การฝึกอบรมโมเดลขนาดใหญ่ใช้เวลานานและต้องใช้แรงงานมาก การปรับปรุงประสิทธิภาพและลดการใช้พลังงานกลายเป็นประเด็นสำคัญในสาขา AI ได้อย่างไร AdamW ซึ่งเป็นเครื่องมือเพิ่มประสิทธิภาพเริ่มต้นสำหรับการฝึกอบรมล่วงหน้าของ Transformer ค่อยๆ ไม่สามารถรับมือกับโมเดลที่มีขนาดใหญ่ขึ้นเรื่อยๆ ได้ บรรณาธิการของ Downcodes จะพาคุณไปเรียนรู้เกี่ยวกับเครื่องมือเพิ่มประสิทธิภาพใหม่ที่พัฒนาโดยทีมงานชาวจีน - C-AdamW ด้วยกลยุทธ์ที่ "ระมัดระวัง" จะช่วยลดการใช้พลังงานได้อย่างมาก ในขณะเดียวกันก็รับประกันความเร็วและความเสถียรในการฝึกอบรม และนำประโยชน์ที่ยอดเยี่ยมมาสู่การฝึกอบรมโมเดลขนาดใหญ่ . เพื่อปฏิวัติการเปลี่ยนแปลง
ในโลกของ AI การทำงานอย่างหนักเพื่อให้บรรลุปาฏิหาริย์ดูเหมือนจะเป็นกฎทอง ยิ่งโมเดลมีขนาดใหญ่ ข้อมูลก็ยิ่งมากขึ้น และพลังการประมวลผลที่แข็งแกร่งยิ่งขึ้น ดูเหมือนว่าจะเข้าใกล้จอกศักดิ์สิทธิ์แห่งสติปัญญามากขึ้นเท่านั้น อย่างไรก็ตาม เบื้องหลังการพัฒนาอย่างรวดเร็วนี้ ยังมีแรงกดดันอย่างมากต่อต้นทุนและการใช้พลังงาน
เพื่อให้การฝึกอบรม AI มีประสิทธิภาพมากขึ้น นักวิทยาศาสตร์กำลังมองหาเครื่องมือเพิ่มประสิทธิภาพที่มีประสิทธิภาพมากขึ้น เช่น โค้ช เพื่อเป็นแนวทางในพารามิเตอร์ของแบบจำลองเพื่อเพิ่มประสิทธิภาพอย่างต่อเนื่องและไปถึงสถานะที่ดีที่สุดในที่สุด AdamW ซึ่งเป็นเครื่องมือเพิ่มประสิทธิภาพเริ่มต้นสำหรับการฝึกอบรมล่วงหน้าของ Transformer ถือเป็นมาตรฐานอุตสาหกรรมมาหลายปีแล้ว อย่างไรก็ตาม เมื่อเผชิญกับขนาดของโมเดลที่ใหญ่ขึ้นเรื่อยๆ AdamW ก็เริ่มดูเหมือนจะไม่สามารถรับมือกับความสามารถของมันได้
ไม่มีวิธีใดที่จะเพิ่มความเร็วในการฝึกฝนในขณะที่ลดการใช้พลังงานลงได้ใช่ไหม ไม่ต้องกังวล ทีมชาวจีนล้วนอยู่ที่นี่พร้อมกับอาวุธลับของพวกเขา C-AdamW!
