บรรณาธิการของ Downcodes รายงาน: โมเดลการสร้างภาพ AI แบบโอเพ่นซอร์สที่เรียกว่า Meissonic เกิดขึ้นแล้ว โดยสามารถสร้างภาพคุณภาพสูงได้โดยใช้พารามิเตอร์เพียงหนึ่งพันล้านพารามิเตอร์ เรียกได้ว่าเป็นยักษ์ใหญ่ด้านน้ำหนักเบาในด้านการสร้างภาพ AI! นี่เป็นเพราะสถาปัตยกรรมคอนเวอร์เตอร์ที่เป็นเอกลักษณ์และวิธีการฝึกอบรมแบบใหม่ที่ทีม R&D นำมาใช้ (นักวิจัยจาก Alibaba, Skywork AI และมหาวิทยาลัยหลายแห่ง) Meissonic ไม่เพียงแต่สามารถทำงานบนพีซีสำหรับเล่นเกมทั่วไปเท่านั้น แต่ยังคาดว่าจะใช้แอปพลิเคชันแปลงข้อความเป็นรูปภาพที่แปลเป็นภาษาท้องถิ่นบนโทรศัพท์มือถือในอนาคต ซึ่งจะช่วยลดเกณฑ์การเข้าสู่การสร้างภาพ AI ลงอย่างมาก
เมื่อเร็วๆ นี้ ทีมวิจัยทางวิทยาศาสตร์ได้ร่วมกันเปิดตัวโมเดลการสร้างภาพ AI แบบโอเพ่นซอร์สที่เรียกว่า Meissonic น่าประหลาดใจที่โมเดลนี้สามารถสร้างภาพคุณภาพสูงโดยใช้พารามิเตอร์เพียงหนึ่งพันล้านพารามิเตอร์เท่านั้น การออกแบบที่กะทัดรัดนี้ทำให้ Meissonic มีศักยภาพในการแปลแอปพลิเคชันแปลงข้อความเป็นรูปภาพบนอุปกรณ์เคลื่อนที่

ทีม R&D ที่อยู่เบื้องหลังเทคโนโลยีนี้ประกอบด้วยนักวิจัยจาก Alibaba, Skywork AI และมหาวิทยาลัยหลายแห่ง พวกเขาใช้สถาปัตยกรรมตัวแปลงที่เป็นเอกลักษณ์และวิธีการฝึกอบรมแบบใหม่เพื่อให้ Meissonic สามารถทำงานบนพีซีสำหรับเล่นเกมทั่วไปและแม้แต่โทรศัพท์มือถือได้ในอนาคต
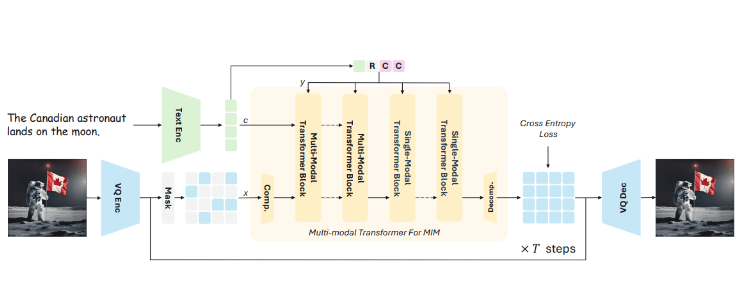
วิธีการฝึกอบรมของ Meissonic ใช้เทคนิคที่เรียกว่า "การสร้างแบบจำลองภาพมาสก์" ซึ่งหมายความว่าส่วนหนึ่งของภาพจะถูกซ่อนไว้ในระหว่างกระบวนการฝึกอบรม แบบจำลองได้เรียนรู้วิธีสร้างส่วนที่ขาดหายไปขึ้นมาใหม่ตามขอบเขตที่มองเห็นได้และคำอธิบายที่เป็นข้อความ แนวทางนี้ช่วยให้โมเดลเข้าใจความสัมพันธ์ระหว่างองค์ประกอบรูปภาพและข้อความ
สถาปัตยกรรมของ Meissonic ช่วยให้สามารถสร้างภาพที่มีความละเอียดสูง 1024x1024 พิกเซล ไม่ว่าจะเป็นฉากที่สมจริงหรือข้อความที่มีสไตล์ อีโมติคอน หรือแม้แต่สติกเกอร์การ์ตูน
แตกต่างจากโมเดล autoregressive แบบดั้งเดิมที่ค่อยๆ สร้างภาพ Meissonic คาดการณ์ข้อมูลภาพทั้งหมดพร้อมกันผ่านการเพิ่มประสิทธิภาพการทำซ้ำแบบขนาน นวัตกรรมนี้ช่วยลดขั้นตอนการถอดรหัสลงอย่างมาก โดยลดเวลาลงประมาณ 99% และปรับปรุงความเร็วในการสร้างภาพอย่างมาก
ในกระบวนการสร้างแบบจำลอง นักวิจัยได้ดำเนินการผ่านสี่ขั้นตอน:
