บรรณาธิการของ Downcodes จะพาคุณไปเรียนรู้เกี่ยวกับผลการวิจัยล่าสุดของ Swiss Federal Institute of Technology ในเมืองโลซาน (EPFL)! การศึกษานี้ให้การเปรียบเทียบเชิงลึกของวิธีการฝึกอบรมแบบปรับตัวหลักสองวิธีสำหรับโมเดลภาษาขนาดใหญ่ (LLM): การเรียนรู้ตามบริบท (ICL) และการปรับแต่งคำสั่งอย่างละเอียด (IFT) และใช้เกณฑ์มาตรฐาน MT-Bench เพื่อประเมินความสามารถของโมเดลในการปฏิบัติตาม คำแนะนำ. ผลการวิจัยแสดงให้เห็นว่าทั้งสองวิธีมีข้อดีของตัวเองในสถานการณ์ที่แตกต่างกัน ซึ่งเป็นข้อมูลอ้างอิงที่มีคุณค่าสำหรับการเลือกวิธีการฝึกอบรม LLM
การศึกษาล่าสุดจาก Ecole Polytechnique Fédérale de Lausanne (EPFL) ในสวิตเซอร์แลนด์เปรียบเทียบวิธีการฝึกอบรมแบบปรับตัวหลักสองวิธีสำหรับโมเดลภาษาขนาดใหญ่ (LLM) ได้แก่ การเรียนรู้ตามบริบท (ICL) และการปรับแต่งการสอนอย่างละเอียด (IFT) นักวิจัยใช้เกณฑ์มาตรฐาน MT-Bench เพื่อประเมินความสามารถของแบบจำลองในการทำตามคำแนะนำ และพบว่าทั้งสองวิธีทำงานได้ดีขึ้นและแย่ลงภายใต้สถานการณ์บางอย่าง
การวิจัยพบว่าเมื่อจำนวนตัวอย่างการฝึกอบรมที่มีอยู่มีน้อย (เช่น ไม่เกิน 50 ตัวอย่าง) ผลกระทบของ ICL และ IFT ก็ใกล้เคียงกันมาก สิ่งนี้ชี้ให้เห็นว่า ICL อาจเป็นทางเลือกแทน IFT เมื่อข้อมูลมีจำกัด
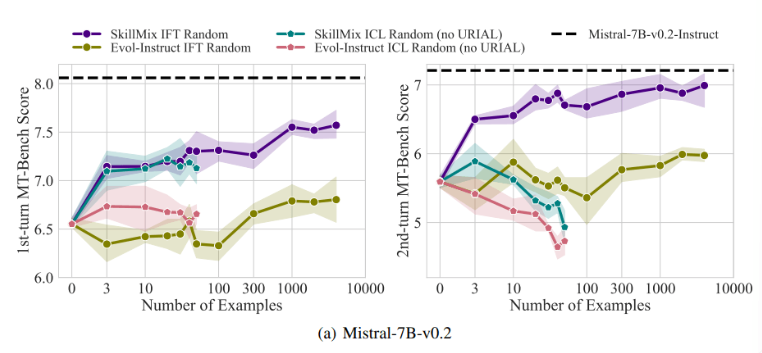
อย่างไรก็ตาม เมื่อความซับซ้อนของงานเพิ่มขึ้น เช่น ในสถานการณ์การสนทนาหลายรอบ ข้อดีของ IFT ก็ปรากฏชัดเจน นักวิจัยเชื่อว่าโมเดล ICL มีแนวโน้มที่จะไม่เหมาะสมกับสไตล์ของกลุ่มตัวอย่างเพียงกลุ่มเดียว ส่งผลให้ประสิทธิภาพการทำงานต่ำเมื่อจัดการกับการสนทนาที่ซับซ้อน หรือแม้กระทั่งแย่กว่าโมเดลพื้นฐานด้วยซ้ำ