ชื่อเต็มของ C-AdamW คือ Cautious AdamW และชื่อภาษาจีนคือ Cautious AdamW ฟังดูไม่ค่อยพุทธใช่ไหม ใช่ แนวคิดหลักของ C-AdamW คือการคิดให้รอบคอบก่อนแสดง

ลองนึกภาพว่าพารามิเตอร์ของโมเดลเป็นเหมือนกลุ่มเด็กที่กระตือรือร้นซึ่งมักจะอยากวิ่งเล่น AdamW เปรียบเสมือนครูผู้ทุ่มเท ที่พยายามชี้แนะพวกเขาไปในทิศทางที่ถูกต้อง แต่บางครั้งเด็กๆ ก็ตื่นเต้นเกินไปและวิ่งไปผิดทาง ทำให้เสียเวลาและพลังงานไปโดยเปล่าประโยชน์
ในเวลานี้ C-AdamW เปรียบเสมือนผู้เฒ่าผู้ชาญฉลาดที่มีดวงตาแหลมคม สามารถระบุได้อย่างแม่นยำว่าทิศทางการอัปเดตนั้นถูกต้องหรือไม่ หากทิศทางไม่ถูกต้อง C-AdamW จะทำการหยุดรถอย่างเด็ดขาดเพื่อป้องกันไม่ให้โมเดลเดินไปผิดทาง
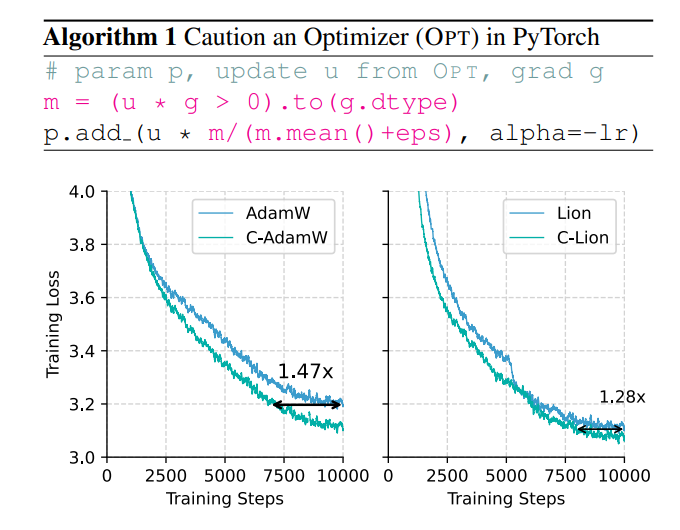
กลยุทธ์ที่ระมัดระวังนี้ช่วยให้มั่นใจได้ว่าการอัปเดตแต่ละครั้งสามารถลดฟังก์ชันการสูญเสียได้อย่างมีประสิทธิภาพ ซึ่งจะช่วยเร่งการบรรจบกันของโมเดล ผลการทดลองแสดงให้เห็นว่า C-AdamW เพิ่มความเร็วการฝึกเป็น 1.47 เท่าในการฝึกล่วงหน้า Llama และ MAE!
ที่สำคัญกว่านั้น C-AdamW แทบไม่ต้องเสียค่าใช้จ่ายในการคำนวณเพิ่มเติม และสามารถนำไปใช้ได้ด้วยการแก้ไขโค้ดที่มีอยู่เพียงบรรทัดเดียว ซึ่งหมายความว่านักพัฒนาสามารถใช้ C-AdamW กับการฝึกโมเดลต่างๆ ได้อย่างง่ายดาย และเพลิดเพลินไปกับความเร็วและความหลงใหล!
