คุณสงสัยเกี่ยวกับเทคโนโลยีที่อยู่เบื้องหลังผลิตภัณฑ์ AI เช่น ChatGPT และ Wenxinyiyan หรือไม่? พวกเขาทั้งหมดอาศัยโมเดลภาษาขนาดใหญ่ (LLM) เครื่องมือแก้ไขของ Downcodes จะพาคุณไปทำความเข้าใจหลักการทำงานของ LLM ด้วยวิธีที่เรียบง่ายและเข้าใจง่าย แม้ว่าคุณจะเรียนแค่ชั้นประถมศึกษาปีที่ 2 คุณก็สามารถเข้าใจมันได้อย่างง่ายดาย! เราจะเริ่มต้นจากแนวคิดพื้นฐานของโครงข่ายประสาทเทียม และค่อยๆ อธิบายการฝึกโมเดล เทคนิคขั้นสูง และเทคโนโลยีหลัก เช่น สถาปัตยกรรม GPT และ Transformer เพื่อให้คุณเข้าใจ LLM ชัดเจน
คุณเคยได้ยินเกี่ยวกับ AI ขั้นสูง เช่น ChatGPT และ Wen Xinyiyan หรือไม่ เทคโนโลยีหลักเบื้องหลังคือ "โมเดลภาษาขนาดใหญ่" (LLM) คุณพบว่ามันซับซ้อนและเข้าใจยากหรือไม่ ไม่ต้องกังวล แม้ว่าคุณจะมีระดับคณิตศาสตร์ชั้นประถมศึกษาปีที่ 2 เท่านั้น คุณก็สามารถเข้าใจหลักการทำงานของ LLM ได้อย่างง่ายดายหลังจากอ่านบทความนี้!
โครงข่ายประสาทเทียม: ความมหัศจรรย์ของตัวเลข
ก่อนอื่น เราต้องรู้ว่าโครงข่ายประสาทเทียมก็เหมือนกับซูเปอร์คอมพิวเตอร์ มันสามารถประมวลผลได้เฉพาะตัวเลขเท่านั้น ทั้งอินพุตและเอาต์พุตต้องเป็นตัวเลข แล้วเราจะทำให้มันเข้าใจข้อความได้อย่างไร?
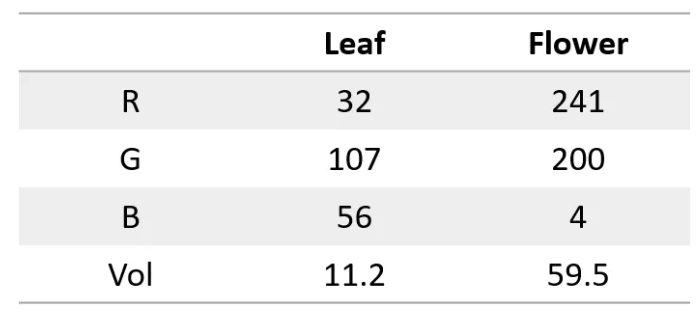
เคล็ดลับคือการแปลงคำให้เป็นตัวเลข เช่น เราสามารถแสดงตัวอักษรแต่ละตัวด้วยตัวเลข เช่น a=1, b=2 และอื่นๆ ด้วยวิธีนี้โครงข่ายประสาทเทียมสามารถ "อ่าน" ข้อความได้
การฝึกโมเดล: ให้เครือข่าย “เรียนรู้” ภาษา
ด้วยข้อความดิจิทัล ขั้นตอนต่อไปคือการฝึกโมเดลและปล่อยให้โครงข่ายประสาทเทียม "เรียนรู้" กฎของภาษา
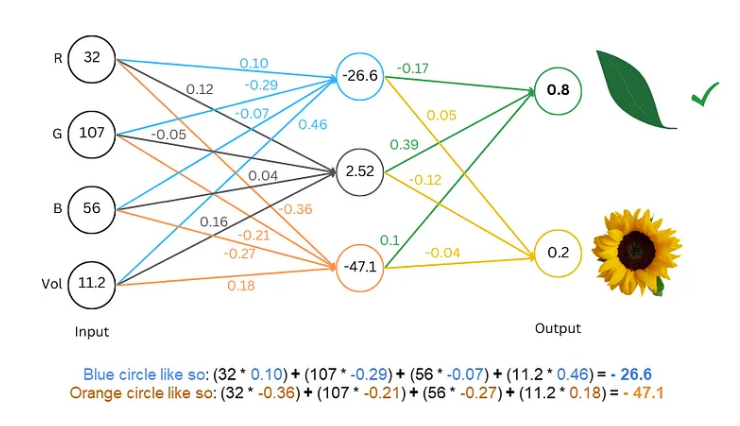
กระบวนการฝึกฝนก็เหมือนกับการเล่นเกมทายผล เราแสดงข้อความบางอย่างแก่เครือข่าย เช่น "Humpty Dumpty" และขอให้เครือข่ายเดาว่าตัวอักษรถัดไปคืออะไร ถ้ามันทายถูกเราจะให้รางวัล ถ้ามันทายผิดเราจะให้โทษ ด้วยการคาดเดาและปรับเปลี่ยนอย่างต่อเนื่อง เครือข่ายจึงสามารถทำนายตัวอักษรถัดไปได้อย่างแม่นยำยิ่งขึ้น ในที่สุดก็สร้างประโยคที่สมบูรณ์ เช่น "Humpty Dumpty นั่งบนผนัง"
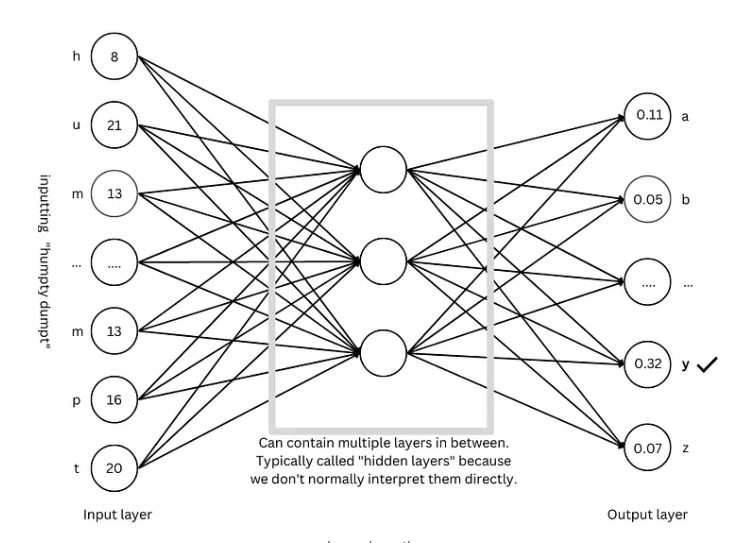
เทคนิคขั้นสูง: ทำให้โมเดลมีความ "ฉลาด" มากขึ้น
เพื่อให้โมเดลมีความ "ฉลาด" มากขึ้น นักวิจัยได้คิดค้นเทคนิคขั้นสูงมากมาย เช่น:
