เมื่อเร็วๆ นี้ Tencent Artificial Intelligence Laboratory ได้เปิดตัวโมเดลใหม่ที่เรียกว่า VTA-LDM ซึ่งได้รับการออกแบบมาเพื่อแปลงเนื้อหาวิดีโอให้เป็นเสียงที่สอดคล้องกันทั้งทางความหมายและทางเวลาอย่างมีประสิทธิภาพ เทคโนโลยีหลักของรุ่นนี้อยู่ที่ "การจัดตำแหน่งโดยนัย" ซึ่งตรงกับเนื้อหาเสียงและวิดีโอที่สร้างขึ้นอย่างสมบูรณ์แบบ ซึ่งช่วยปรับปรุงคุณภาพและสถานการณ์การใช้งานของการสร้างเสียงได้อย่างมาก บรรณาธิการของ Downcodes จะพาคุณไปทำความเข้าใจเชิงลึกเกี่ยวกับนวัตกรรมและแนวโน้มการใช้งานของโมเดล VTA-LDM
ด้วยความก้าวหน้าที่สำคัญในเทคโนโลยีการสร้างข้อความเป็นวิดีโอ วิธีสร้างเนื้อหาเสียงที่สอดคล้องกันทั้งทางความหมายและทางเวลาจากอินพุตวิดีโอจึงกลายเป็นประเด็นร้อนในหมู่นักวิจัย เมื่อเร็วๆ นี้ ทีมวิจัยของ Tencent Artificial Intelligence Laboratory ได้เปิดตัวโมเดลใหม่ที่เรียกว่า "Implicitly Aligned Video to Audio Generation" - VTA-LDM ซึ่งมีเป้าหมายเพื่อมอบโซลูชันการสร้างเสียงที่มีประสิทธิภาพ
ทางเข้าโครงการ: https://top.aibase.com/tool/vta-ldm
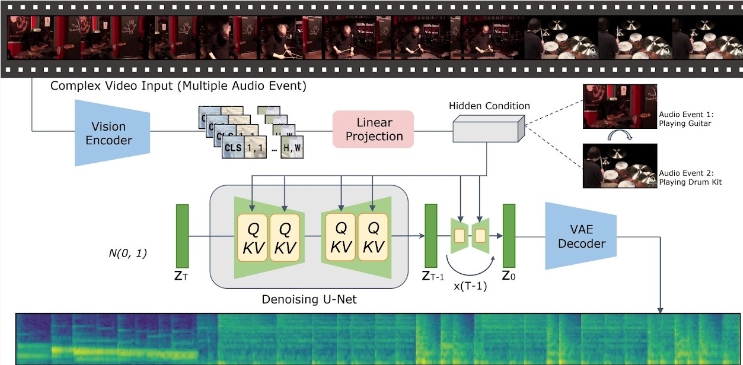
แนวคิดหลักของโมเดล VTA-LDM คือการจับคู่เนื้อหาเสียงและวิดีโอที่สร้างขึ้นทั้งเชิงความหมายและเชิงเวลาผ่านเทคโนโลยีการจัดตำแหน่งโดยนัย วิธีการนี้ไม่เพียงแต่ปรับปรุงคุณภาพของการสร้างเสียงเท่านั้น แต่ยังขยายสถานการณ์การประยุกต์ใช้เทคโนโลยีการสร้างวิดีโออีกด้วย ทีมวิจัยได้ทำการสำรวจเชิงลึกเกี่ยวกับการออกแบบแบบจำลองและผสมผสานวิธีการทางเทคนิคที่หลากหลายเพื่อให้มั่นใจในความแม่นยำและความสม่ำเสมอของเสียงที่สร้างขึ้น
การวิจัยมุ่งเน้นไปที่ประเด็นสำคัญ 3 ประการ ได้แก่ ตัวเข้ารหัสภาพ การฝังเสริม และเทคนิคการเพิ่มข้อมูล ทีมวิจัยได้สร้างแบบจำลองพื้นฐานขึ้นเป็นครั้งแรกและดำเนินการทดลองการระเหยจำนวนมากบนพื้นฐานนี้ เพื่อประเมินผลกระทบของเครื่องเข้ารหัสภาพและการฝังเสริมต่างๆ ที่มีต่อผลกระทบของการสร้าง ผลการทดลองเหล่านี้แสดงให้เห็นว่าโมเดลดังกล่าวทำงานได้ดีในแง่ของคุณภาพการสร้างและการจัดตำแหน่งวิดีโอและเสียงไปพร้อมๆ กัน ซึ่งก้าวไปสู่แถวหน้าของเทคโนโลยีปัจจุบัน
ในแง่ของการอนุมาน ผู้ใช้เพียงแค่ใส่คลิปวิดีโอลงในไดเร็กทอรีข้อมูลที่ระบุ และเรียกใช้สคริปต์การอนุมานที่ให้มาเพื่อสร้างเนื้อหาเสียงที่เกี่ยวข้อง ทีมวิจัยยังมีชุดเครื่องมือเพื่อช่วยให้ผู้ใช้ผสานเสียงที่สร้างขึ้นเข้ากับวิดีโอต้นฉบับ ช่วยเพิ่มความสะดวกสบายให้กับแอปพลิเคชัน
ปัจจุบันโมเดล VTA-LDM มีเวอร์ชันต่างๆ มากมายเพื่อตอบสนองความต้องการด้านการวิจัยที่แตกต่างกัน โมเดลเหล่านี้ครอบคลุมโมเดลพื้นฐานและโมเดลที่ได้รับการปรับปรุงหลากหลาย โดยมีเป้าหมายเพื่อให้ผู้ใช้มีตัวเลือกที่ยืดหยุ่นในการปรับให้เข้ากับการทดลองและสถานการณ์การใช้งานต่างๆ
การเปิดตัวโมเดล VTA-LDM ถือเป็นความก้าวหน้าที่สำคัญในด้านการสร้างวิดีโอสู่เสียง นักวิจัยหวังว่าจะใช้โมเดลนี้เพื่อส่งเสริมการพัฒนาเทคโนโลยีที่เกี่ยวข้อง และสร้างความเป็นไปได้ในการใช้งานที่สมบูรณ์ยิ่งขึ้น
## ไฮไลท์:
การเกิดขึ้นของรุ่น VTA-LDM ได้นำมาซึ่งความก้าวหน้าครั้งใหม่ในด้านการสร้างวิดีโอและเสียง วิธีการใช้งานที่มีประสิทธิภาพและสะดวกสบายและฟังก์ชันอันทรงพลังนี้จะช่วยประกาศโอกาสการใช้งานที่กว้างขึ้นในอนาคต เชื่อกันว่าด้วยการพัฒนาเทคโนโลยีอย่างต่อเนื่อง โมเดล VTA-LDM จะมีบทบาทสำคัญในสาขาอื่นๆ มากขึ้น