บรรณาธิการของ Downcodes ได้เรียนรู้ว่าสถาบันวิจัยปัญญาประดิษฐ์ Beijing Zhiyuan ได้ร่วมมือกับมหาวิทยาลัยหลายแห่งเพื่อเปิดตัวแบบจำลองขนาดใหญ่สำหรับการทำความเข้าใจวิดีโอที่มีความยาวเป็นพิเศษที่เรียกว่า Video-XL โมเดลนี้ทำงานได้ดีในการประมวลผลวิดีโอขนาดยาวที่มีความยาวมากกว่า 10 นาที โดยได้รับตำแหน่งผู้นำในการวัดประสิทธิภาพหลายรายการ แสดงให้เห็นถึงความสามารถในการสรุปข้อมูลทั่วไปที่แข็งแกร่งและประสิทธิภาพในการประมวลผล Video-XL ใช้โมเดลภาษาเพื่อบีบอัดลำดับภาพขนาดยาวและให้ความแม่นยำเกือบ 95% ในงานต่างๆ เช่น "การค้นหาเข็มในกองหญ้า" ต้องการเพียงการ์ดกราฟิกที่มีหน่วยความจำวิดีโอ 80G เพื่อประมวลผลอินพุต 2,048 เฟรม โอเพ่นซอร์สของโมเดลนี้จะส่งเสริมความร่วมมือและการพัฒนาชุมชนการวิจัยเพื่อความเข้าใจเกี่ยวกับวิดีโอหลายรูปแบบทั่วโลก
สถาบันวิจัยปัญญาประดิษฐ์ Beijing Zhiyuan ได้ผนึกกำลังกับมหาวิทยาลัยต่างๆ เช่น Shanghai Jiao Tong University, Renmin University of China, Peking University และ Beijing University of Post and Telecommunications เพื่อเปิดตัวโมเดลการทำความเข้าใจวิดีโอขนาดยาวพิเศษขนาดใหญ่ที่เรียกว่า Video-XL โมเดลนี้เป็นการสาธิตที่สำคัญเกี่ยวกับความสามารถหลักของโมเดลขนาดใหญ่หลายรูปแบบ และเป็นก้าวสำคัญสู่ปัญญาประดิษฐ์ทั่วไป (AGI) เมื่อเปรียบเทียบกับรุ่นใหญ่ที่มีหลายโมดัลที่มีอยู่แล้ว Video-XL จะแสดงประสิทธิภาพและประสิทธิผลที่ดีกว่าเมื่อประมวลผลวิดีโอขนาดยาวที่มีความยาวมากกว่า 10 นาที

Video-XL ใช้ความสามารถดั้งเดิมของโมเดลภาษา (LLM) เพื่อบีบอัดลำดับภาพขนาดยาว ยังคงความสามารถในการเข้าใจวิดีโอขนาดสั้น และแสดงความสามารถในการวางลักษณะทั่วไปที่ยอดเยี่ยมในการทำความเข้าใจวิดีโอขนาดยาว โมเดลนี้เป็นอันดับแรกในหลายงานในการวัดประสิทธิภาพการทำความเข้าใจวิดีโอขนาดยาวกระแสหลักหลายรายการ Video-XL มีความสมดุลที่ดีระหว่างประสิทธิภาพและประสิทธิภาพ ต้องการเพียงการ์ดกราฟิกที่มีหน่วยความจำวิดีโอ 80G เพื่อประมวลผลอินพุตเฟรม 2048 ตัวอย่างวิดีโอที่มีความยาวหนึ่งชั่วโมง และบรรลุเกือบ 95% ในงานวิดีโอ "เข็มในกองหญ้า" % ความแม่นยำ.
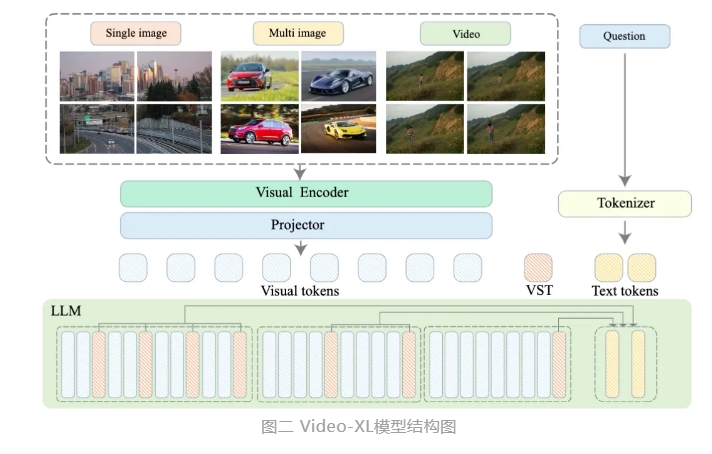
คาดว่า Video-XL จะแสดงมูลค่าแอปพลิเคชันที่กว้างขวางในสถานการณ์แอปพลิเคชัน เช่น การสรุปภาพยนตร์ การตรวจจับความผิดปกติของวิดีโอ และการตรวจจับตำแหน่งโฆษณา และกลายเป็นผู้ช่วยที่ทรงพลังสำหรับการทำความเข้าใจวิดีโอที่ยาวนาน การเปิดตัวโมเดลนี้นับเป็นก้าวสำคัญในด้านประสิทธิภาพและความแม่นยำของเทคโนโลยีการทำความเข้าใจวิดีโอขนาดยาว และให้การสนับสนุนทางเทคนิคที่แข็งแกร่งสำหรับการประมวลผลและการวิเคราะห์เนื้อหาวิดีโอขนาดยาวแบบอัตโนมัติในอนาคต
ปัจจุบัน รหัสโมเดลของ Video-XL เป็นแบบโอเพ่นซอร์สเพื่อส่งเสริมความร่วมมือและการแบ่งปันเทคโนโลยีในชุมชนวิจัยความเข้าใจเกี่ยวกับวิดีโอหลายรูปแบบทั่วโลก
ชื่อรายงาน: Video-XL: โมเดลภาษาการมองเห็นยาวเป็นพิเศษสำหรับการทำความเข้าใจวิดีโอระดับชั่วโมง
ลิงค์กระดาษ: https://arxiv.org/abs/2409.14485
ลิงค์โมเดล: https://huggingface.co/sy1998/Video_XL
ลิงค์โครงการ: https://github.com/VectorSpaceLab/Video-XL
โอเพ่นซอร์สของ Video-XL นำความเป็นไปได้ใหม่ๆ มาสู่การวิจัยและการประยุกต์ใช้ในด้านความเข้าใจเกี่ยวกับวิดีโอขนาดยาว ประสิทธิภาพและความแม่นยำของวิดีโอจะส่งเสริมการพัฒนาเทคโนโลยีที่เกี่ยวข้องเพิ่มเติม และให้การสนับสนุนทางเทคนิคสำหรับสถานการณ์การใช้งานเพิ่มเติมในอนาคต เราหวังว่าจะได้เห็นแอปพลิเคชั่นที่เป็นนวัตกรรมใหม่ที่ใช้ Video-XL ในอนาคต