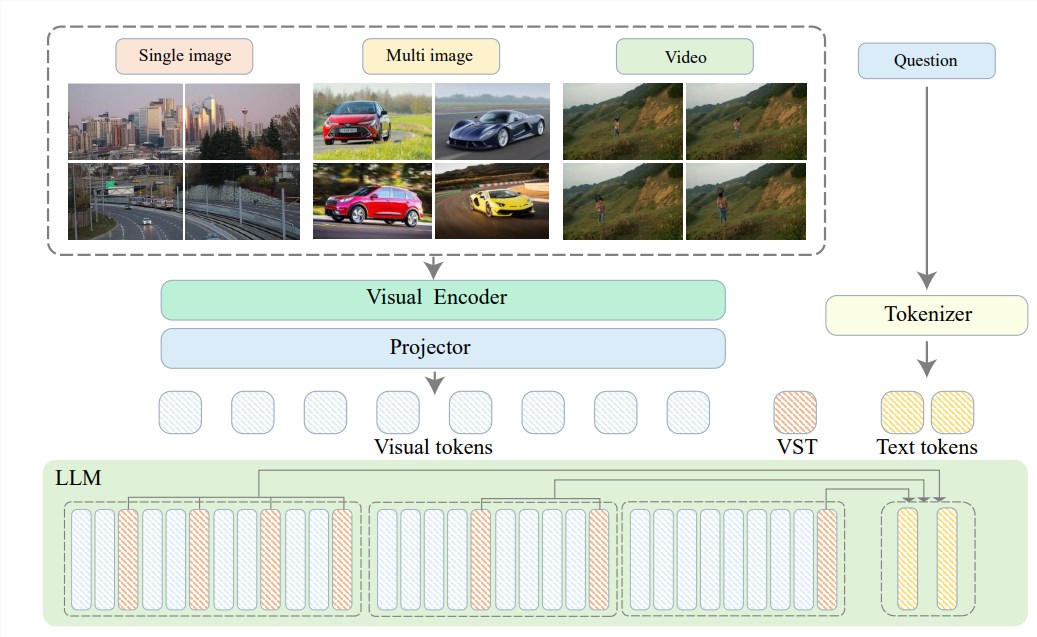
พูดง่ายๆ ก็คือการบีบอัดเนื้อหาวิดีโอให้อยู่ในรูปแบบที่มีความคล่องตัวมากขึ้น เช่นเดียวกับการอัดวัวทั้งตัวลงในชามใส่เนื้อวัว ซึ่งโมเดลจะย่อยและดูดซับได้ง่ายกว่า
เทคโนโลยีการบีบอัดนี้ไม่เพียงแต่ปรับปรุงประสิทธิภาพเท่านั้น แต่ยังรักษาข้อมูลสำคัญของวิดีโอได้อย่างมีประสิทธิภาพอีกด้วย คุณรู้ไหมว่าวิดีโอขนาดยาวมักเต็มไปด้วยข้อมูลที่ซ้ำซ้อนมากมาย เช่น ผ้าเช็ดเท้าของหญิงชรา ซึ่งยาวและมีกลิ่นเหม็น Video-XL สามารถกำจัดข้อมูลที่ไร้ประโยชน์นี้ได้อย่างแม่นยำและเก็บเฉพาะส่วนที่จำเป็น ซึ่งช่วยให้มั่นใจว่าโมเดลจะไม่หลงทางเมื่อทำความเข้าใจเนื้อหาวิดีโอขนาดยาว
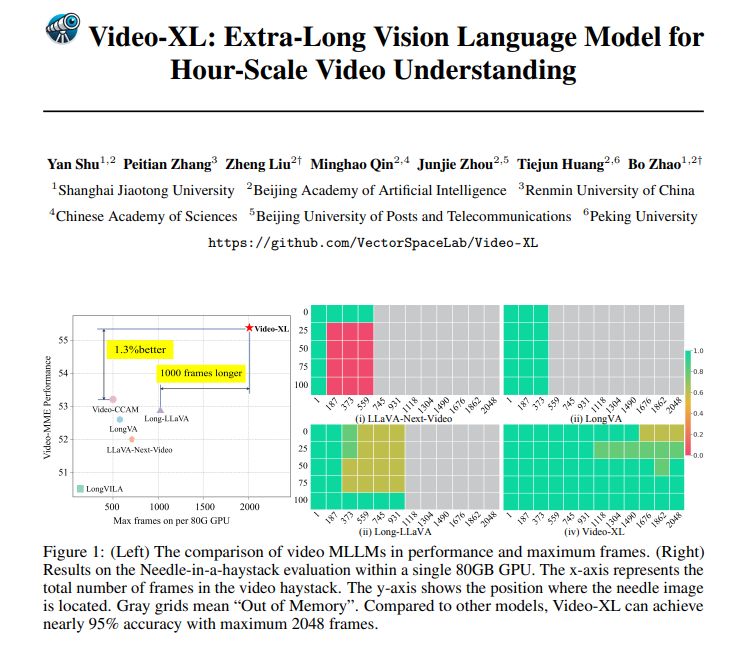
Video-XL ไม่เพียงแต่ยอดเยี่ยมในทางทฤษฎีเท่านั้น แต่ยังมีความสามารถในทางปฏิบัติอีกด้วย Video-XL ได้รับผลลัพธ์ชั้นนำในการวัดประสิทธิภาพความเข้าใจวิดีโอขนาดยาวหลายรายการ โดยเฉพาะอย่างยิ่งในการทดสอบ VNBench ซึ่งมีความแม่นยำสูงกว่าวิธีการที่ดีที่สุดที่มีอยู่เกือบ 10%
