OpenAI ได้เปิดตัว gpt-4o-audio-preview รุ่นใหม่ที่สะดุดตา ซึ่งได้สร้างความก้าวหน้าครั้งสำคัญในด้านการสร้างและวิเคราะห์คำพูด ทำให้ผู้ใช้ได้รับประสบการณ์การโต้ตอบด้วยเสียงที่เป็นธรรมชาติและชาญฉลาดยิ่งขึ้น บรรณาธิการของ Downcodes จะพาคุณไปทำความเข้าใจเชิงลึกเกี่ยวกับฟังก์ชันหลัก สถานการณ์การใช้งาน และกลยุทธ์การกำหนดราคาของโมเดลนี้ และวิเคราะห์ผลกระทบที่อาจเกิดขึ้นกับอุตสาหกรรมต่างๆ
OpenAI เป็นผู้นำเทรนด์เทคโนโลยีปัญญาประดิษฐ์อีกครั้ง พร้อมเปิดตัวโมเดล gpt-4o-audio-preview ใหม่ แบบจำลองนี้ไม่เพียงแต่แสดงให้เห็นถึงความสามารถอันน่าทึ่งในการสร้างและวิเคราะห์คำพูดเท่านั้น แต่ยังเปิดโอกาสใหม่ ๆ สำหรับการโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์อีกด้วย มาดูคุณสมบัติของโมเดลนวัตกรรมนี้และการใช้งานที่เป็นไปได้กันดีกว่า
ฟังก์ชันหลักของ gpt-4o-audio-preview ประกอบด้วยสามส่วนหลัก ประการแรก สามารถสร้างการตอบกลับด้วยเสียงที่เป็นธรรมชาติและราบรื่นตามข้อความ ซึ่งให้การสนับสนุนแอปพลิเคชันต่างๆ เช่น ผู้ช่วยด้านเสียงและการบริการลูกค้าเสมือน ประการที่สอง โมเดลนี้มีความสามารถในการวิเคราะห์อารมณ์ น้ำเสียง และระดับเสียงของอินพุตเสียง ซึ่งมีแนวโน้มการใช้งานในวงกว้างในด้านการประมวลผลเชิงอารมณ์และการวิเคราะห์ประสบการณ์ผู้ใช้ สุดท้ายนี้ รองรับการโต้ตอบระหว่างเสียงเป็นเสียง ซึ่งเสียงสามารถใช้เป็นทั้งอินพุตและเอาต์พุตได้ ซึ่งเป็นการวางรากฐานสำหรับระบบการโต้ตอบด้วยเสียงอย่างเต็มรูปแบบ
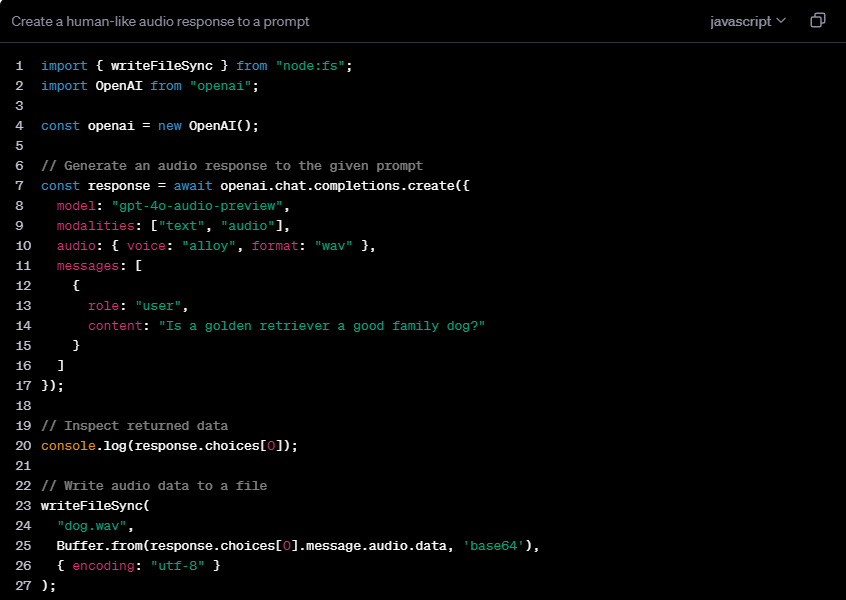
เมื่อเปรียบเทียบกับ Realtime API ที่มีอยู่ของ OpenAI แล้ว gpt-4o-audio-preview จะเน้นที่รายละเอียดของการประมวลผลคำพูดมากกว่า มีความเป็นเลิศในการสร้างคำพูด การวิเคราะห์ความรู้สึก และการโต้ตอบกับคำพูด โดยเน้นไปที่การประมวลผลคุณลักษณะที่ละเอียดอ่อน เช่น น้ำเสียงและอารมณ์ ในทางตรงกันข้าม Realtime API มุ่งเน้นไปที่การประมวลผลข้อมูลแบบเรียลไทม์มากกว่า และเหมาะสำหรับสถานการณ์ที่ต้องการการตอบสนองทันที เช่น การแปลคำพูดเป็นข้อความแบบเรียลไทม์หรือการแปลแบบเรียลไทม์ และแอปพลิเคชันที่มีการโต้ตอบอย่างต่อเนื่องอื่นๆ
