บรรณาธิการของ Downcodes ได้เรียนรู้ว่า Alibaba Cloud ได้เปิดตัวโมเดลภาษาเสียงขนาดใหญ่ใหม่ Qwen2-Audio ซึ่งสร้างความก้าวหน้าครั้งสำคัญในด้านการโต้ตอบด้วยเสียง สามารถรับอินพุตสัญญาณเสียงได้หลากหลายและทำการวิเคราะห์เสียงหรือตอบคำสั่งเสียงโดยตรง ซึ่งช่วยปรับปรุงประสบการณ์ผู้ใช้อย่างมาก เมื่อเปรียบเทียบกับ Qwen-Audio รุ่นก่อนหน้า Qwen2-Audio แสดงให้เห็นประสิทธิภาพที่ทรงพลังกว่าในการติดตามคำสั่ง และก้าวขึ้นเป็นผู้นำในการทดสอบเกณฑ์มาตรฐานหลายรายการ นี่ถือเป็นอีกก้าวที่มั่นคงของ Alibaba Cloud ในด้านปัญญาประดิษฐ์ โดยนำเทคโนโลยีการโต้ตอบด้วยเสียงขั้นสูงและสะดวกสบายมาสู่ผู้ใช้
เมื่อเร็วๆ นี้ Alibaba Cloud ได้เปิดตัวโมเดลภาษาเสียงขนาดใหญ่ที่เรียกว่า Qwen-Audio โมเดลนี้สามารถรับอินพุตสัญญาณเสียงได้หลากหลาย และสามารถทำการวิเคราะห์เสียงหรือตอบคำสั่งเสียงได้โดยตรง ซึ่งช่วยปรับปรุงประสบการณ์การโต้ตอบด้วยเสียงได้อย่างมาก
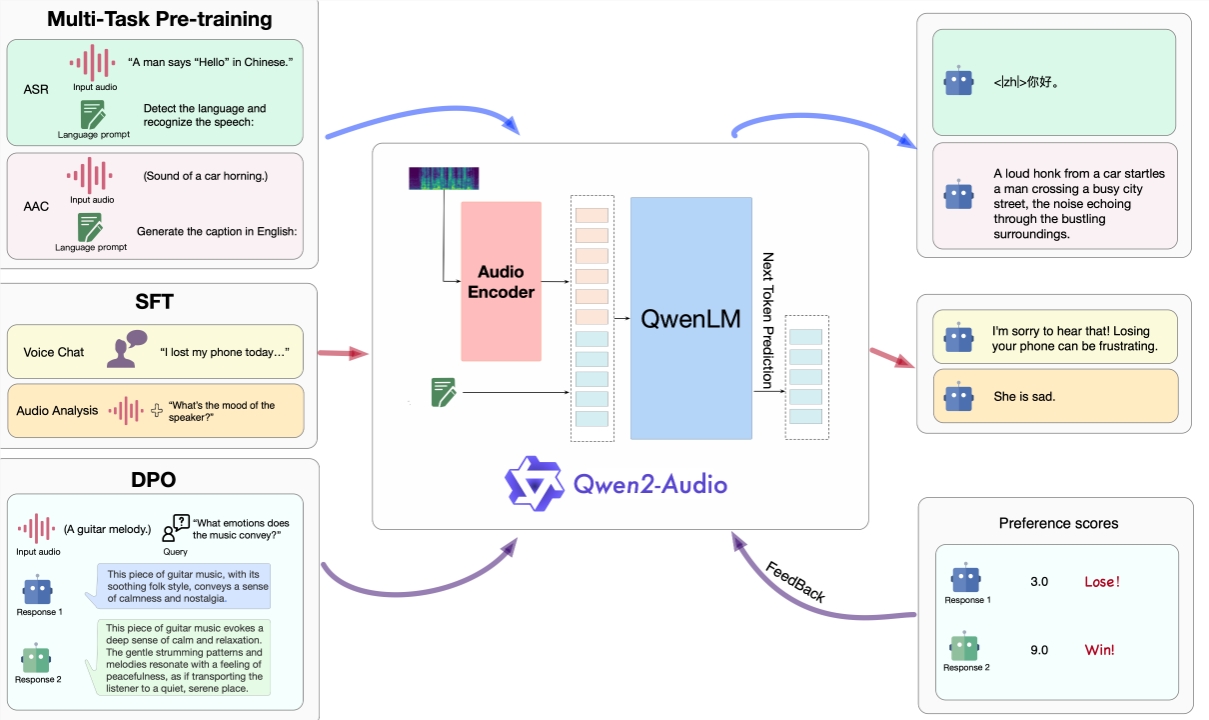
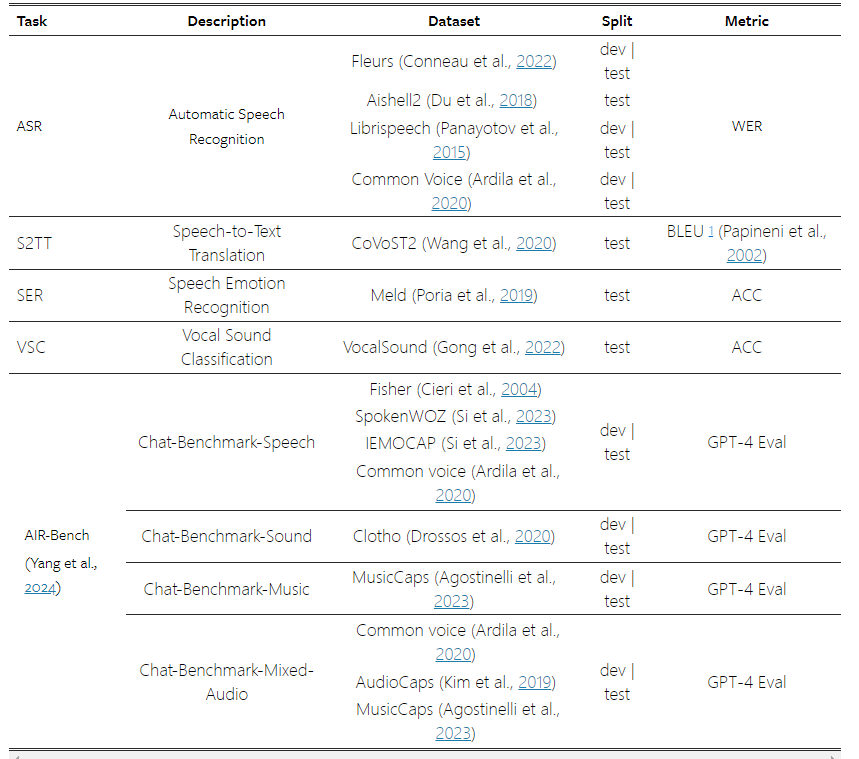
