ในช่วงไม่กี่ปีที่ผ่านมา ปัญญาประดิษฐ์มีความก้าวหน้าอย่างมากในด้านต่างๆ แต่ความสามารถในการให้เหตุผลทางคณิตศาสตร์ยังคงเป็นปัญหาคอขวดอยู่เสมอ ในปัจจุบัน การเกิดขึ้นของเกณฑ์มาตรฐานใหม่ที่เรียกว่า FrontierMath ถือเป็นมาตรฐานใหม่สำหรับการประเมินความสามารถทางคณิตศาสตร์ของ AI โดยจะผลักดันความสามารถในการให้เหตุผลทางคณิตศาสตร์ของ AI ไปสู่ขีดจำกัดที่ไม่เคยเกิดขึ้นมาก่อน และก่อให้เกิดความท้าทายที่รุนแรงต่อโมเดล AI ที่มีอยู่ เครื่องมือแก้ไขของ Downcodes จะพาคุณไปทำความเข้าใจอย่างลึกซึ้งเกี่ยวกับ FrontierMath และดูว่ามันจะทำลายความเข้าใจของเราเกี่ยวกับความสามารถทางคณิตศาสตร์ของ AI ได้อย่างไร
ในจักรวาลอันกว้างใหญ่ของปัญญาประดิษฐ์ คณิตศาสตร์เคยถูกมองว่าเป็นป้อมปราการสุดท้ายของปัญญาประดิษฐ์ของเครื่องจักร วันนี้ การทดสอบเกณฑ์มาตรฐานใหม่ที่เรียกว่า FrontierMath ได้เกิดขึ้นแล้ว ซึ่งผลักดันความสามารถในการให้เหตุผลทางคณิตศาสตร์ของ AI ไปสู่ขีดจำกัดที่ไม่เคยมีมาก่อน
Epoch AI ได้ร่วมมือกับสมองชั้นนำมากกว่า 60 ในโลกคณิตศาสตร์เพื่อร่วมกันสร้างสนามท้าทาย AI ที่สามารถเรียกได้ว่าเป็นคณิตศาสตร์โอลิมปิก นี่ไม่ใช่แค่การทดสอบทางเทคนิคเท่านั้น แต่ยังเป็นการทดสอบขั้นสูงสุดของภูมิปัญญาทางคณิตศาสตร์ของปัญญาประดิษฐ์อีกด้วย
ลองจินตนาการถึงห้องทดลองที่เต็มไปด้วยนักคณิตศาสตร์ชั้นนำของโลก ซึ่งได้สร้างปริศนาทางคณิตศาสตร์นับร้อยชิ้นที่เกินกว่าจินตนาการของคนทั่วไป ปัญหาเหล่านี้ครอบคลุมสาขาทางคณิตศาสตร์ที่ทันสมัยที่สุด เช่น ทฤษฎีจำนวน การวิเคราะห์จริง เรขาคณิตพีชคณิต และทฤษฎีหมวดหมู่ และมีความซับซ้อนอย่างมาก แม้แต่อัจฉริยะทางคณิตศาสตร์ที่คว้าเหรียญทองโอลิมปิกคณิตศาสตร์ระดับนานาชาติยังต้องใช้เวลาหลายชั่วโมงหรือหลายวันในการแก้ปัญหา
น่าตกใจที่โมเดล AI ที่ล้ำสมัยในปัจจุบันทำงานได้น่าผิดหวังในเกณฑ์มาตรฐานนี้: ไม่มีโมเดลใดที่สามารถแก้ไขปัญหาได้มากกว่า 2% ผลลัพธ์นี้เหมือนเป็นการปลุกให้ตื่นและตบหน้า AI
