บรรณาธิการของ Downcodes ได้เรียนรู้ว่า Alibaba Damo Academy และ Renmin University of China ร่วมกันเปิดซอร์สโมเดลการประมวลผลเอกสารที่เรียกว่า mPLUG-DocOwl1.5 โมเดลสามารถเข้าใจเนื้อหาเอกสารโดยไม่ต้องจดจำ OCR และทำงานได้ดีในการทดสอบเกณฑ์มาตรฐานหลายรายการ โดยมีแกนหลักอยู่ที่วิธี "การเรียนรู้โครงสร้างแบบครบวงจร" ซึ่งปรับปรุงความเข้าใจเชิงโครงสร้างของโมเดลภาษาขนาดใหญ่หลายรูปแบบ (MLLM) ของรูปภาพข้อความที่หลากหลาย . โมเดลดังกล่าวได้เผยแพร่โค้ด โมเดล และชุดข้อมูลสู่สาธารณะบน GitHub ซึ่งเป็นทรัพยากรอันทรงคุณค่าสำหรับการวิจัยในสาขาที่เกี่ยวข้อง
เมื่อเร็วๆ นี้ Alibaba Damo Academy และ Renmin University of China ร่วมกันเปิดโมเดลการประมวลผลเอกสารที่เรียกว่า mPLUG-DocOwl1.5 โมเดลนี้มุ่งเน้นไปที่การทำความเข้าใจเนื้อหาเอกสารโดยไม่ต้องจดจำ OCR และได้ผลลัพธ์ในการทำความเข้าใจการทดสอบเกณฑ์มาตรฐานของเอกสารภาพหลายรายการ
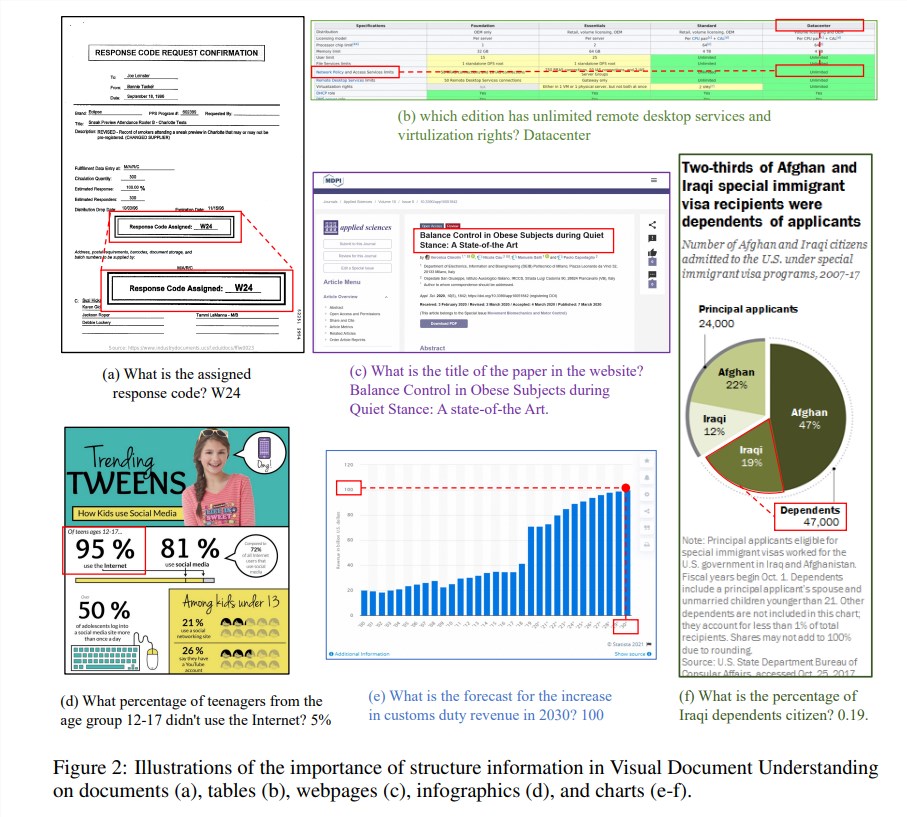
ข้อมูลเชิงโครงสร้างมีความสำคัญอย่างยิ่งต่อการทำความเข้าใจความหมายของรูปภาพที่มีข้อความมากมาย เช่น เอกสาร ตาราง และแผนภูมิ แม้ว่าโมเดลภาษาขนาดใหญ่หลายรูปแบบ (MLLM) ที่มีอยู่จะมีความสามารถในการจดจำข้อความ แต่ก็ขาดความสามารถในการเข้าใจโครงสร้างทั่วไปของรูปภาพในเอกสารข้อความที่หลากหลาย เพื่อที่จะแก้ไขปัญหานี้ mPLUG-DocOwl1.5 เน้นย้ำถึงความสำคัญของข้อมูลโครงสร้างในการทำความเข้าใจเอกสารภาพ และเสนอ "การเรียนรู้โครงสร้างแบบครบวงจร" เพื่อปรับปรุงประสิทธิภาพของ MLLM
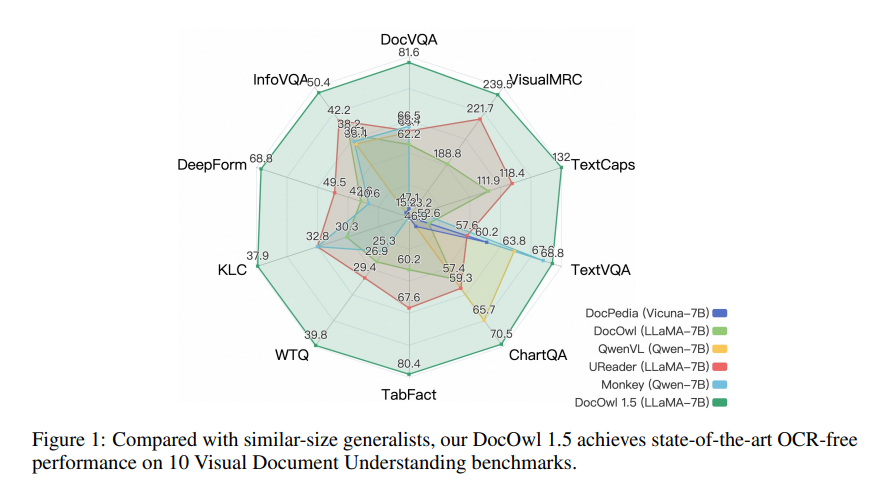
"การเรียนรู้โครงสร้างแบบครบวงจร" ของโมเดลครอบคลุม 5 ส่วน ได้แก่ เอกสาร เว็บเพจ ตาราง แผนภูมิ และรูปภาพธรรมชาติ รวมถึงงานแยกวิเคราะห์ที่คำนึงถึงโครงสร้างและงานการวางตำแหน่งข้อความแบบหลายรายละเอียด เพื่อที่จะเข้ารหัสข้อมูลโครงสร้างได้ดีขึ้น