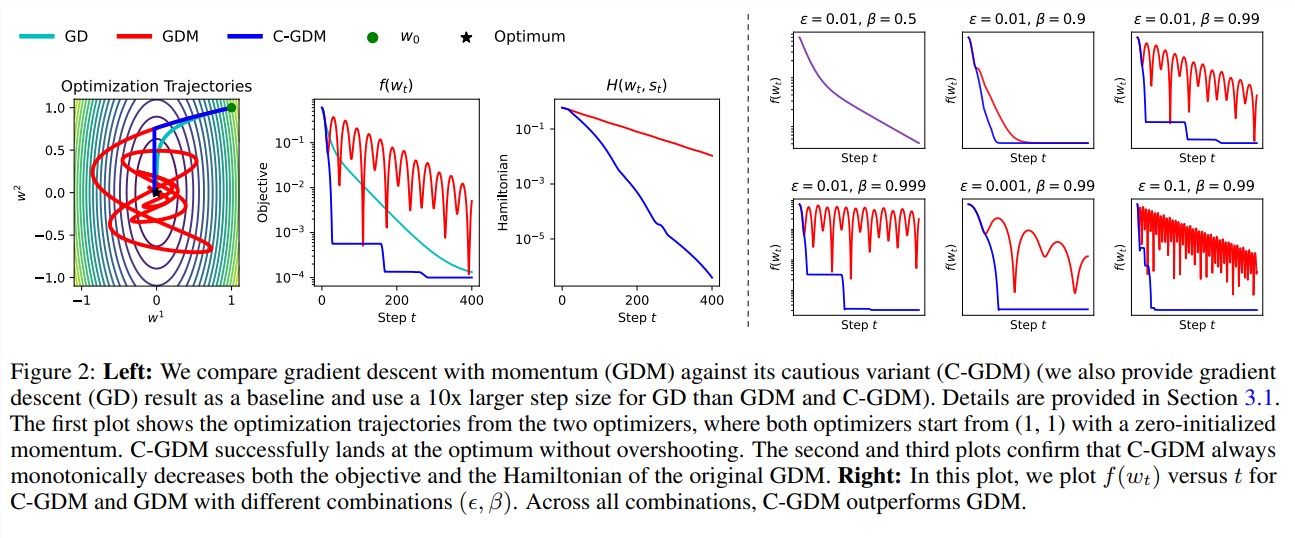
สิ่งที่ยอดเยี่ยมเกี่ยวกับ C-AdamW คือมันยังคงรักษาฟังก์ชัน Hamiltonian ของ Adam ไว้ และไม่ทำลายการรับประกันการลู่เข้าภายใต้การวิเคราะห์ของ Lyapunov ซึ่งหมายความว่า C-AdamW ไม่เพียงแต่เร็วขึ้นเท่านั้น แต่ยังรับประกันความเสถียรด้วย และจะไม่มีปัญหาเช่นการขัดข้องในการฝึก
แน่นอนว่าการเป็นชาวพุทธไม่ได้หมายความว่าคุณจะไม่กล้าได้กล้าเสีย ทีมวิจัยระบุว่าพวกเขาจะสำรวจฟังก์ชัน ϕ ที่สมบูรณ์ยิ่งขึ้นต่อไป และใช้มาสก์ในพื้นที่คุณลักษณะ แทนที่จะใช้พื้นที่พารามิเตอร์ เพื่อปรับปรุงประสิทธิภาพของ C-AdamW ต่อไป
คาดการณ์ได้ว่า C-AdamW จะกลายเป็นรายการโปรดใหม่ในด้านการเรียนรู้เชิงลึก โดยนำการเปลี่ยนแปลงที่ปฏิวัติวงการมาสู่การฝึกโมเดลขนาดใหญ่!
ที่อยู่กระดาษ: https://arxiv.org/abs/2411.16085
GitHub:
https://github.com/kyleliang919/C-Optim
การเกิดขึ้นของ C-AdamW ให้แนวคิดใหม่ในการแก้ปัญหาประสิทธิภาพการฝึกโมเดลขนาดใหญ่และการใช้พลังงาน ประสิทธิภาพสูง ความเสถียร และคุณลักษณะที่ใช้งานง่ายทำให้มีแนวโน้มสูงสำหรับการใช้งาน คาดว่า C-AdamW จะสามารถนำไปใช้ในสาขาอื่นๆ ได้มากขึ้นในอนาคต และส่งเสริมการพัฒนาเทคโนโลยี AI อย่างต่อเนื่อง บรรณาธิการของ Downcodes จะยังคงให้ความสนใจกับความก้าวหน้าทางเทคโนโลยีที่เกี่ยวข้องต่อไป ดังนั้นโปรดคอยติดตาม!