รายงานบรรณาธิการ Downcodes: ทีมวิจัยจาก Shanghai Jiao Tong University, Cambridge University และ Geely Automobile Research Institute เพิ่งเปิดตัวระบบแปลงข้อความเป็นคำพูด (TTS) ใหม่ที่เรียกว่า F5-TTS ระบบใช้วิธีการปราศจากการถดถอยอัตโนมัติ รวมกับการจับคู่การไหลและหม้อแปลงการแพร่กระจาย (DiT) ซึ่งช่วยให้กระบวนการที่ซับซ้อนของแบบจำลอง TTS แบบดั้งเดิมง่ายขึ้นอย่างมีประสิทธิผล และบรรลุความก้าวหน้าครั้งสำคัญทั้งในด้านคุณภาพการสังเคราะห์และความเร็วในการอนุมาน เมื่อเปรียบเทียบกับรุ่น TTS แบบดั้งเดิม F5-TTS ทำงานได้ดีในแง่ของความเร็วการประมวลผลและความทนทาน นำความเป็นไปได้ใหม่ๆ มาสู่เทคโนโลยีการสังเคราะห์เสียงพูด
เมื่อเร็วๆ นี้ ทีมวิจัยจากมหาวิทยาลัย Shanghai Jiao Tong, มหาวิทยาลัยเคมบริดจ์ และสถาบันวิจัยยานยนต์ Geely ได้เปิดตัวระบบอ่านออกเสียงข้อความ (TTS) ใหม่ที่เรียกว่า F5-TTS สิ่งที่พิเศษเกี่ยวกับระบบนี้คือใช้วิธีที่ปราศจากการถดถอยอัตโนมัติ ซึ่งรวมการจับคู่การไหลเข้ากับหม้อแปลงกระจาย (DiT) ซึ่งทำให้ขั้นตอนที่ซับซ้อนในโมเดล TTS ดั้งเดิมง่ายขึ้น

ดังที่เราทุกคนทราบกันดีว่าโมเดล TTS แบบดั้งเดิมมักต้องการการสร้างแบบจำลองระยะเวลาที่ซับซ้อน การจัดแนวหน่วยเสียง และการเข้ารหัสข้อความแบบพิเศษ ซึ่งจะเพิ่มความซับซ้อนของกระบวนการสังเคราะห์ โดยเฉพาะอย่างยิ่ง โมเดลก่อนหน้านี้ เช่น E2TTS มักจะประสบปัญหา เช่น การบรรจบกันที่ช้า และการจัดแนวข้อความและคำพูดที่ไม่ถูกต้อง ซึ่งทำให้ยากต่อการนำไปใช้อย่างมีประสิทธิภาพในสถานการณ์จริง การเกิดขึ้นของ F5-TTS นั้นมีไว้เพื่อแก้ปัญหาความท้าทายเหล่านี้อย่างแม่นยำ
หลักการทำงานของ F5-TTS นั้นเรียบง่าย ประการแรก ข้อความที่ป้อนจะถูกประมวลผลผ่านสถาปัตยกรรม ConvNeXt เพื่อให้สอดคล้องกับคำพูดได้ง่ายขึ้น จากนั้นลำดับอักขระที่มีเบาะจะถูกป้อนเข้าไปในโมเดลพร้อมกับคำพูดอินพุตที่มีเสียงดัง
การฝึกอบรมระบบอาศัย Diffusion Transformer (DiT) ซึ่งแมปการกระจายเริ่มต้นอย่างง่ายกับการกระจายข้อมูลผ่านการจับคู่โฟลว์ได้อย่างมีประสิทธิภาพ นอกจากนี้ F5-TTS ยังแนะนำกลยุทธ์ Sway Sway Sampling ในระหว่างการอนุมานอย่างสร้างสรรค์ ซึ่งสามารถจัดลำดับความสำคัญของขั้นตอนการไหลในช่วงต้นของขั้นตอนการอนุมานได้ ดังนั้นจึงปรับปรุงการจัดตำแหน่งระหว่างคำพูดที่สร้างขึ้นและข้อความอินพุต
