บรรณาธิการของ Downcodes ได้เรียนรู้ว่า Meta เพิ่งเปิดตัวคำสั่งการสนทนาแบบหลายภาษาใหม่หลังจากการทดสอบเกณฑ์มาตรฐานการประเมินความสามารถ Multi-IF เกณฑ์มาตรฐานครอบคลุมแปดภาษาและมีงานการสนทนาสามรอบ 4501 รายการโดยมีเป้าหมายเพื่อประเมินผลขนาดใหญ่อย่างครอบคลุมมากขึ้น ประสิทธิภาพของแบบจำลองภาษา (LLM) ในการใช้งานจริง ต่างจากมาตรฐานการประเมินที่มีอยู่ซึ่งมุ่งเน้นไปที่การสนทนาแบบเลี้ยวเดียวและงานที่ใช้ภาษาเดียวเป็นหลัก Multi-IF มุ่งเน้นไปที่การตรวจสอบความสามารถของแบบจำลองในสถานการณ์ที่ซับซ้อนแบบหลายเลี้ยวและหลายภาษา โดยให้ทิศทางที่ชัดเจนยิ่งขึ้นสำหรับการปรับปรุง LLM
Meta เพิ่งเปิดตัวการทดสอบเกณฑ์มาตรฐานใหม่ที่เรียกว่า Multi-IF ซึ่งออกแบบมาเพื่อประเมินคำสั่งตามความสามารถของโมเดลภาษาขนาดใหญ่ (LLM) ในการสนทนาแบบหลายรอบและสภาพแวดล้อมหลายภาษา เกณฑ์มาตรฐานนี้ครอบคลุมแปดภาษาและมีงานบทสนทนาสามรอบ 4,501 งานโดยเน้นที่ประสิทธิภาพของรุ่นปัจจุบันในสถานการณ์ที่ซับซ้อนแบบหลายรอบและหลายภาษา
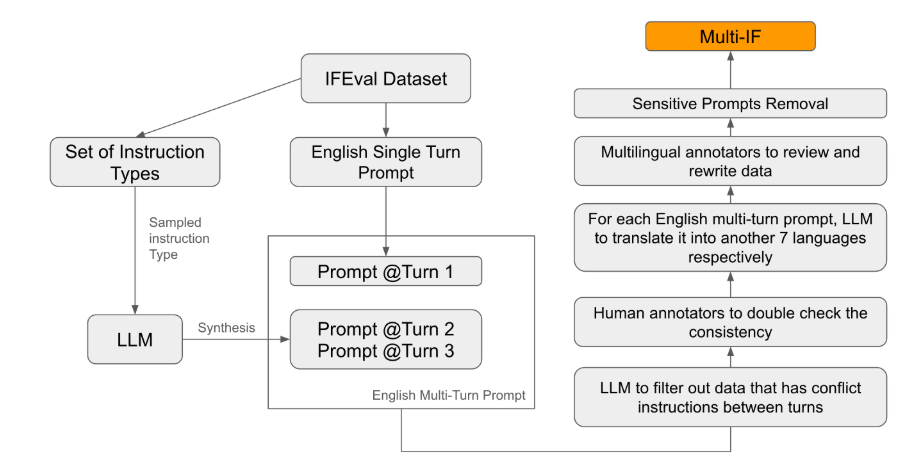
ในบรรดามาตรฐานการประเมินที่มีอยู่ ส่วนใหญ่มุ่งเน้นไปที่การสนทนาแบบเลี้ยวเดียวและงานที่ใช้ภาษาเดียว ซึ่งเป็นเรื่องยากที่จะสะท้อนประสิทธิภาพของแบบจำลองในการใช้งานจริงได้อย่างเต็มที่ การเปิดตัว Multi-IF คือการเติมเต็มช่องว่างนี้ ทีมวิจัยสร้างสถานการณ์การสนทนาที่ซับซ้อนโดยขยายคำสั่งรอบเดียวเป็นคำสั่งหลายรอบ และตรวจสอบให้แน่ใจว่าคำสั่งแต่ละรอบมีความสอดคล้องกันในเชิงตรรกะและก้าวหน้า นอกจากนี้ ชุดข้อมูลยังรองรับหลายภาษาผ่านขั้นตอนต่างๆ เช่น การแปลอัตโนมัติและการพิสูจน์อักษรด้วยตนเอง
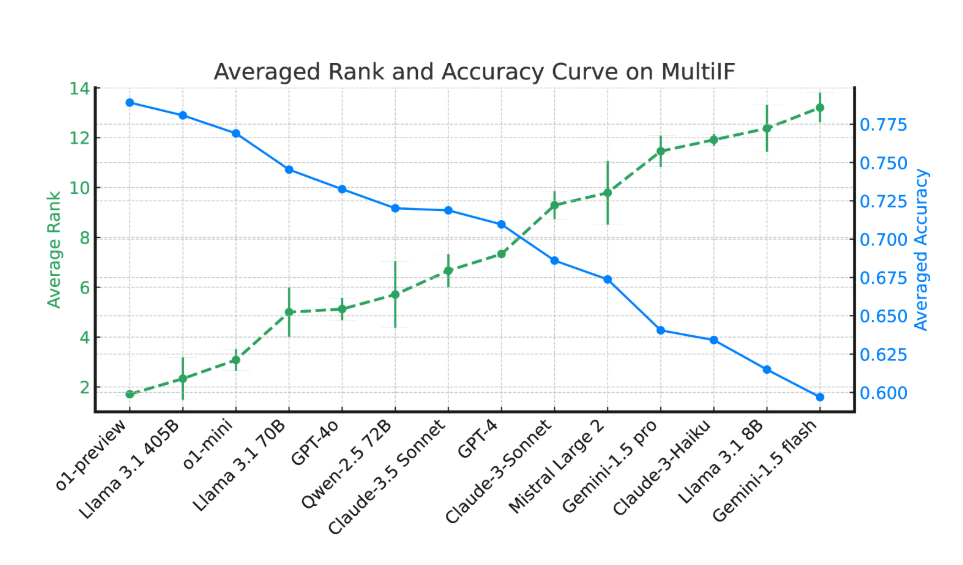
