บรรณาธิการของ Downcodes จะพาคุณไปเรียนรู้เกี่ยวกับเทคโนโลยีที่เป็นนวัตกรรมที่ปรับปรุงประสิทธิภาพของโมเดลภาษาขนาดใหญ่ (LLM) - Q-Sparse ความสามารถในการประมวลผลภาษาธรรมชาติอันทรงพลังของ LLM ดึงดูดความสนใจเป็นอย่างมาก แต่ต้นทุนในการคำนวณที่สูงและขนาดหน่วยความจำมักเป็นปัญหาคอขวดในการใช้งานจริง Q-Sparse ใช้วิธีการกระจายข้อมูลที่ชาญฉลาดเพื่อปรับปรุงประสิทธิภาพการอนุมานอย่างมีนัยสำคัญ ขณะเดียวกันก็รับประกันประสิทธิภาพของโมเดล ซึ่งปูทางไปสู่การประยุกต์ใช้ LLM อย่างแพร่หลาย บทความนี้จะสำรวจเทคโนโลยีหลัก ข้อดี และผลการตรวจสอบเชิงทดลองของ Q-Sparse อย่างลึกซึ้ง ซึ่งแสดงให้เห็นถึงศักยภาพมหาศาลในการปรับปรุงประสิทธิภาพของ LLM
ในโลกของปัญญาประดิษฐ์ โมเดลภาษาขนาดใหญ่ (LLM) ขึ้นชื่อในด้านความสามารถในการประมวลผลภาษาธรรมชาติที่เหนือกว่า อย่างไรก็ตาม การใช้งานโมเดลเหล่านี้ในการใช้งานจริงต้องเผชิญกับความท้าทายอย่างมาก สาเหตุหลักมาจากต้นทุนการคำนวณที่สูงและขนาดหน่วยความจำในระหว่างขั้นตอนการอนุมาน เพื่อแก้ปัญหานี้ นักวิจัยได้สำรวจวิธีปรับปรุงประสิทธิภาพของ LLM เมื่อเร็ว ๆ นี้วิธีการที่เรียกว่า Q-Sparse ได้รับความสนใจอย่างกว้างขวาง
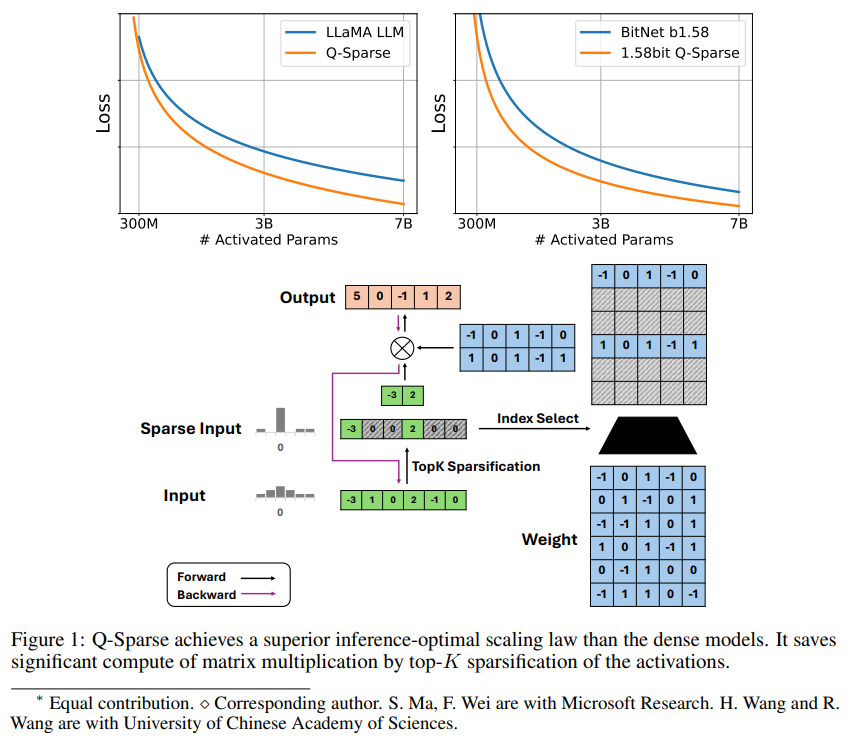
Q-Sparse เป็นวิธีการที่เรียบง่ายแต่มีประสิทธิภาพซึ่งสามารถเปิดใช้งาน LLM แบบกระจัดกระจายโดยการใช้การกระจายตัวแบบ top-K ในการเปิดใช้งานและตัวประมาณค่าการส่งผ่านในการฝึกอบรม ซึ่งหมายถึงการปรับปรุงประสิทธิภาพอย่างมีนัยสำคัญเมื่ออนุมาน ผลการวิจัยที่สำคัญ ได้แก่ :
Q-Sparse บรรลุประสิทธิภาพการอนุมานที่สูงขึ้น ขณะเดียวกันก็รักษาผลลัพธ์ที่เทียบเคียงได้กับ LLM พื้นฐาน
มีการเสนอกฎการขยายที่เหมาะสมที่สุดเชิงอนุมานที่เหมาะสมสำหรับ LLM การเปิดใช้งานแบบกระจาย
Q-Sparse ทำงานในการตั้งค่าที่แตกต่างกัน รวมถึงการฝึกอบรมตั้งแต่เริ่มต้น การฝึกอบรม LLM นอกชั้นวางอย่างต่อเนื่อง และการปรับแต่งอย่างละเอียด
Q-Sparse ทำงานด้วยความแม่นยำเต็มรูปแบบและ LLM 1 บิต (เช่น BitNet b1.58)
ข้อดีของการเปิดใช้งานแบบเบาบาง
ความกระจัดกระจายช่วยปรับปรุงประสิทธิภาพของ LLM ในสองวิธี ประการแรก ความกระจัดกระจายสามารถลดจำนวนการคำนวณการคูณเมทริกซ์ เนื่องจากองค์ประกอบที่เป็นศูนย์จะไม่ได้รับการคำนวณ ประการที่สอง ความกระจัดกระจายสามารถลดปริมาณการส่งอินพุต/เอาท์พุต (I/O) ซึ่ง มันเป็นปัญหาคอขวดหลักในขั้นตอนการอนุมานของ LLM
