ในช่วงไม่กี่ปีที่ผ่านมา โมเดลขนาดใหญ่หลายรูปแบบได้พัฒนาอย่างรวดเร็ว และมีโมเดลที่ยอดเยี่ยมมากมายเกิดขึ้น อย่างไรก็ตาม โมเดลที่มีอยู่ส่วนใหญ่อาศัยตัวเข้ารหัสภาพ ซึ่งประสบปัญหาอคติในการเหนี่ยวนำด้วยภาพซึ่งเกิดจากการแยกการฝึก การจำกัดประสิทธิภาพและประสิทธิภาพ บรรณาธิการของ Downcodes นำเสนอโมเดลภาษาภาพใหม่ EVE ที่เปิดตัวโดย Zhiyuan Research Institute ร่วมกับมหาวิทยาลัย โดยใช้สถาปัตยกรรมแบบไม่ใช้โค้ดเดอร์และได้ผลลัพธ์ที่ยอดเยี่ยมในการทดสอบเกณฑ์มาตรฐานหลายรายการ ซึ่งมอบโอกาสใหม่ ๆ ในการพัฒนาโมเดลหลายรูปแบบ . ความคิด
เมื่อเร็ว ๆ นี้ มีความก้าวหน้าที่สำคัญในการวิจัยและการประยุกต์ใช้แบบจำลองขนาดใหญ่หลายรูปแบบ บริษัทต่างชาติ เช่น OpenAI, Google, Microsoft ฯลฯ ได้เปิดตัวโมเดลขั้นสูงหลายรุ่น และสถาบันในประเทศ เช่น Zhipu AI และ Step Star ก็ได้สร้างความก้าวหน้าในสาขานี้ โมเดลเหล่านี้มักจะอาศัยตัวเข้ารหัสภาพเพื่อแยกคุณสมบัติด้านภาพและรวมเข้ากับโมเดลภาษาขนาดใหญ่ แต่มีปัญหาอคติในการเหนี่ยวนำด้วยภาพที่เกิดจากการแยกการฝึกอบรม ซึ่งจะจำกัดประสิทธิภาพการใช้งานและประสิทธิภาพของโมเดลขนาดใหญ่แบบหลายโมดัล
เพื่อแก้ไขปัญหาเหล่านี้ สถาบันวิจัย Zhiyuan ร่วมกับมหาวิทยาลัยเทคโนโลยีต้าเหลียน มหาวิทยาลัยปักกิ่ง และมหาวิทยาลัยอื่นๆ ได้เปิดตัวโมเดลภาษาภาพรุ่นใหม่ EVE ที่ไม่ต้องใช้โค้ดเดอร์ EVE ผสมผสานการแสดงภาพและภาษา การจัดตำแหน่ง และการอนุมานในสถาปัตยกรรมถอดรหัสบริสุทธิ์แบบครบวงจรผ่านกลยุทธ์การฝึกอบรมที่ได้รับการปรับปรุงและการควบคุมดูแลด้วยภาพเพิ่มเติม การใช้ข้อมูลสาธารณะ EVE ทำงานได้ดีกับเกณฑ์มาตรฐานเชิงภาพและภาษาที่หลากหลาย โดยเข้าใกล้หรือมีประสิทธิภาพเหนือกว่าวิธีหลายรูปแบบที่ใช้ตัวเข้ารหัสกระแสหลัก
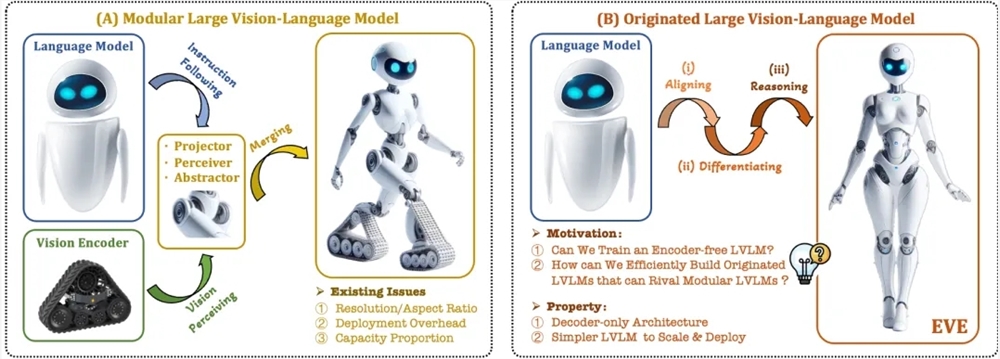
คุณสมบัติที่สำคัญของ EVE ได้แก่ :
โมเดลภาษาภาพพื้นเมือง: ลบตัวเข้ารหัสภาพและจัดการอัตราส่วนภาพใดๆ ซึ่งดีกว่ารุ่น Fuyu-8B ประเภทเดียวกันอย่างเห็นได้ชัด
ข้อมูลและต้นทุนการฝึกอบรมต่ำ: การฝึกอบรมก่อนการฝึกอบรมใช้ข้อมูลสาธารณะ เช่น OpenImages, SAM และ LAION และระยะเวลาการฝึกอบรมสั้น
