บรรณาธิการของ Downcodes ได้เรียนรู้ว่านักวิทยาศาสตร์จาก Meta, University of California, Berkeley และ New York University ร่วมกันพัฒนาเทคโนโลยีใหม่ที่เรียกว่า "Thinking Preference Optimization" (TPO) โดยมีเป้าหมายเพื่อปรับปรุงประสิทธิภาพของโมเดลภาษาขนาดใหญ่ (LLM) เทคโนโลยีนี้ปรับปรุงความสามารถในการ "คิด" ของ AI โดยปล่อยให้โมเดลสร้างชุดขั้นตอนการคิดก่อนตอบคำถาม และใช้แบบจำลองการประเมินเพื่อปรับปรุงคุณภาพของคำตอบสุดท้าย ทำให้ทำงานได้ดีขึ้นในงานต่างๆ แตกต่างจากเทคโนโลยี "การคิดแบบลูกโซ่" แบบดั้งเดิม TPO มีการใช้งานที่หลากหลายมากขึ้น โดยเฉพาะอย่างยิ่งแสดงให้เห็นถึงข้อได้เปรียบที่สำคัญในการเขียนเชิงสร้างสรรค์ การใช้เหตุผลอย่างสามัญสำนึก ฯลฯ
เมื่อเร็วๆ นี้ นักวิทยาศาสตร์จาก Meta, มหาวิทยาลัยแคลิฟอร์เนีย, เบิร์กลีย์ และมหาวิทยาลัยนิวยอร์ก ร่วมมือกันเพื่อพัฒนาเทคโนโลยีใหม่ที่เรียกว่า Thought Preference Optimization (TPO) เป้าหมายของเทคโนโลยีนี้คือการปรับปรุงประสิทธิภาพของโมเดลภาษาขนาดใหญ่ (LLM) เมื่อทำงานต่างๆ ทำให้ AI สามารถพิจารณาการตอบสนองได้ละเอียดยิ่งขึ้นก่อนตอบ
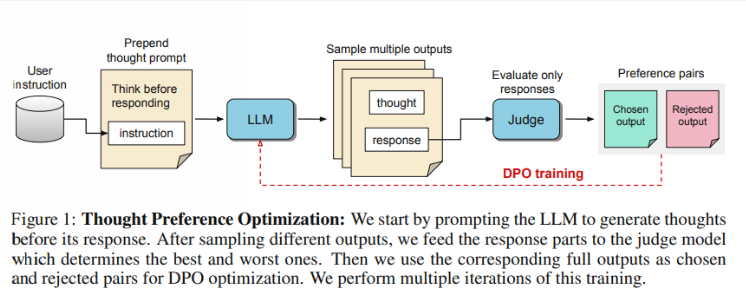
นักวิจัยกล่าวว่าการคิดควรมีประโยชน์ในวงกว้าง ตัวอย่างเช่น ในงานเขียนเชิงสร้างสรรค์ AI สามารถใช้กระบวนการคิดภายในเพื่อวางแผนโครงสร้างโดยรวมและการพัฒนาตัวละคร วิธีการนี้แตกต่างอย่างมากจากเทคโนโลยีการกระตุ้นเตือนแบบ "Chain-of-Thought" (CoT) ก่อนหน้านี้ อย่างหลังส่วนใหญ่จะใช้ในงานทางคณิตศาสตร์และตรรกะ ในขณะที่ TPO มีการใช้งานที่หลากหลายกว่า นักวิจัยกล่าวถึงโมเดล o1 ใหม่ของ OpenAI และเชื่อว่ากระบวนการคิดยังมีประโยชน์สำหรับงานในวงกว้างอีกด้วย
แล้ว TPO ทำงานอย่างไร ขั้นแรก โมเดลจะสร้างชุดขั้นตอนทางความคิดก่อนที่จะตอบคำถาม ถัดไป สร้างผลลัพธ์หลายรายการ ซึ่งจากนั้นจะได้รับการประเมินโดยแบบจำลองการประเมินเฉพาะในคำตอบสุดท้ายเท่านั้น ไม่ใช่ขั้นตอนความคิดด้วยตนเอง สุดท้ายนี้ โมเดลจะได้รับการฝึกผ่านการเพิ่มประสิทธิภาพตามความชอบของผลการประเมินเหล่านี้ นักวิจัยหวังว่าการปรับปรุงคุณภาพของคำตอบสามารถทำได้โดยการปรับปรุงกระบวนการคิด เพื่อให้แบบจำลองได้รับความสามารถในการให้เหตุผลที่มีประสิทธิภาพมากขึ้นในการเรียนรู้โดยปริยาย
ในการทดสอบ โมเดล Llama38B ที่ใช้ TPO ทำงานได้ดีกว่าในคำสั่งทั่วไปตามเกณฑ์มาตรฐานมากกว่าเวอร์ชันที่ไม่มีการอนุมานอย่างชัดเจน ในเกณฑ์มาตรฐาน AlpacaEval และ Arena-Hard อัตราการชนะของ TPO สูงถึง 52.5% และ 37.3% ตามลำดับ สิ่งที่น่าตื่นเต้นยิ่งกว่านั้นคือ TPO กำลังก้าวหน้าในด้านที่โดยปกติแล้วไม่จำเป็นต้องมีการคิดที่ชัดเจน เช่น สามัญสำนึก การตลาด และสุขภาพ
อย่างไรก็ตาม ทีมวิจัยตั้งข้อสังเกตว่าการตั้งค่าปัจจุบันไม่เหมาะกับปัญหาทางคณิตศาสตร์ เนื่องจากจริงๆ แล้ว TPO ทำงานได้แย่กว่าโมเดลพื้นฐานในงานเหล่านี้ สิ่งนี้ชี้ให้เห็นว่าอาจต้องใช้แนวทางที่แตกต่างออกไปสำหรับงานที่มีความเชี่ยวชาญสูง การวิจัยในอนาคตอาจมุ่งเน้นไปที่ประเด็นต่างๆ เช่น การควบคุมความยาวของกระบวนการคิด และผลกระทบของการคิดในแบบจำลองที่ใหญ่ขึ้น
ไฮไลท์:
ทีมวิจัยได้เปิดตัว "Thinking Preference Optimization" (TPO) ซึ่งมีเป้าหมายเพื่อปรับปรุงความสามารถในการคิดของ AI ในการปฏิบัติงาน
? TPO ใช้แบบจำลองการประเมินเพื่อเพิ่มประสิทธิภาพคุณภาพคำตอบโดยให้แบบจำลองสร้างขั้นตอนการคิดก่อนตอบ
การทดสอบแสดงให้เห็นว่า TPO ทำงานได้ดีในด้านต่างๆ เช่น ความรู้ทั่วไปและการตลาด แต่ทำได้ไม่ดีในงานคณิตศาสตร์
โดยรวมแล้ว เทคโนโลยี TPO มอบทิศทางใหม่สำหรับการปรับปรุงโมเดลภาษาขนาดใหญ่ และศักยภาพในการปรับปรุงความสามารถในการคิดของ AI ก็คุ้มค่าที่จะรอคอย อย่างไรก็ตาม เทคโนโลยีนี้มีข้อจำกัดเช่นกัน และการวิจัยในอนาคตจำเป็นต้องปรับปรุงและขยายขอบเขตการใช้งานเพิ่มเติม บรรณาธิการของ Downcodes จะยังคงให้ความสนใจกับการพัฒนาล่าสุดในสาขานี้และนำเสนอรายงานที่น่าตื่นเต้นแก่ผู้อ่านมากขึ้น