บรรณาธิการของ Downcodes ทราบว่ามหาวิทยาลัยปักกิ่งและทีมวิจัยทางวิทยาศาสตร์อื่นๆ ได้เปิดตัว LLaVA-o1 ซึ่งเป็นโมเดลโอเพ่นซอร์สหลายรูปแบบที่สำคัญ โมเดลดังกล่าวเหนือกว่าคู่แข่ง เช่น Gemini, GPT-4o-mini และ Llama ในการทดสอบเกณฑ์มาตรฐานหลายรายการ และกลไกการให้เหตุผล "การคิดช้า" ทำให้สามารถให้เหตุผลที่ซับซ้อนมากขึ้น ซึ่งเทียบได้กับ GPT-o1 โอเพ่นซอร์สของ LLaVA-o1 จะนำพลังใหม่มาสู่การวิจัยและการประยุกต์ใช้ในด้าน AI หลายรูปแบบ
เมื่อเร็วๆ นี้ มหาวิทยาลัยปักกิ่งและทีมวิจัยทางวิทยาศาสตร์อื่นๆ ได้ประกาศเปิดตัวโมเดลโอเพ่นซอร์สหลายรูปแบบที่เรียกว่า LLaVA-o1 ซึ่งกล่าวกันว่าเป็นโมเดลภาษาภาพตัวแรกที่สามารถให้เหตุผลอย่างเป็นระบบและเป็นธรรมชาติ ซึ่งเทียบได้กับ GPT-o1
โมเดลนี้ทำงานได้ดีบนเกณฑ์มาตรฐานหลายรูปแบบที่ท้าทายหกรายการ โดยเวอร์ชันพารามิเตอร์ 11B มีประสิทธิภาพเหนือกว่าคู่แข่งอื่นๆ เช่น Gemini-1.5-pro, GPT-4o-mini และ Llama-3.2-90B-Vision- Instruct
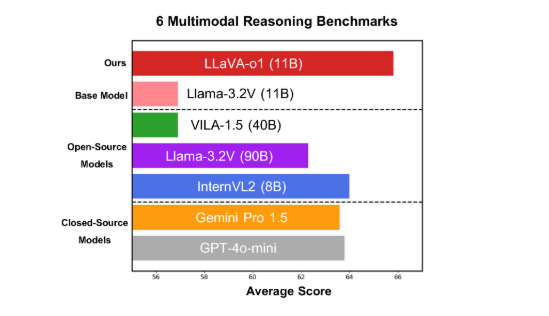
LLaVA-o1 ใช้โมเดล Llama-3.2-Vision และใช้กลไกการให้เหตุผล "การคิดช้า" ซึ่งสามารถดำเนินการกระบวนการให้เหตุผลที่ซับซ้อนมากขึ้นได้อย่างอิสระ ซึ่งเหนือกว่าวิธีพร้อมท์ห่วงโซ่การคิดแบบดั้งเดิม
สำหรับเกณฑ์มาตรฐานการอนุมานหลายรูปแบบ LLaVA-o1 มีประสิทธิภาพเหนือกว่ารุ่นพื้นฐานถึง 8.9% แบบจำลองนี้มีลักษณะเฉพาะตรงที่กระบวนการให้เหตุผลแบ่งออกเป็นสี่ขั้นตอน: สรุป คำอธิบายด้วยภาพ การใช้เหตุผลเชิงตรรกะ และการสร้างข้อสรุป ในแบบจำลองแบบดั้งเดิม กระบวนการให้เหตุผลมักจะค่อนข้างง่ายและอาจนำไปสู่คำตอบที่ผิดได้อย่างง่ายดาย ในขณะที่ LLaVA-o1 รับประกันผลลัพธ์ที่แม่นยำยิ่งขึ้นผ่านการให้เหตุผลหลายขั้นตอนที่มีโครงสร้าง
ตัวอย่างเช่น เมื่อแก้ไขปัญหา "มีวัตถุเหลืออยู่กี่ชิ้นหลังจากลบลูกบอลสว่างขนาดเล็กและวัตถุสีม่วงทั้งหมดแล้ว" LLaVA-o1 จะสรุปปัญหาก่อน จากนั้นจึงดึงข้อมูลจากรูปภาพ จากนั้นให้เหตุผลทีละขั้นตอน และสุดท้ายก็ให้คำตอบ แนวทางแบบเป็นขั้นนี้จะปรับปรุงความสามารถในการให้เหตุผลอย่างเป็นระบบของแบบจำลอง ทำให้มีประสิทธิภาพมากขึ้นในการจัดการปัญหาที่ซับซ้อน

เป็นที่น่าสังเกตว่า LLaVA-o1 แนะนำวิธีการค้นหาลำแสงระดับขั้นตอนในกระบวนการอนุมาน แนวทางนี้ช่วยให้แบบจำลองสร้างคำตอบของผู้สมัครได้หลายคำตอบในแต่ละขั้นตอนการอนุมาน และเลือกคำตอบที่ดีที่สุดเพื่อดำเนินการอนุมานขั้นต่อไป ซึ่งจะช่วยปรับปรุงคุณภาพการอนุมานโดยรวมได้อย่างมาก ด้วยการปรับแต่งอย่างละเอียดภายใต้การดูแลและข้อมูลการฝึกที่สมเหตุสมผล LLaVA-o1 ทำงานได้ดีเมื่อเปรียบเทียบกับโมเดลที่ใหญ่กว่าหรือแบบปิด
ผลการวิจัยของทีมมหาวิทยาลัยปักกิ่งไม่เพียงแต่ส่งเสริมการพัฒนา AI หลายรูปแบบเท่านั้น แต่ยังให้แนวคิดและวิธีการใหม่ๆ สำหรับโมเดลการทำความเข้าใจภาษาภาพในอนาคต ทีมงานระบุว่าโค้ด น้ำหนักก่อนการฝึก และชุดข้อมูลของ LLaVA-o1 จะเป็นโอเพ่นซอร์สโดยสมบูรณ์ และพวกเขาหวังว่าจะมีนักวิจัยและนักพัฒนาจำนวนมากขึ้นร่วมกันสำรวจและประยุกต์ใช้โมเดลเชิงนวัตกรรมนี้
บทความ: https://arxiv.org/abs/2411.10440
GitHub:https://github.com/PKU-YuanGroup/LLaVA-o1
โอเพ่นซอร์สของ LLaVA-o1 จะส่งเสริมการพัฒนาเทคโนโลยีและนวัตกรรมแอปพลิเคชันในด้าน AI หลายรูปแบบอย่างไม่ต้องสงสัย กลไกการอนุมานที่มีประสิทธิภาพและประสิทธิภาพที่ยอดเยี่ยมทำให้เป็นข้อมูลอ้างอิงที่สำคัญสำหรับการวิจัยโมเดลภาษาภาพในอนาคต และคุ้มค่าแก่ความสนใจและความคาดหวัง เราหวังว่าจะมีนักพัฒนาจำนวนมากขึ้นเข้าร่วมและร่วมกันส่งเสริมความก้าวหน้าของเทคโนโลยีปัญญาประดิษฐ์