Q-Sparse บรรลุการเปิดใช้งานแบบกระจัดกระจายเต็มรูปแบบโดยการใช้ฟังก์ชันการกระจายตัวแบบ top-K ในการฉายภาพเชิงเส้นแต่ละครั้ง สำหรับการขยายพันธุ์กลับ การไล่ระดับสีของการกระตุ้นจะถูกคำนวณโดยใช้ตัวประมาณค่าการส่งผ่าน นอกจากนี้ ยังมีการนำฟังก์ชัน Squared ReLU มาใช้เพื่อปรับปรุงความกระจัดกระจายของการเปิดใช้งานให้ดียิ่งขึ้น
การตรวจสอบการทดลอง
นักวิจัยได้ศึกษากฎการขยายตัวของ LLM ที่เปิดใช้งานอย่างกระจัดกระจายผ่านการทดลองการขยายตัวหลายชุด และได้ข้อค้นพบที่น่าสนใจบางประการ:
ประสิทธิภาพของแบบจำลองการเปิดใช้งานแบบกระจายจะดีขึ้นด้วยการเพิ่มขนาดแบบจำลองและอัตราส่วนการกระจายตัว
เมื่อพิจารณาอัตราส่วนความกระจัดกระจายคงที่ S ประสิทธิภาพของแบบจำลองการเปิดใช้งานแบบกระจัดกระจายจะปรับขนาดด้วยขนาดแบบจำลอง N ในลักษณะของกฎกำลัง
เมื่อกำหนดพารามิเตอร์คงที่ N ประสิทธิภาพของแบบจำลองการเปิดใช้งานแบบกระจายจะปรับขนาดแบบเอกซ์โปเนนเชียลด้วยอัตราส่วนสปาร์ซิตี้ S
Q-Sparse สามารถใช้ได้ไม่เพียงแต่สำหรับการฝึกอบรมตั้งแต่เริ่มต้นเท่านั้น แต่ยังใช้สำหรับการฝึกอบรมอย่างต่อเนื่องและการปรับแต่ง LLM ที่มีจำหน่ายทั่วไปอย่างละเอียดอีกด้วย ในการฝึกอบรมต่อเนื่องและการตั้งค่าการปรับแต่งอย่างละเอียด นักวิจัยใช้สถาปัตยกรรมและกระบวนการฝึกอบรมเดียวกันกับการฝึกอบรมตั้งแต่เริ่มต้น ข้อแตกต่างเพียงอย่างเดียวคือการเริ่มต้นโมเดลด้วยตุ้มน้ำหนักที่ได้รับการฝึกอบรมไว้ล่วงหน้า และเปิดใช้งานฟังก์ชันแบบเบาบางเพื่อดำเนินการฝึกอบรมต่อไป
นักวิจัยกำลังสำรวจการใช้ Q-Sparse กับ LLM 1 บิต (เช่น BitNet b1.58) และผู้เชี่ยวชาญแบบผสม (MoE) เพื่อปรับปรุงประสิทธิภาพของ LLM ต่อไป นอกจากนี้ พวกเขากำลังดำเนินการเพื่อทำให้ Q-Sparse เข้ากันได้กับโหมดแบทช์ ซึ่งจะให้ความยืดหยุ่นมากขึ้นสำหรับการฝึกอบรมและการอนุมาน LLM
การเกิดขึ้นของเทคโนโลยี Q-Sparse ให้แนวคิดใหม่ในการแก้ปัญหาประสิทธิภาพของ LLM มีศักยภาพในการลดต้นทุนการประมวลผลและการใช้หน่วยความจำ และคาดว่าจะส่งเสริมการประยุกต์ใช้ LLM ในสาขาอื่นๆ มากขึ้น เป็นที่เชื่อกันว่าผลการวิจัยเพิ่มเติมเกี่ยวกับ Q-Sparse จะเกิดขึ้นในอนาคต เพื่อปรับปรุงประสิทธิภาพและประสิทธิภาพของ LLM ต่อไป