โมเดลภาษาขนาดใหญ่ (LLM) มีการใช้กันอย่างแพร่หลายมากขึ้น แต่พารามิเตอร์จำนวนมากทำให้เกิดความต้องการทรัพยากรการประมวลผลจำนวนมหาศาล เพื่อที่จะแก้ไขปัญหานี้และปรับปรุงประสิทธิภาพและความแม่นยำของแบบจำลองในสภาพแวดล้อมทรัพยากรที่แตกต่างกัน นักวิจัยยังคงสำรวจวิธีการใหม่ ๆ ต่อไป บทความนี้จะแนะนำเฟรมเวิร์ก Flextron ที่พัฒนาร่วมกันโดยนักวิจัยจาก NVIDIA และมหาวิทยาลัยเท็กซัสที่ออสติน เฟรมเวิร์กนี้ได้รับการออกแบบมาเพื่อให้ใช้งานโมเดล AI ได้อย่างยืดหยุ่น โดยไม่ต้องปรับแต่งเพิ่มเติม และแก้ไขปัญหาความไร้ประสิทธิภาพของวิธีการแบบเดิมได้อย่างมีประสิทธิภาพ บรรณาธิการของ Downcodes จะอธิบายรายละเอียดเกี่ยวกับนวัตกรรมของเฟรมเวิร์ก Flextron และข้อดีของมันในสภาพแวดล้อมที่มีทรัพยากรจำกัด
ในด้านปัญญาประดิษฐ์ โมเดลภาษาขนาดใหญ่ (LLM) เช่น GPT-3 และ Llama-2 มีความก้าวหน้าอย่างมาก และสามารถเข้าใจและสร้างภาษามนุษย์ได้อย่างแม่นยำ อย่างไรก็ตาม พารามิเตอร์จำนวนมากของโมเดลเหล่านี้ทำให้ต้องใช้ทรัพยากรการประมวลผลจำนวนมากในระหว่างการฝึกอบรมและการปรับใช้ ซึ่งก่อให้เกิดความท้าทายในสภาพแวดล้อมที่มีทรัพยากรจำกัด
ทางเข้ากระดาษ: https://arxiv.org/html/2406.10260v1
โดยปกติแล้ว เพื่อให้บรรลุความสมดุลระหว่างประสิทธิภาพและความแม่นยำภายใต้ข้อจำกัดด้านทรัพยากรการประมวลผลที่แตกต่างกัน นักวิจัยจำเป็นต้องฝึกอบรมแบบจำลองหลายเวอร์ชัน ตัวอย่างเช่น ตระกูลโมเดล Llama-2 มีตัวแปรที่แตกต่างกันด้วยพารามิเตอร์ 7 พันล้าน, 1.3 พันล้าน และ 700 ล้าน อย่างไรก็ตาม วิธีการนี้ต้องใช้ข้อมูลและทรัพยากรการประมวลผลจำนวนมากและไม่มีประสิทธิภาพมากนัก
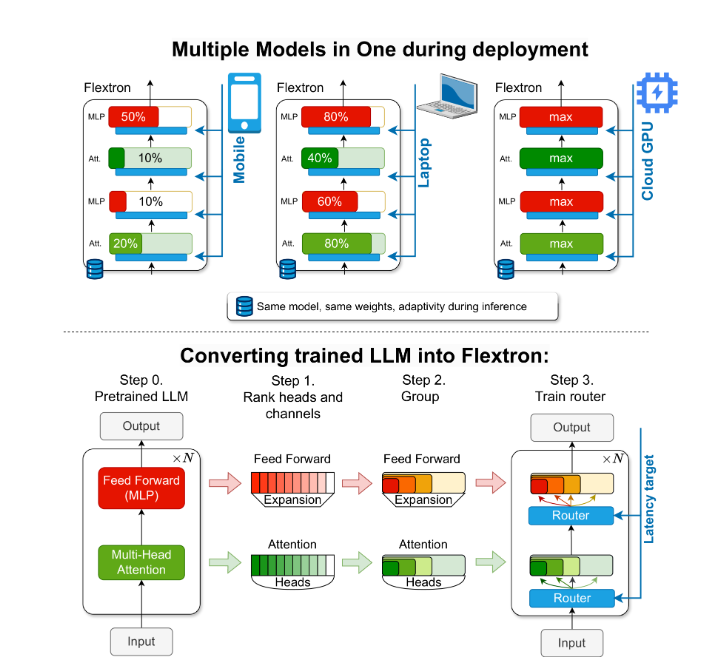
เพื่อแก้ปัญหานี้ นักวิจัยจาก NVIDIA และมหาวิทยาลัยเท็กซัสที่ออสตินได้แนะนำเฟรมเวิร์ก Flextron Flextron เป็นสถาปัตยกรรมโมเดลใหม่ที่มีความยืดหยุ่นและเฟรมเวิร์กการเพิ่มประสิทธิภาพหลังการฝึกอบรม ซึ่งรองรับการปรับใช้โมเดลแบบปรับเปลี่ยนได้ โดยไม่จำเป็นต้องปรับแต่งเพิ่มเติม จึงช่วยแก้ปัญหาความไร้ประสิทธิภาพของวิธีการแบบเดิมได้