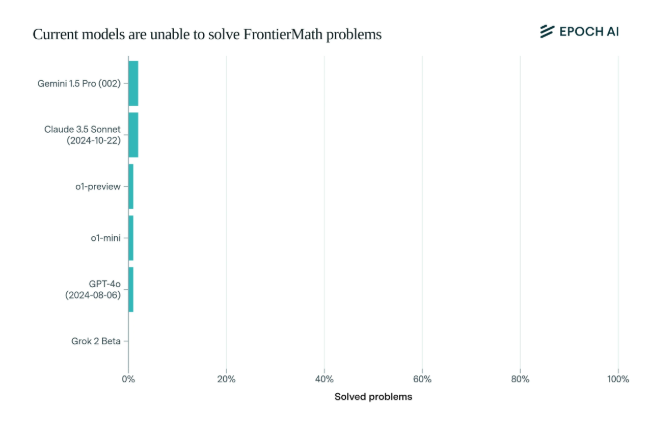
สิ่งที่ทำให้ FrontierMath มีเอกลักษณ์เฉพาะตัวก็คือกลไกการประเมินที่เข้มงวด เกณฑ์มาตรฐานการทดสอบทางคณิตศาสตร์แบบดั้งเดิม เช่น MATH และ GSM8K ได้รับการเพิ่มประสิทธิภาพสูงสุดโดย AI และเกณฑ์มาตรฐานใหม่นี้ใช้คำถามใหม่ที่ยังไม่ได้เผยแพร่ และระบบการตรวจสอบอัตโนมัติ เพื่อหลีกเลี่ยงมลภาวะของข้อมูลอย่างมีประสิทธิภาพ และทดสอบความสามารถในการให้เหตุผลทางคณิตศาสตร์ของ AI อย่างแท้จริง
โมเดลเรือธงของบริษัท AI ชั้นนำ เช่น OpenAI, Anthropic และ Google DeepMind ซึ่งได้รับความสนใจเป็นอย่างมาก ล้มคว่ำโดยรวมในการทดสอบนี้ สิ่งนี้สะท้อนให้เห็นถึงปรัชญาทางเทคนิคที่ลึกซึ้ง: สำหรับคอมพิวเตอร์ ปัญหาทางคณิตศาสตร์ที่ดูเหมือนซับซ้อนอาจเป็นเรื่องง่าย แต่งานที่มนุษย์พบว่าง่ายอาจทำให้ AI ทำอะไรไม่ถูก
ดังที่ Andrej Karpathy กล่าว สิ่งนี้เป็นการยืนยันความขัดแย้งของ Moravec: ความยากของงานอันชาญฉลาดระหว่างมนุษย์กับเครื่องจักรมักจะขัดกับสัญชาตญาณ การทดสอบเกณฑ์มาตรฐานนี้ไม่เพียงแต่เป็นการตรวจสอบความสามารถของ AI อย่างเข้มงวดเท่านั้น แต่ยังเป็นตัวเร่งให้วิวัฒนาการของ AI ไปสู่มิติที่สูงขึ้นอีกด้วย
สำหรับชุมชนคณิตศาสตร์และนักวิจัย AI FrontierMath เปรียบเสมือนยอดเขาเอเวอเรสต์ที่ไม่มีใครพิชิตได้ ไม่เพียงทดสอบความรู้และทักษะเท่านั้น แต่ยังทดสอบความเข้าใจและความคิดสร้างสรรค์อีกด้วย ในอนาคตใครก็ตามที่สามารถเป็นผู้นำในการปีนขึ้นไปถึงจุดสูงสุดของสติปัญญานี้ จะถูกบันทึกไว้ในประวัติศาสตร์ของการพัฒนาปัญญาประดิษฐ์
การเกิดขึ้นของการทดสอบเกณฑ์มาตรฐาน FrontierMath ไม่เพียงแต่เป็นการทดสอบระดับเทคโนโลยี AI ที่มีอยู่อย่างเข้มงวดเท่านั้น แต่ยังชี้ให้เห็นทิศทางการพัฒนา AI ในอนาคตอีกด้วย ซึ่งบ่งชี้ว่า AI ยังคงมีหนทางอีกยาวไกลในด้านการใช้เหตุผลทางคณิตศาสตร์ และ แต่ยังช่วยกระตุ้นการวิจัยอีกด้วย นักวิจัยยังคงสำรวจและสร้างสรรค์สิ่งใหม่ ๆ เพื่อฝ่าฟันอุปสรรคของเทคโนโลยีที่มีอยู่