บรรณาธิการของ Downcodes นำเสนอข่าวใหญ่มาให้คุณ! มีสมาชิกใหม่ในด้านปัญญาประดิษฐ์ - Zyphra เปิดตัวโมเดลภาษาขนาดเล็ก Zamba2-7B อย่างเป็นทางการ! โมเดลพารามิเตอร์ 7 พันล้านตัวนี้ประสบความสำเร็จอย่างก้าวกระโดดในด้านประสิทธิภาพ โดยเฉพาะอย่างยิ่งในแง่ของประสิทธิภาพและความสามารถในการปรับตัว ซึ่งแสดงให้เห็นข้อได้เปรียบที่น่าประทับใจ ไม่เพียงแต่เหมาะสำหรับสภาพแวดล้อมการประมวลผลประสิทธิภาพสูงเท่านั้น แต่ที่สำคัญกว่านั้น Zamba2-7B ยังสามารถทำงานบน GPU ระดับผู้บริโภคได้อีกด้วย ทำให้ผู้ใช้สามารถสัมผัสกับเสน่ห์ของเทคโนโลยี AI ขั้นสูงได้อย่างง่ายดาย บทความนี้จะเจาะลึกนวัตกรรมของ Zamba2-7B และผลกระทบต่อการประมวลผลภาษาธรรมชาติ
เมื่อเร็วๆ นี้ Zyphra ได้เปิดตัว Zamba2-7B อย่างเป็นทางการ ซึ่งเป็นโมเดลภาษาขนาดเล็กที่มีประสิทธิภาพที่ไม่เคยมีมาก่อน โดยมีจำนวนพารามิเตอร์สูงถึง 7B
โมเดลนี้อ้างว่าเหนือกว่าคู่แข่งในปัจจุบันในด้านคุณภาพและความเร็ว รวมถึง Mistral-7B, Gemma-7B ของ Google และ Llama3-8B ของ Meta
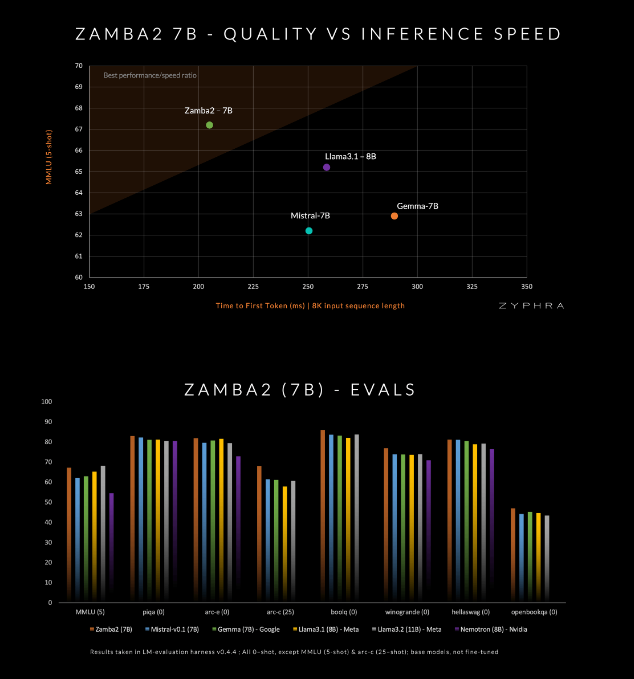
Zamba2-7B ได้รับการออกแบบมาเพื่อตอบสนองความต้องการของสภาพแวดล้อมที่ต้องการความสามารถในการประมวลผลภาษาที่มีประสิทธิภาพ แต่ถูกจำกัดโดยเงื่อนไขของฮาร์ดแวร์ เช่น การประมวลผลบนอุปกรณ์หรือการใช้ GPU ระดับผู้บริโภค ด้วยการปรับปรุงประสิทธิภาพโดยไม่กระทบต่อคุณภาพ Zyphra หวังว่าจะช่วยให้ผู้ใช้ในวงกว้างขึ้น ไม่ว่าจะเป็นองค์กรหรือนักพัฒนารายบุคคล เพลิดเพลินไปกับความสะดวกสบายของ AI ขั้นสูง
Zamba2-7B ได้สร้างนวัตกรรมมากมายในสถาปัตยกรรมเพื่อปรับปรุงประสิทธิภาพและความสามารถในการแสดงออกของโมเดล แตกต่างจากรุ่นก่อนหน้า Zamba1, Zamba2-7B ใช้บล็อกความสนใจร่วมกันสองบล็อก การออกแบบนี้สามารถจัดการกับการขึ้นต่อกันระหว่างการไหลของข้อมูลและลำดับได้ดีขึ้น
