บรรณาธิการของ Downcodes จะแนะนำคุณเกี่ยวกับงานวิจัยล่าสุดจากมหาวิทยาลัยเทคนิคแห่งดาร์มสตัดท์ในประเทศเยอรมนี การศึกษานี้ใช้ปัญหา Bongard เป็นเครื่องมือทดสอบในการประเมินประสิทธิภาพของโมเดลรูปภาพ AI ที่ล้ำสมัยในปัจจุบันในงานการให้เหตุผลด้วยภาพอย่างง่าย ผลการวิจัยยังน่าประหลาดใจ แม้แต่ความแม่นยำของโมเดลหลายรูปแบบชั้นนำอย่าง GPT-4o ก็ต่ำกว่าที่คาดไว้มาก ซึ่งก่อให้เกิดการสะท้อนอย่างลึกซึ้งต่อมาตรฐานการประเมินความสามารถด้านการมองเห็นของ AI ที่มีอยู่
งานวิจัยล่าสุดจากมหาวิทยาลัยเทคนิคดาร์มสตัดท์ในเยอรมนีเผยให้เห็นปรากฏการณ์ที่กระตุ้นความคิด แม้แต่โมเดลรูปภาพ AI ที่ทันสมัยที่สุดก็สามารถสร้างข้อผิดพลาดที่สำคัญได้เมื่อต้องเผชิญกับงานการให้เหตุผลด้วยภาพง่ายๆ ผลการวิจัยนี้ทำให้เกิดแนวคิดใหม่เกี่ยวกับมาตรฐานการประเมินความสามารถด้านการมองเห็นของ AI
ทีมวิจัยใช้ปัญหาบองการ์ดที่ออกแบบโดยนักวิทยาศาสตร์ชาวรัสเซีย มิคาอิล บองการ์ด เป็นเครื่องมือทดสอบ ภาพปริศนาประเภทนี้ประกอบด้วยภาพง่ายๆ 12 ภาพ แบ่งออกเป็นสองกลุ่ม และต้องระบุกฎเกณฑ์ที่แยกทั้งสองกลุ่มออกจากกัน งานการให้เหตุผลเชิงนามธรรมนี้ไม่ใช่เรื่องยากสำหรับคนส่วนใหญ่ แต่ประสิทธิภาพของโมเดล AI นั้นน่าประหลาดใจ
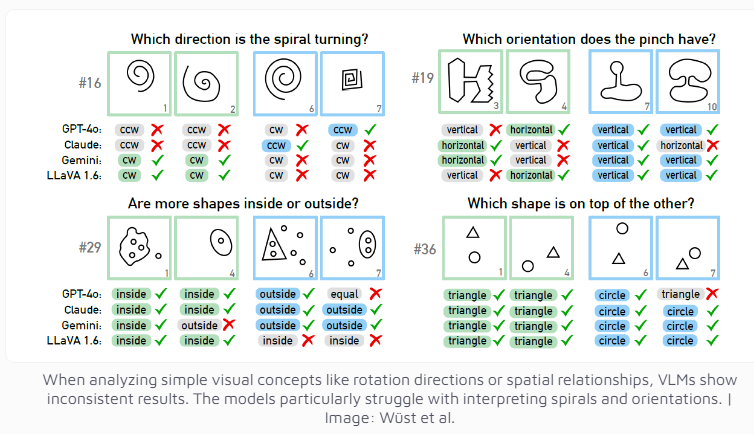
แม้แต่รุ่น multi-modal GPT-4o ซึ่งปัจจุบันถือว่าล้ำหน้าที่สุด ก็ไขปริศนาภาพได้เพียง 21 จาก 100 ชิ้นเท่านั้น ประสิทธิภาพของโมเดล AI ที่มีชื่อเสียงอื่นๆ เช่น Claude, Gemini และ LLaVA ยังน่าพอใจน้อยลงอีกด้วย แบบจำลองเหล่านี้แสดงความยากลำบากอย่างมากในการระบุแนวคิดการมองเห็นขั้นพื้นฐาน เช่น เส้นแนวตั้งและแนวนอน หรือการตัดสินทิศทางของเกลียว
นักวิจัยพบว่าแม้จะมีหลายตัวเลือก แต่ประสิทธิภาพของโมเดล AI ก็ดีขึ้นเพียงเล็กน้อยเท่านั้น ภายใต้ข้อจำกัดที่เข้มงวดเกี่ยวกับจำนวนคำตอบที่เป็นไปได้ GPT-4 และ Claude จึงปรับปรุงอัตราความสำเร็จเป็น 68 และ 69 ปริศนาตามลำดับ จากการวิเคราะห์เชิงลึกของกรณีเฉพาะทั้ง 4 กรณี ทีมวิจัยพบว่าบางครั้งระบบ AI อาจมีปัญหาในระดับการรับรู้ภาพขั้นพื้นฐานก่อนที่จะถึงขั้นการคิดและการให้เหตุผล แต่เหตุผลเฉพาะเจาะจงยังยากที่จะระบุได้
งานวิจัยนี้ยังกระตุ้นให้เกิดการพิจารณาเกณฑ์การประเมินของระบบ AI อีกด้วย ทีมวิจัยชี้ให้เห็นว่า: เหตุใดโมเดลภาษาภาพจึงทำงานได้ดีกับเกณฑ์มาตรฐานที่กำหนดไว้แต่ต้องต่อสู้กับปัญหา Bongard ที่ดูเหมือนง่ายเพียงใด เกณฑ์มาตรฐานเหล่านี้มีความหมายเพียงใดในการประเมินความสามารถในการให้เหตุผลในโลกแห่งความเป็นจริง อาจจำเป็นต้องได้รับการออกแบบใหม่เพื่อวัดความสามารถในการให้เหตุผลเชิงภาพของ AI ได้แม่นยำยิ่งขึ้น
งานวิจัยนี้ไม่เพียงแต่แสดงให้เห็นถึงข้อจำกัดของเทคโนโลยี AI ในปัจจุบันเท่านั้น แต่ยังชี้ทางสำหรับการพัฒนาความสามารถด้านการมองเห็นของ AI ในอนาคตอีกด้วย มันเตือนเราว่าในขณะที่เราเชียร์ความก้าวหน้าอย่างรวดเร็วของ AI เราต้องตระหนักอย่างชัดเจนด้วยว่ายังมีพื้นที่สำหรับการปรับปรุงความสามารถการรับรู้ขั้นพื้นฐานของ AI
การวิจัยนี้แสดงให้เห็นอย่างชัดเจนว่าโมเดล AI ยังมีพื้นที่อีกมากสำหรับการปรับปรุงการใช้เหตุผลด้วยภาพ และจำเป็นต้องมีวิธีการประเมินที่มีประสิทธิภาพมากขึ้นและการพัฒนาทางเทคโนโลยีในอนาคต เพื่อปรับปรุงความสามารถด้านการรับรู้ของ AI บรรณาธิการของ Downcodes จะยังคงให้ความสนใจกับความก้าวหน้าอันล้ำหน้าในด้าน AI และนำเสนอรายงานที่น่าตื่นเต้นอีกมากมายให้กับคุณ