การฝังคำ: แทนที่จะใช้ตัวเลขธรรมดาเพื่อแสดงตัวอักษร เราใช้ชุดตัวเลข (เวกเตอร์) เพื่อแสดงแต่ละคำ ซึ่งสามารถอธิบายความหมายของคำได้ครบถ้วนยิ่งขึ้น
ตัวแบ่งคำย่อย: แบ่งคำออกเป็นหน่วยย่อย (คำย่อย) เช่น การแยก "แมว" เป็น "แมว" และ "s" ซึ่งสามารถลดคำศัพท์และปรับปรุงประสิทธิภาพได้
กลไกการเอาใจใส่ตนเอง: เมื่อโมเดลทำนายคำถัดไปก็จะปรับน้ำหนักของการทำนายตามคำทั้งหมดในบริบทเหมือนกับที่เราเข้าใจความหมายของคำตามบริบทเมื่ออ่าน
การเชื่อมต่อที่เหลือ: เพื่อหลีกเลี่ยงปัญหาการฝึกอบรมที่เกิดจากเลเยอร์เครือข่ายมากเกินไป นักวิจัยได้คิดค้นการเชื่อมต่อที่เหลือเพื่อทำให้เครือข่ายเรียนรู้ได้ง่ายขึ้น
กลไกความสนใจแบบหลายหัว: ด้วยการเรียกใช้กลไกความสนใจหลายรายการพร้อมกัน โมเดลสามารถเข้าใจบริบทจากมุมมองที่แตกต่างกัน และปรับปรุงความแม่นยำของการคาดการณ์
การเข้ารหัสตำแหน่ง: เพื่อให้โมเดลเข้าใจลำดับของคำ นักวิจัยจะเพิ่มข้อมูลตำแหน่งลงในการฝังคำ เช่นเดียวกับที่เราใส่ใจกับลำดับของคำเมื่ออ่าน
สถาปัตยกรรม GPT: “พิมพ์เขียว” สำหรับโมเดลภาษาขนาดใหญ่
สถาปัตยกรรม GPT เป็นหนึ่งในสถาปัตยกรรมโมเดลภาษาขนาดใหญ่ที่ได้รับความนิยมมากที่สุดในปัจจุบัน เปรียบเสมือน "พิมพ์เขียว" ที่เป็นแนวทางในการออกแบบและฝึกอบรมโมเดล สถาปัตยกรรม GPT ผสมผสานเทคนิคขั้นสูงที่กล่าวมาข้างต้นอย่างชาญฉลาด เพื่อให้โมเดลสามารถเรียนรู้และสร้างภาษาได้อย่างมีประสิทธิภาพ
สถาปัตยกรรมหม้อแปลงไฟฟ้า: “การปฏิวัติ” ของโมเดลภาษา
สถาปัตยกรรม Transformer ถือเป็นความก้าวหน้าครั้งสำคัญในด้านโมเดลภาษาในช่วงไม่กี่ปีที่ผ่านมา ไม่เพียงแต่ปรับปรุงความแม่นยำในการทำนายเท่านั้น แต่ยังช่วยลดความยากในการฝึกอบรม ซึ่งเป็นการวางรากฐานสำหรับการพัฒนาโมเดลภาษาขนาดใหญ่ สถาปัตยกรรม GPT ยังพัฒนาตามสถาปัตยกรรม Transformer
อ้างอิง: https://towardsdatascience.com/understand-llms-from-scratch-using-middle-school-math-e602d27ec876
ฉันหวังว่าคำอธิบายโดยบรรณาธิการของ Downcodes จะช่วยให้คุณเข้าใจหลักการทำงานของโมเดลภาษาขนาดใหญ่ได้ แน่นอนว่าเทคโนโลยี LLM ยังคงพัฒนาอยู่ บทความนี้เป็นเพียงส่วนเล็กๆ ของเนื้อหาเชิงลึกที่เพิ่มมากขึ้นเรื่อยๆ ทำให้คุณต้องเรียนรู้และสำรวจต่อไป!