เครื่องมือแก้ไข Downcodes นำเสนอข่าวใหญ่! เทคโนโลยีเร่งความเร็ว Transformer FlashAttention-3 เปิดตัวอย่างเป็นทางการแล้ว! เทคโนโลยีนี้จะปฏิวัติความเร็วการอนุมานและต้นทุนของโมเดลภาษาขนาดใหญ่ (LLM) ซึ่งบรรลุการปรับปรุงประสิทธิภาพอย่างที่ไม่เคยมีมาก่อน ความเร็วเพิ่มขึ้น 1.5 ถึง 2 เท่า การทำงานที่มีความแม่นยำต่ำ (FP8) จะรักษาความแม่นยำสูง และความสามารถในการประมวลผลข้อความแบบยาวได้รับการปรับปรุงอย่างมาก ซึ่งจะนำความเป็นไปได้ใหม่ๆ มาสู่แอปพลิเคชัน AI! มาดูเทคโนโลยีที่ก้าวล้ำนี้กันดีกว่า
เทคโนโลยีการเร่งความเร็ว Transformer ใหม่ FlashAttention-3 เปิดตัวแล้ว! นี่ไม่ใช่แค่การอัพเกรดเท่านั้น แต่ยังประกาศการเพิ่มขึ้นอย่างรวดเร็วของความเร็วในการอนุมานและต้นทุนที่ลดลงของโมเดลภาษาขนาดใหญ่ (LLM) ของเรา!
มาพูดถึง FlashAttention-3 นี้ก่อน เมื่อเทียบกับเวอร์ชันก่อนหน้า มันเป็นเพียงการเปลี่ยนปืนลูกซอง:
การใช้งาน GPU ได้รับการปรับปรุงอย่างมาก: การใช้ FlashAttention-3 เพื่อฝึกฝนและรันโมเดลภาษาขนาดใหญ่ ความเร็วเพิ่มขึ้นเป็นสองเท่าโดยตรง เร็วขึ้น 1.5 ถึง 2 เท่า ประสิทธิภาพนี้น่าทึ่งมาก
ความแม่นยำต่ำ ประสิทธิภาพสูง: นอกจากนี้ยังสามารถทำงานด้วยตัวเลขความแม่นยำต่ำ (FP8) ในขณะที่ยังคงความแม่นยำไว้ หมายความว่าอย่างไร ต้นทุนที่ลดลงโดยไม่กระทบต่อประสิทธิภาพ!
การประมวลผลข้อความขนาดยาวเป็นเรื่องง่าย: FlashAttention-3 ช่วยเพิ่มความสามารถของโมเดล AI ในการประมวลผลข้อความขนาดยาวซึ่งเมื่อก่อนไม่สามารถจินตนาการได้อย่างมาก
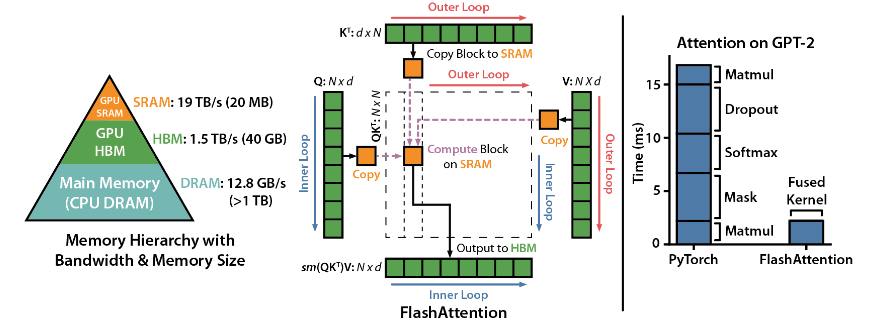
FlashAttention เป็นไลบรารีโอเพ่นซอร์สที่พัฒนาโดย Dao-AILab โดยอิงจากเอกสารฉบับหนาสองฉบับ และมอบการปรับใช้กลไกความสนใจในโมเดลการเรียนรู้เชิงลึกอย่างเหมาะสมที่สุด ไลบรารีนี้เหมาะอย่างยิ่งสำหรับการประมวลผลชุดข้อมูลขนาดใหญ่และลำดับแบบยาว มีความสัมพันธ์เชิงเส้นตรงระหว่างการใช้หน่วยความจำและความยาวของลำดับ ซึ่งมีประสิทธิภาพมากกว่าความสัมพันธ์แบบกำลังสองแบบดั้งเดิมมาก