นักวิจัยได้ออกแบบโมดูลภาพเป็นข้อความที่เรียบง่ายและมีประสิทธิภาพ H-Reducer ซึ่งไม่เพียงแต่รักษาข้อมูลเค้าโครงไว้เท่านั้น แต่ยังช่วยลดความยาวของคุณลักษณะด้านภาพด้วยการรวมแพตช์รูปภาพที่อยู่ติดกันในแนวนอนผ่านการบิดเกลียว ทำให้สามารถ โมเดลภาษาขนาดใหญ่เพื่อให้เข้าใจภาพความละเอียดสูงได้อย่างมีประสิทธิภาพมากขึ้น
นอกจากนี้ เพื่อสนับสนุนการเรียนรู้เชิงโครงสร้าง ทีมวิจัยได้สร้าง DocStruct4M ซึ่งเป็นชุดการฝึกอบรมที่ครอบคลุมซึ่งประกอบด้วยตัวอย่าง 4 ล้านตัวอย่างตามชุดข้อมูลที่เปิดเผยต่อสาธารณะ ซึ่งประกอบด้วยลำดับข้อความที่ทราบโครงสร้างและคู่กล่องขอบเขตข้อความแบบหลายรายละเอียด เพื่อที่จะกระตุ้นความสามารถในการให้เหตุผลของ MLLM ในด้านเอกสารเพิ่มเติม พวกเขายังได้สร้างชุดข้อมูลการปรับแต่งการให้เหตุผล DocReason25K ซึ่งประกอบด้วยตัวอย่างคุณภาพสูง 25,000 ตัวอย่าง
mPLUG-DocOwl1.5 ใช้กรอบงานการฝึกอบรมแบบสองขั้นตอน ซึ่งขั้นแรกจะดำเนินการเรียนรู้โครงสร้างแบบครบวงจร จากนั้นจึงทำการปรับแต่งแบบละเอียดหลายงานในงานดาวน์สตรีมหลายงาน ด้วยวิธีการฝึกอบรมนี้ mPLUG-DocOwl1.5 บรรลุประสิทธิภาพที่ล้ำสมัยในเกณฑ์มาตรฐานการทำความเข้าใจเอกสารภาพ 10 รายการ ซึ่งปรับปรุงประสิทธิภาพ SOTA ของ 7B LLM มากกว่า 10 เปอร์เซ็นต์ในเกณฑ์มาตรฐาน 5 รายการ
ปัจจุบันโค้ด โมเดล และชุดข้อมูลของ mPLUG-DocOwl1.5 ได้รับการเผยแพร่สู่สาธารณะแล้วบน GitHub
ที่อยู่โครงการ: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
ที่อยู่กระดาษ: https://arxiv.org/pdf/2403.12895
โอเพ่นซอร์สของ mPLUG-DocOwl1.5 นำความเป็นไปได้ใหม่ๆ มาสู่การวิจัยและการประยุกต์ใช้ในด้านการทำความเข้าใจเอกสารแบบภาพ ประสิทธิภาพที่มีประสิทธิภาพและวิธีการเข้าถึงที่สะดวกสมควรได้รับความสนใจและการใช้งานของนักพัฒนา คาดว่าโมเดลนี้สามารถนำไปใช้ในสถานการณ์จริงได้มากขึ้นในอนาคต