บล็อก Mamba2 สร้างแกนหลักของสถาปัตยกรรมทั้งหมด ซึ่งทำให้การใช้พารามิเตอร์ของโมเดลสูงกว่าโมเดลคอนเวอร์เตอร์แบบดั้งเดิม นอกจากนี้ Zyphra ยังใช้การฉายภาพการปรับตัวระดับต่ำ (LoRA) บนบล็อก MLP ที่ใช้ร่วมกัน ซึ่งปรับปรุงความสามารถในการปรับตัวของแต่ละเลเยอร์เพิ่มเติมในขณะที่ยังคงความกะทัดรัดของโมเดลไว้ ด้วยนวัตกรรมเหล่านี้ เวลาตอบสนองครั้งแรกของ Zamba2-7B ลดลง 25% และจำนวนโทเค็นที่ประมวลผลต่อวินาทีเพิ่มขึ้น 20%
ประสิทธิภาพและความสามารถในการปรับตัวของ Zamba2-7B ได้รับการตรวจสอบโดยการทดสอบที่เข้มงวด โมเดลนี้ได้รับการฝึกอบรมล่วงหน้ากับชุดข้อมูลขนาดใหญ่ที่มีโทเค็นสามล้านล้านโทเค็น ซึ่งเป็นข้อมูลเปิดที่มีการคัดกรองอย่างเข้มงวดและมีคุณภาพสูง
นอกจากนี้ Zyphra ยังแนะนำขั้นตอนก่อนการฝึกอบรมแบบ "หลอมอ่อน" ซึ่งจะช่วยลดอัตราการเรียนรู้อย่างรวดเร็วเพื่อประมวลผลโทเค็นคุณภาพสูงได้อย่างมีประสิทธิภาพมากขึ้น กลยุทธ์นี้ช่วยให้ Zamba2-7B ทำงานได้ดีในการวัดประสิทธิภาพ เหนือกว่าคู่แข่งในด้านความเร็วและคุณภาพการอนุมาน และเหมาะสำหรับงานต่างๆ เช่น การทำความเข้าใจและการสร้างภาษาธรรมชาติโดยไม่ต้องใช้ทรัพยากรการประมวลผลจำนวนมากที่จำเป็นสำหรับโมเดลคุณภาพสูงแบบดั้งเดิม
amba2-7B แสดงถึงความก้าวหน้าครั้งสำคัญในโมเดลภาษาขนาดเล็ก โดยคงไว้ซึ่งคุณภาพและประสิทธิภาพที่สูง ในขณะเดียวกันก็ให้ความใส่ใจเป็นพิเศษกับความสามารถในการเข้าถึง ด้วยการออกแบบสถาปัตยกรรมที่เป็นนวัตกรรมและเทคโนโลยีการฝึกอบรมที่มีประสิทธิภาพ Zyphra ได้สร้างแบบจำลองที่ไม่เพียงแต่ใช้งานง่ายเท่านั้น แต่ยังสามารถตอบสนองความต้องการในการประมวลผลภาษาธรรมชาติที่หลากหลายอีกด้วย การเปิดตัว Zamba2-7B แบบโอเพ่นซอร์สเชิญชวนนักวิจัย นักพัฒนา และธุรกิจต่างๆ ให้มาสำรวจศักยภาพของ Zamba2-7B และคาดว่าจะช่วยพัฒนาการพัฒนาการประมวลผลภาษาธรรมชาติขั้นสูงภายในชุมชนที่กว้างขึ้น
ทางเข้าโครงการ: https://www.zyphra.com/post/zamba2-7b
https://github.com/Zyphra/transformers_zamba2
การเปิดตัว Zamba2-7B แบบโอเพ่นซอร์สได้นำพลังใหม่มาสู่การประมวลผลภาษาธรรมชาติ และมอบความเป็นไปได้มากขึ้นสำหรับนักพัฒนา เราหวังว่าจะมีการใช้ Zamba2-7B อย่างแพร่หลายมากขึ้นในอนาคต และส่งเสริมความก้าวหน้าอย่างต่อเนื่องของเทคโนโลยีปัญญาประดิษฐ์!