ความยืดหยุ่นของ gpt-4o-audio-preview สะท้อนให้เห็นในการรองรับการผสมผสานหลายโหมด ผู้ใช้สามารถเลือกการป้อนข้อความเพื่อสร้างเอาต์พุตข้อความและเสียง หรือใช้อินพุตเสียงเพื่อรับเอาต์พุตข้อความและเสียง นอกจากนี้ยังรองรับการแปลงเสียงเป็นข้อความและโหมดอินพุตแบบผสม ทำให้นักพัฒนามีตัวเลือกมากมาย
ในแง่ของราคา OpenAI ใช้รูปแบบการเรียกเก็บเงินตามโทเค็น ราคาสำหรับการป้อนข้อความค่อนข้างต่ำอยู่ที่ประมาณ 5 ดอลลาร์ต่อล้านโทเค็น เอาต์พุตข้อความจะสูงขึ้นเล็กน้อยที่ประมาณ 15 ดอลลาร์ต่อล้านโทเค็น ต้นทุนการประมวลผลเสียงค่อนข้างสูง โดยอินพุตมีราคา 100 ดอลลาร์ต่อล้านโทเค็น (ประมาณ 0.06 ดอลลาร์ต่อนาที) ในขณะที่เอาต์พุตเสียงสูงถึง 200 ดอลลาร์ต่อล้านโทเค็น (ประมาณ 0.24 ดอลลาร์ต่อนาที) กลยุทธ์การกำหนดราคานี้สะท้อนถึงความซับซ้อนและความต้องการทรัพยากรการประมวลผลของการประมวลผลเสียง
การเปิดตัว gpt-4o-audio-preview จะส่งผลกระทบการเปลี่ยนแปลงต่ออุตสาหกรรมต่างๆ อย่างไม่ต้องสงสัย ในด้านบริการลูกค้า สามารถมอบประสบการณ์การโต้ตอบด้วยเสียงที่เป็นธรรมชาติและเข้าถึงอารมณ์ได้มากขึ้น ในอุตสาหกรรมการศึกษา เทคโนโลยีนี้สามารถใช้เพื่อพัฒนาผู้ช่วยการเรียนรู้ภาษาอัจฉริยะ เพื่อช่วยให้นักเรียนปรับปรุงการออกเสียงและน้ำเสียงของตนเอง ในอุตสาหกรรมบันเทิง คาดว่าจะขับเคลื่อนการสังเคราะห์คำพูดและการโต้ตอบของตัวละครเสมือนจริงได้มากขึ้น นอกจากนี้ ในแง่ของเทคโนโลยีช่วยเหลือ gpt-4o-audio-preview อาจให้บริการคำพูดเป็นข้อความที่แม่นยำยิ่งขึ้นสำหรับผู้มีความบกพร่องทางการได้ยิน หรือให้คำอธิบายเสียงที่สมบูรณ์ยิ่งขึ้นสำหรับผู้มีความบกพร่องทางการมองเห็น
รายละเอียด: https://platform.openai.com/docs/guides/audio/quickstart
โดยรวมแล้ว การเกิดขึ้นของโมเดล gpt-4o-audio-preview ถือเป็นก้าวใหม่ของเทคโนโลยีปัญญาประดิษฐ์ด้านเสียง ฟังก์ชันอันทรงพลังและความเป็นไปได้ในการใช้งานที่หลากหลายจะนำมาซึ่งการเปลี่ยนแปลงครั้งยิ่งใหญ่สำหรับวิธีการโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์ในอนาคต บรรณาธิการของ Downcodes รอคอยที่จะได้เห็นแอปพลิเคชั่นที่เป็นนวัตกรรมมากขึ้นจากโมเดลนี้