Flextron แปลง LLM ที่ได้รับการฝึกล่วงหน้าให้เป็นโมเดลแบบยืดหยุ่นผ่านวิธีการฝึกอบรมที่มีประสิทธิภาพตามตัวอย่างและอัลกอริธึมการกำหนดเส้นทางขั้นสูง โครงสร้างนี้มีการออกแบบยืดหยุ่นแบบซ้อนซึ่งช่วยให้สามารถปรับแบบไดนามิกระหว่างการอนุมานเพื่อให้บรรลุเป้าหมายเวลาแฝงและความแม่นยำที่เฉพาะเจาะจง ความสามารถในการปรับตัวนี้ทำให้สามารถใช้โมเดลที่ได้รับการฝึกอบรมล่วงหน้าเพียงตัวเดียวในสถานการณ์การใช้งานที่หลากหลาย ซึ่งช่วยลดความจำเป็นในการใช้โมเดลหลายแบบได้อย่างมาก
การประเมินประสิทธิภาพของ Flextron แสดงให้เห็นว่ามีประสิทธิภาพเหนือกว่าในด้านประสิทธิภาพและความแม่นยำ เมื่อเทียบกับโมเดลที่ผ่านการฝึกอบรมแบบ end-to-end หลายรุ่นและเครือข่ายยืดหยุ่นที่ล้ำสมัยอื่นๆ ตัวอย่างเช่น Flextron ทำงานได้ดีบนเกณฑ์มาตรฐานต่างๆ เช่น ARC-easy, LAMBADA, PIQA, WinoGrande, MMLU และ HellaSwag โดยใช้เพียง 7.63% ของเครื่องหมายการฝึกอบรมในการฝึกอบรมล่วงหน้าแบบเดิม จึงช่วยประหยัดทรัพยากรและเวลาในการประมวลผลได้มาก .
กรอบงาน Flextron ยังรวมถึงชั้น Perceptron หลายชั้นแบบยืดหยุ่น (MLP) และชั้น Elastic Multi-Head Attention (MHA) ซึ่งช่วยเพิ่มความสามารถในการปรับตัวให้ดียิ่งขึ้น เลเยอร์ MHA แบบยืดหยุ่นใช้หน่วยความจำและพลังการประมวลผลที่มีอยู่อย่างมีประสิทธิภาพโดยการเลือกชุดย่อยของส่วนหัวความสนใจตามข้อมูลอินพุต และเหมาะอย่างยิ่งสำหรับสถานการณ์ที่มีทรัพยากรการประมวลผลจำกัด
ไฮไลท์:
? กรอบงาน Flextron รองรับการใช้งานโมเดล AI ที่ยืดหยุ่นโดยไม่ต้องปรับแต่งเพิ่มเติม
ด้วยการฝึกอบรมตัวอย่างที่มีประสิทธิภาพและอัลกอริธึมการกำหนดเส้นทางขั้นสูง ทำให้ประสิทธิภาพและความแม่นยำของโมเดลได้รับการปรับปรุง
ชั้นความสนใจแบบหลายหัวที่ยืดหยุ่นช่วยเพิ่มประสิทธิภาพการใช้ทรัพยากร และเหมาะอย่างยิ่งสำหรับสภาพแวดล้อมที่มีทรัพยากรการประมวลผลจำกัด
รายงานนี้หวังที่จะแนะนำความสำคัญและนวัตกรรมของกรอบการทำงาน Flextron ให้กับนักเรียนมัธยมปลายในลักษณะที่เข้าใจง่าย
โดยรวมแล้ว กรอบงาน Flextron มอบโซลูชันที่มีประสิทธิภาพและเป็นนวัตกรรมสำหรับปัญหาการปรับใช้โมเดลภาษาขนาดใหญ่ในสภาพแวดล้อมที่จำกัดทรัพยากร สถาปัตยกรรมที่ยืดหยุ่นและวิธีการฝึกอบรมที่มีประสิทธิภาพตามตัวอย่างทำให้มีข้อได้เปรียบที่สำคัญในการใช้งานจริง และเป็นแนวทางใหม่สำหรับการพัฒนาเทคโนโลยีปัญญาประดิษฐ์เพิ่มเติม บรรณาธิการของ Downcodes หวังว่าบทความนี้จะช่วยให้ทุกคนเข้าใจแนวคิดหลักและการสนับสนุนทางเทคนิคของกรอบงาน Flextron ได้ดีขึ้น