ที่น่าประทับใจยิ่งกว่านั้นคือ Video-XL มีความสมดุลที่น่าทึ่งระหว่างประสิทธิภาพและประสิทธิผล โดยสามารถประมวลผลวิดีโอได้ 2,048 เฟรมบน GPU ขนาด 80GB ตัวเดียว ในขณะที่ยังคงรักษาความแม่นยำเกือบ 95% ในอัตราการประเมิน "เข็มในกองหญ้า"
Video-XL ยังมีโอกาสในการนำไปใช้งานในวงกว้างอีกด้วย นอกจากจะสามารถเข้าใจวิดีโอขนาดยาวทั่วไปได้แล้ว ยังสามารถทำงานเฉพาะด้านได้ เช่น การสรุปภาพยนตร์ การตรวจจับความผิดปกติของการเฝ้าระวัง และการจดจำตำแหน่งโฆษณา
ซึ่งหมายความว่าคุณไม่จำเป็นต้องอดทนกับเนื้อเรื่องที่ยืดยาวอีกต่อไปเมื่อรับชมภาพยนตร์ในอนาคต คุณสามารถใช้ Video-XL ได้โดยตรงเพื่อสร้างการสรุปที่คล่องตัว ประหยัดเวลาและความพยายาม หรือคุณสามารถใช้เพื่อตรวจสอบภาพจากกล้องวงจรปิดและระบุเหตุการณ์ที่ผิดปกติได้โดยอัตโนมัติ ซึ่งมีประสิทธิภาพมากกว่าการติดตามด้วยตนเอง
ที่อยู่โครงการ: https://github.com/VectorSpaceLab/Video-XL
บทความ: https://arxiv.org/pdf/2409.14485
Video-XL มีความก้าวหน้าอย่างมากในด้านความเข้าใจเกี่ยวกับวิดีโอขนาดยาวเป็นพิเศษ การผสมผสานที่ลงตัวระหว่างประสิทธิภาพและความแม่นยำถือเป็นโซลูชันใหม่สำหรับการประมวลผลวิดีโอขนาดยาว ซึ่งมีแนวโน้มการใช้งานที่กว้างขวางในอนาคต และคุ้มค่ากับการรอคอย!