การศึกษายังได้ตรวจสอบวิธี URIAL ซึ่งใช้ตัวอย่างเพียง 3 ตัวอย่างและคำแนะนำในการปฏิบัติตามกฎเกณฑ์เพื่อฝึกแบบจำลองภาษาพื้นฐาน แม้ว่า URIAL จะได้รับผลลัพธ์บางอย่าง แต่ก็ยังมีช่องว่างเมื่อเทียบกับโมเดลที่ IFT ฝึกฝน นักวิจัย EPFL ปรับปรุงประสิทธิภาพของ URIAL โดยปรับปรุงกลยุทธ์การเลือกตัวอย่าง ทำให้ใกล้เคียงกับแบบจำลองที่มีการปรับแต่งอย่างละเอียด สิ่งนี้เน้นย้ำถึงความสำคัญของข้อมูลการฝึกอบรมคุณภาพสูงสำหรับ ICL, IFT และการฝึกอบรมโมเดลพื้นฐาน
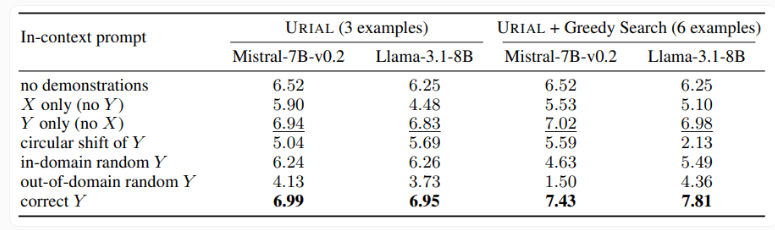
นอกจากนี้ การศึกษายังพบว่าพารามิเตอร์การถอดรหัสมีผลกระทบอย่างมีนัยสำคัญต่อประสิทธิภาพของโมเดล พารามิเตอร์เหล่านี้จะกำหนดวิธีที่โมเดลสร้างข้อความ และมีความสำคัญสำหรับทั้ง LLM พื้นฐานและโมเดลที่ได้รับการฝึกด้วย URIAL
นักวิจัยตั้งข้อสังเกตว่าแม้แต่โมเดลพื้นฐานก็สามารถปฏิบัติตามคำแนะนำได้ในระดับหนึ่งโดยได้รับพารามิเตอร์การถอดรหัสที่เหมาะสม
ความสำคัญของการศึกษาครั้งนี้คือการเผยให้เห็นว่าการเรียนรู้ตามบริบทสามารถปรับแต่งโมเดลภาษาได้อย่างรวดเร็วและมีประสิทธิภาพ โดยเฉพาะอย่างยิ่งเมื่อตัวอย่างการฝึกอบรมมีจำกัด แต่สำหรับงานที่ซับซ้อน เช่น การสนทนาหลายรอบ การปรับคำสั่งอย่างละเอียดยังคงเป็นทางเลือกที่ดีกว่า
เมื่อขนาดของชุดข้อมูลเพิ่มขึ้น ประสิทธิภาพของ IFT จะยังคงปรับปรุงต่อไป ในขณะที่ประสิทธิภาพของ ICL จะมีเสถียรภาพหลังจากถึงจำนวนตัวอย่างที่กำหนด นักวิจัยเน้นย้ำว่าตัวเลือกระหว่าง ICL และ IFT ขึ้นอยู่กับปัจจัยหลายประการ เช่น ทรัพยากรที่มีอยู่ ปริมาณข้อมูล และข้อกำหนดการใช้งานเฉพาะ ไม่ว่าคุณจะเลือกวิธีใดก็ตาม ข้อมูลการฝึกอบรมคุณภาพสูงถือเป็นสิ่งสำคัญ
โดยรวมแล้ว การศึกษา EPFL นี้ให้ข้อมูลเชิงลึกใหม่ๆ เกี่ยวกับการเลือกวิธีการฝึกอบรมสำหรับโมเดลภาษาขนาดใหญ่ และชี้แนะแนวทางสำหรับแนวทางการวิจัยในอนาคต การเลือก ICL หรือ IFT จำเป็นต้องชั่งน้ำหนักข้อดีและข้อเสียตามสถานการณ์เฉพาะ และข้อมูลคุณภาพสูงถือเป็นกุญแจสำคัญเสมอ เราหวังว่างานวิจัยนี้จะช่วยให้ทุกคนเข้าใจและประยุกต์ใช้โมเดลภาษาขนาดใหญ่ได้ดียิ่งขึ้น