ในแง่ของความสามารถในการแชทของ Qwen2-Audio นักวิจัยได้วัดประสิทธิภาพบนเกณฑ์มาตรฐานการแชท AIR-Bench (Yang et al., 2024) Qwen2-Audio แสดงให้เห็นถึงประสิทธิภาพที่ล้ำสมัยทั้งในด้านคำพูด เสียงเพลง และเสียงผสม ฟังก์ชั่นการติดตามคำสั่งย่อย (SOTA) แสดงให้เห็นถึงการปรับปรุงที่สำคัญเมื่อเทียบกับ Qwen-Audio และเหนือกว่า LALM อื่นๆ อย่างมาก
ไฮไลท์:
Alibaba Cloud เปิดตัว Qwen2-Audio โมเดลภาษาความถี่ขนาดใหญ่ที่เป็นนวัตกรรมใหม่ที่ปรับปรุงประสบการณ์การโต้ตอบด้วยเสียง
Qwen2-Audio สามารถรับอินพุตสัญญาณเสียงที่หลากหลายสำหรับการวิเคราะห์เสียงหรือตอบคำสั่งเสียงโดยตรง ซึ่งขยายฟังก์ชันการโต้ตอบด้วยเสียงได้อย่างมาก
ด้วยกระบวนการฝึกอบรมสามขั้นตอน วิธีการฝึกอบรมโครงสร้างโมเดลและประสิทธิภาพของ Qwen2-Audio ได้รับการสาธิตอย่างเต็มที่ ทำให้ผู้ใช้ได้รับประสบการณ์การโต้ตอบทางเสียงที่ดียิ่งขึ้น
โดยสรุปแล้ว การเกิดขึ้นของ Qwen2-Audio นำมาซึ่งความเป็นไปได้ใหม่ๆ ให้กับเทคโนโลยีการโต้ตอบด้วยเสียง และประสิทธิภาพอันทรงพลังและความคล่องตัวของ Qwen2-Audio ทำให้มีโอกาสในวงกว้างในการใช้งานในอนาคต บรรณาธิการของ Downcodes จะยังคงให้ความสนใจกับความก้าวหน้าล่าสุดของ Alibaba Cloud ในด้านปัญญาประดิษฐ์ และนำเสนอรายงานที่น่าตื่นเต้นอีกมากมายแก่ผู้อ่าน