จุดเด่นทางเทคนิค:
การสนับสนุนด้านเทคโนโลยีขั้นสูง: ความเอาใจใส่ในท้องถิ่น การขยายพันธุ์หลังตามที่กำหนด ALiBi ฯลฯ เทคโนโลยีเหล่านี้นำพลังในการแสดงออกและความยืดหยุ่นของโมเดลไปสู่ระดับที่สูงขึ้น
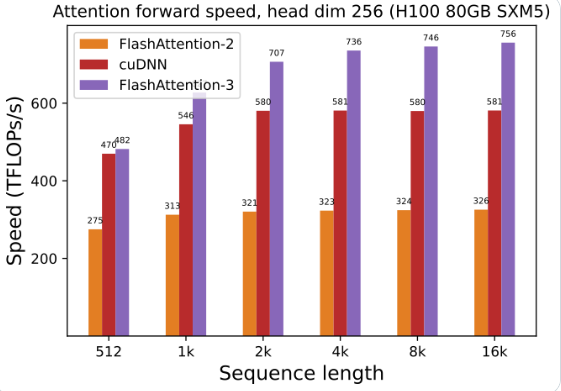
การเพิ่มประสิทธิภาพ Hopper GPU: FlashAttention-3 ได้เพิ่มประสิทธิภาพการรองรับ Hopper GPU เป็นพิเศษ และประสิทธิภาพได้รับการปรับปรุงมากกว่าหนึ่งจุดครึ่ง
ติดตั้งและใช้งานง่าย: รองรับ CUDA11.6 และ PyTorch1.12 หรือสูงกว่า ติดตั้งง่ายด้วยคำสั่ง pip ภายใต้ระบบ Linux แม้ว่าผู้ใช้ Windows อาจต้องการการทดสอบเพิ่มเติม แต่ก็คุ้มค่าที่จะลอง
ฟังก์ชั่นหลัก:
ประสิทธิภาพที่มีประสิทธิภาพ: อัลกอริธึมที่ได้รับการปรับปรุงช่วยลดความต้องการด้านการประมวลผลและหน่วยความจำลงอย่างมาก โดยเฉพาะอย่างยิ่งสำหรับการประมวลผลข้อมูลลำดับยาว และการปรับปรุงประสิทธิภาพสามารถมองเห็นได้ด้วยตาเปล่า
การเพิ่มประสิทธิภาพหน่วยความจำ: เมื่อเทียบกับวิธีการแบบเดิม FlashAttention ใช้หน่วยความจำน้อยกว่า และความสัมพันธ์เชิงเส้นทำให้การใช้หน่วยความจำไม่เป็นปัญหาอีกต่อไป
คุณสมบัติขั้นสูง: การบูรณาการเทคโนโลยีขั้นสูงที่หลากหลายช่วยปรับปรุงประสิทธิภาพของโมเดลและขอบเขตการใช้งานได้อย่างมาก
ใช้งานง่ายและเข้ากันได้: คู่มือการติดตั้งและการใช้งานที่เรียบง่าย ควบคู่ไปกับการรองรับสถาปัตยกรรม GPU หลายตัว ทำให้ FlashAttention-3 สามารถรวมเข้ากับโครงการต่างๆ ได้อย่างรวดเร็ว
ที่อยู่โครงการ: https://github.com/Dao-AILab/flash-attention
การเกิดขึ้นของ FlashAttention-3 จะช่วยเร่งการประยุกต์ใช้และการพัฒนาโมเดลภาษาขนาดใหญ่อย่างไม่ต้องสงสัย และนำความก้าวหน้าใหม่ๆ มาสู่สาขาปัญญาประดิษฐ์ ประสิทธิภาพที่มีประสิทธิภาพและความสะดวกในการใช้งานทำให้เป็นตัวเลือกที่เหมาะสำหรับนักพัฒนา รีบไปสัมผัสมันสิ!