การสำรวจที่โปร่งใสและมีประสิทธิภาพ: มอบเส้นทางการพัฒนาที่มีประสิทธิภาพและโปร่งใสสำหรับสถาปัตยกรรมแบบหลายโมดัลดั้งเดิมของตัวถอดรหัสล้วนๆ
โครงสร้างโมเดล:
Patch Embedding Layer: รับแผนผังคุณลักษณะ 2D ของรูปภาพผ่านเลเยอร์ Convolution เดียวและเลเยอร์การรวมกลุ่มโดยเฉลี่ยเพื่อปรับปรุงคุณสมบัติในท้องถิ่นและข้อมูลทั่วโลก
Patch Aligning Layer: ผสานรวมคุณสมบัติภาพเครือข่ายหลายชั้นเพื่อให้ได้การจัดตำแหน่งที่ละเอียดกับเอาต์พุตตัวเข้ารหัสภาพ
กลยุทธ์การฝึกอบรม:
ขั้นตอนก่อนการฝึกอบรมนำโดยแบบจำลองภาษาขนาดใหญ่: สร้างการเชื่อมโยงเบื้องต้นระหว่างวิสัยทัศน์และภาษา
ขั้นตอนก่อนการฝึกอบรมเชิงสร้างสรรค์: ปรับปรุงความสามารถของโมเดลในการทำความเข้าใจเนื้อหาภาพและภาษา
ขั้นตอนการปรับแต่งแบบละเอียดภายใต้การดูแล: ควบคุมความสามารถของโมเดลในการทำตามคำแนะนำภาษาและเรียนรู้รูปแบบการสนทนา
การวิเคราะห์เชิงปริมาณ: EVE ทำงานได้ดีในเกณฑ์มาตรฐานภาษาภาพหลายภาษา และเทียบได้กับโมเดลภาษาภาพที่ใช้โปรแกรมเข้ารหัสกระแสหลักต่างๆ แม้จะมีความท้าทายในการตอบสนองต่อคำสั่งเฉพาะอย่างแม่นยำ แต่ด้วยกลยุทธ์การฝึกอบรมที่มีประสิทธิภาพ EVE ก็สามารถบรรลุประสิทธิภาพที่เทียบเคียงได้กับโมเดลภาษาภาพที่มีฐานตัวเข้ารหัส
EVE ได้แสดงให้เห็นถึงศักยภาพของโมเดลภาษาภาพที่ไม่ใช้ตัวเข้ารหัส ในอนาคต อาจยังคงส่งเสริมการพัฒนาแบบจำลองหลายรูปแบบผ่านการปรับปรุงประสิทธิภาพเพิ่มเติม การเพิ่มประสิทธิภาพของสถาปัตยกรรมที่ไม่ใช้ตัวเข้ารหัส และการสร้าง multi-modal ดั้งเดิม โมเดล
ที่อยู่กระดาษ: https://arxiv.org/abs/2406.11832
รหัสโครงการ: https://github.com/baaivision/EVE
ที่อยู่รุ่น: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
โดยรวมแล้ว การเกิดขึ้นของโมเดล EVE ให้ทิศทางใหม่และความเป็นไปได้ในการพัฒนาโมเดลขนาดใหญ่แบบหลายรูปแบบ กลยุทธ์การฝึกอบรมที่มีประสิทธิภาพและประสิทธิภาพที่ยอดเยี่ยมสมควรได้รับความสนใจ เราหวังเป็นอย่างยิ่งว่าโมเดล EVE ในอนาคตจะสามารถแสดงให้เห็นถึงความสามารถอันทรงพลังในสาขาต่างๆ ได้มากขึ้น