ขั้นแรก พวกเขาใช้รูปภาพขนาด 256x256 พิกเซลจำนวน 200 ล้านภาพเพื่อสอนแนวคิดพื้นฐานของโมเดล จากนั้นจึงใช้คู่ข้อความรูปภาพที่มีการคัดกรองอย่างเข้มงวดจำนวน 10 ล้านคู่เพื่อปรับปรุงความสามารถในการทำความเข้าใจข้อความ จากนั้นโมเดลจึงสามารถส่งออกข้อมูลด้วยเลเยอร์การบีบอัดแบบพิเศษได้ ภาพขนาด 1024x1024 พิกเซลต่อพิกเซล ในที่สุด พวกเขาก็ทำการปรับแต่งอย่างละเอียดโดยรวมข้อมูลจากการตั้งค่าของมนุษย์เพื่อปรับปรุงประสิทธิภาพของโมเดล

สิ่งที่น่าสนใจ แม้ว่าจะมีพารามิเตอร์จำนวนน้อยกว่า แต่ Meissonic ก็มีประสิทธิภาพเหนือกว่าโมเดลขนาดใหญ่บางรุ่น เช่น SDXL และ DeepFloyd-XL ในการวัดประสิทธิภาพหลายรายการ โดยได้รับ "คะแนนความชอบของมนุษย์" สูงถึง 28.83 นอกจากนี้ Meissonic ยังสามารถแพตช์และขยายรูปภาพได้โดยไม่ต้องผ่านการฝึกอบรมเพิ่มเติม ทำให้ผู้ใช้สามารถเพิ่มส่วนของภาพที่ขาดหายไปหรือปรับปรุงรูปภาพที่มีอยู่อย่างสร้างสรรค์ได้อย่างง่ายดาย
ทีมวิจัยเชื่อว่าวิธีการนี้อาจส่งเสริมการพัฒนาเครื่องกำเนิดภาพ AI ที่ปรับแต่งได้อย่างรวดเร็วและต้นทุนต่ำ และยังคาดว่าจะส่งเสริมการพัฒนาแอปพลิเคชันข้อความเป็นรูปภาพบนอุปกรณ์มือถืออีกด้วย เพื่อนที่สนใจสามารถค้นหาเวอร์ชันสาธิตบน Hugging Face และดูโค้ดของโมเดลบน GitHub ซึ่งสามารถรันบน GPU สำหรับผู้บริโภคที่มีหน่วยความจำวิดีโอธรรมดาขนาด 8GB ได้อย่างง่ายดาย
สาธิต:https://huggingface.co/spaces/MeissonFlow/meissonic
โครงการ: https://github.com/viiika/Meissonic
ไฮไลท์:
Meissonic เป็นโมเดล AI แบบโอเพ่นซอร์สที่สามารถสร้างภาพคุณภาพสูงด้วยพารามิเตอร์เพียงหนึ่งพันล้านพารามิเตอร์ เหมาะสำหรับใช้กับพีซีสำหรับเล่นเกมทั่วไปและอุปกรณ์มือถือในอนาคต
ด้วยการใช้วิธีการฝึกอบรมการเพิ่มประสิทธิภาพซ้ำซ้อนแบบคู่ขนาน Meissonic สามารถสร้างภาพได้เร็วกว่ารุ่นทั่วไปถึง 99%
? แม้จะมีพารามิเตอร์ขนาดเล็ก แต่ Meissonic ก็มีประสิทธิภาพเหนือกว่าโมเดลขนาดใหญ่ในการทดสอบหลายรายการ และช่วยให้สามารถลงสีและขยายรูปภาพได้โดยไม่ต้องมีการฝึกอบรม
โดยรวมแล้ว การเกิดขึ้นของ Meissonic ได้นำความเป็นไปได้ใหม่ๆ มาสู่วงการการสร้างภาพด้วย AI การออกแบบที่มีน้ำหนักเบาและประสิทธิภาพที่มีประสิทธิภาพนั้นคุ้มค่ากับการรอคอย! บรรณาธิการของ Downcodes แนะนำให้ทุกคนไปที่ Hugging Face และ GitHub เพื่อสัมผัสและสำรวจโมเดล AI อันทรงพลังนี้