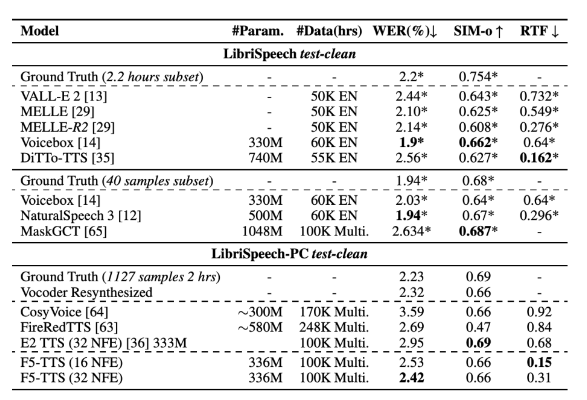
จากผลการวิจัย F5-TTS เหนือกว่าระบบ TTS ในปัจจุบันหลายระบบทั้งในด้านคุณภาพการสังเคราะห์และความเร็วในการอนุมาน ในชุดข้อมูล LibriSpeech-PC โมเดลได้รับอัตราความผิดพลาดของคำ (WER) ที่ 2.42 และปัจจัยแบบเรียลไทม์ (RTF) ที่ 0.15 ณ เวลาอนุมาน ซึ่งดีกว่าโมเดลการแพร่กระจายก่อนหน้า E2TTS อย่างมาก ซึ่งทำงานได้ดีกว่าในการประมวลผลอย่างมาก ความเร็วและมีข้อบกพร่องในเรื่องความทนทาน
ในขณะเดียวกัน กลยุทธ์ Sway Sway Sampling ช่วยเพิ่มความเป็นธรรมชาติและความเข้าใจของคำพูดที่สร้างขึ้นได้อย่างมาก ช่วยให้โมเดลสามารถสร้างรุ่นที่ราบรื่นและแสดงออกได้โดยไม่ต้องฝึกอบรม
F5-TTS ปรับปรุงความทนทานของการจัดตำแหน่งและคุณภาพการสังเคราะห์โดยทำให้กระบวนการง่ายขึ้น และขจัดความจำเป็นในการคาดเดาระยะเวลา การจัดตำแหน่งฟอนิม และการเข้ารหัสข้อความที่ชัดเจน นอกจากนี้ นักวิจัยยังเน้นการพิจารณาด้านจริยธรรมและเสนอความจำเป็นในการสร้างระบบลายน้ำและการตรวจจับเพื่อป้องกันไม่ให้โมเดลถูกละเมิด
ทางเข้าโครงการ: https://github.com/SWivid/F5-TTS
ไฮไลท์:
F5-TTS เป็นระบบแปลงข้อความเป็นคำพูดอัตโนมัติรูปแบบใหม่ที่ช่วยลดความซับซ้อนของโมเดล TTS แบบดั้งเดิม
ระบบใช้สถาปัตยกรรม ConvNeXt และ DiT เพื่อปรับปรุงการจัดตำแหน่งของข้อความและคำพูด และปรับปรุงคุณภาพการสังเคราะห์อย่างมีนัยสำคัญ
นักวิจัยเน้นย้ำถึงความจำเป็นที่ต้องใส่ใจกับประเด็นด้านจริยธรรมและแนะนำการใช้ลายน้ำและกลไกการตรวจจับเพื่อป้องกันการละเมิดที่อาจเกิดขึ้น
การเกิดขึ้นของระบบ F5-TTS ได้นำมาซึ่งความก้าวหน้าครั้งใหม่มาสู่เทคโนโลยีการอ่านออกเสียงข้อความ และประสิทธิภาพที่มีประสิทธิภาพและกระบวนการที่เรียบง่ายนั้น คาดว่าจะมีการใช้กันอย่างแพร่หลายในหลายสาขา อย่างไรก็ตาม ประเด็นด้านจริยธรรมยังต้องให้ความสนใจ และควรมีการวิจัยในภายหลังเพื่อสร้างกลไกการกำกับดูแลที่ดีเพื่อให้แน่ใจว่าการพัฒนาเทคโนโลยีอย่างมีความรับผิดชอบ