ผลการทดลองแสดงให้เห็นว่าประสิทธิภาพของ LLM ส่วนใหญ่ลดลงอย่างมีนัยสำคัญในการสนทนาหลายรอบ ยกตัวอย่างโมเดล o1-preview ความแม่นยำเฉลี่ยในรอบแรกอยู่ที่ 87.7% แต่ลดลงเหลือ 70.7% ในรอบที่สาม โดยเฉพาะอย่างยิ่งในภาษาที่มีสคริปต์ที่ไม่ใช่ละติน เช่น ฮินดี รัสเซีย และจีน ประสิทธิภาพของโมเดลโดยทั่วไปจะต่ำกว่าภาษาอังกฤษ ซึ่งแสดงข้อจำกัดในงานหลายภาษา
ในการประเมินโมเดลภาษาล้ำสมัย 14 โมเดล o1-preview และ Llama3.1405B ทำงานได้ดีที่สุด โดยมีอัตราความแม่นยำเฉลี่ย 78.9% และ 78.1% ในคำสั่งสามรอบตามลำดับ อย่างไรก็ตาม ในการสนทนาหลายรอบ โมเดลทั้งหมดแสดงให้เห็นว่าความสามารถในการปฏิบัติตามคำสั่งลดลงโดยทั่วไป ซึ่งสะท้อนถึงความท้าทายที่โมเดลต้องเผชิญในงานที่ซับซ้อน ทีมวิจัยยังได้แนะนำ "อัตราการลืมคำสั่ง" (IFR) เพื่อหาปริมาณปรากฏการณ์การลืมคำสั่งของแบบจำลองในการสนทนาหลายรอบ ผลการวิจัยพบว่าแบบจำลองประสิทธิภาพสูงมีประสิทธิภาพค่อนข้างดีในเรื่องนี้
การเปิดตัว Multi-IF ช่วยให้นักวิจัยมีเกณฑ์มาตรฐานที่ท้าทาย และส่งเสริมการพัฒนา LLM ในโลกาภิวัตน์และการใช้งานหลายภาษา การเปิดตัวเกณฑ์มาตรฐานนี้ไม่เพียงแต่เผยให้เห็นข้อบกพร่องของรุ่นปัจจุบันในงานที่มีหลายรอบและหลายภาษา แต่ยังให้ทิศทางที่ชัดเจนสำหรับการปรับปรุงในอนาคต
บทความ: https://arxiv.org/html/2410.15553v2
การเปิดตัวการทดสอบเกณฑ์มาตรฐาน Multi-IF ถือเป็นข้อมูลอ้างอิงที่สำคัญสำหรับการวิจัยโมเดลภาษาขนาดใหญ่ในบทสนทนาแบบหลายรอบและการประมวลผลหลายภาษา และยังชี้ให้เห็นแนวทางในการปรับปรุงโมเดลในอนาคต เป็นที่คาดหวังว่า LLM ที่มีประสิทธิภาพมากขึ้นเรื่อยๆ จะเกิดขึ้นในอนาคต เพื่อรับมือกับความท้าทายของงานที่ซับซ้อนหลายภาษาได้ดีขึ้น