บรรณาธิการของ Downcodes จะเปิดเผยความจริงเกี่ยวกับโมเดลภาษาภาพ (VLM) กับคุณ! คุณคิดว่า VLM สามารถ "เข้าใจ" รูปภาพได้เหมือนมนุษย์หรือไม่ เพราะเหตุใด ความจริงไม่ใช่เรื่องง่าย บทความนี้จะสำรวจข้อจำกัดของ VLM อย่างลึกซึ้งในการทำความเข้าใจเกี่ยวกับภาพ และผ่านชุดผลการทดลอง แสดงให้เห็นถึงช่องว่างขนาดใหญ่ระหว่างสิ่งเหล่านั้นกับความสามารถด้านการมองเห็นของมนุษย์ คุณพร้อมที่จะล้มล้างความเข้าใจเกี่ยวกับ VLM แล้วหรือยัง?
ทุกคนควรเคยได้ยินเกี่ยวกับโมเดลภาษาภาพ (VLM) ผู้เชี่ยวชาญตัวน้อยในสาขา AI ไม่เพียงแต่สามารถอ่านข้อความเท่านั้น แต่ยัง "ดู" รูปภาพได้อีกด้วย แต่กลับไม่เป็นเช่นนั้น วันนี้เรามาดู “กางเกงชั้นใน” ของพวกเขากันดีกว่า เพื่อดูว่าพวกเขาสามารถ “มองเห็น” และเข้าใจภาพเหมือนมนุษย์อย่างเราๆ ได้หรือไม่
ก่อนอื่น ฉันต้องให้ความรู้ทางวิทยาศาสตร์ที่เป็นที่นิยมเกี่ยวกับ VLM คืออะไร พูดง่ายๆ ก็คือโมเดลภาษาขนาดใหญ่ เช่น GPT-4o และ Gemini-1.5Pro ซึ่งทำงานได้ดีมากในการประมวลผลรูปภาพและข้อความ และยังได้คะแนนสูงในการทดสอบความเข้าใจด้วยภาพหลายครั้งอีกด้วย แต่อย่าปล่อยให้คะแนนสูงสุดเหล่านี้หลอกคุณ วันนี้เราจะมาดูกันว่าคะแนนเหล่านั้นยอดเยี่ยมจริง ๆ หรือไม่
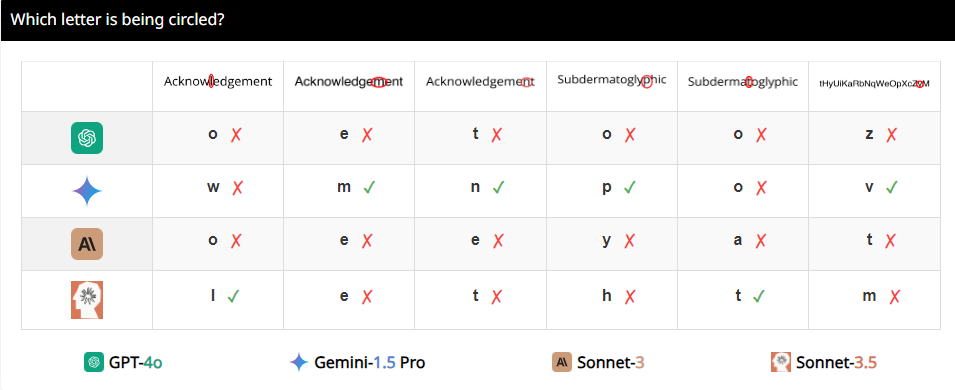
นักวิจัยได้ออกแบบชุดการทดสอบที่เรียกว่า BlindTest ซึ่งประกอบด้วยงาน 7 งานที่ง่ายมากสำหรับมนุษย์ ตัวอย่างเช่น ตรวจสอบว่าวงกลมสองวงทับซ้อนกัน เส้นสองเส้นตัดกัน หรือนับจำนวนวงกลมในโลโก้ Olympic ดูเหมือนเด็กอนุบาลจะจัดการงานเหล่านี้ได้ง่ายไหม แต่ขอบอกเลยว่าประสิทธิภาพของ VLM เหล่านี้ไม่ได้น่าประทับใจขนาดนั้น
ผลลัพธ์ที่ได้น่าตกใจมาก ความแม่นยำโดยเฉลี่ยของโมเดลขั้นสูงเหล่านี้ใน BlindTest อยู่ที่ 56.20% เท่านั้น และ Sonnet-3.5 ที่ดีที่สุดมีความแม่นยำ 73.77% นี่เหมือนกับนักเรียนชั้นนำที่อ้างว่าสามารถเข้ามหาวิทยาลัย Tsinghua และมหาวิทยาลัยปักกิ่งได้ แต่กลับกลายเป็นว่าเขาไม่สามารถทำข้อสอบคณิตศาสตร์ชั้นประถมศึกษาได้อย่างถูกต้องด้วยซ้ำ

เหตุใดจึงเกิดขึ้น นักวิจัยวิเคราะห์ว่าอาจเป็นเพราะ VLM เป็นเหมือนสายตาสั้นเมื่อประมวลผลภาพและไม่สามารถมองเห็นรายละเอียดได้ชัดเจน แม้ว่าพวกเขาจะมองเห็นแนวโน้มโดยรวมของภาพได้คร่าวๆ แต่เมื่อพูดถึงข้อมูลเชิงพื้นที่ที่แม่นยำ เช่น กราฟิกสองตัวตัดกันหรือทับซ้อนกัน พวกเขาก็จะสับสน
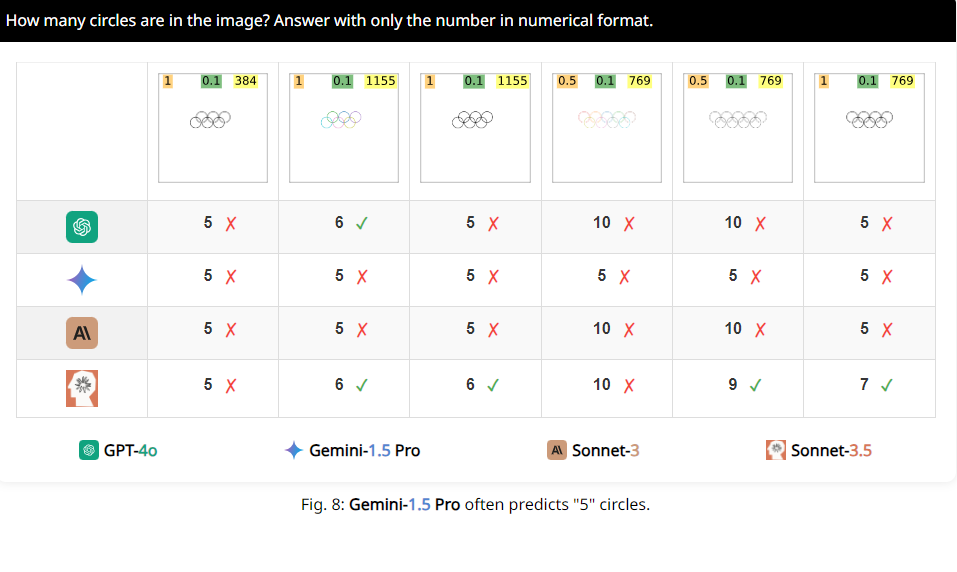
ตัวอย่างเช่น นักวิจัยขอให้ VLM ตรวจสอบว่าวงกลมสองวงทับซ้อนกันหรือไม่ และพบว่าแม้ว่าวงกลมทั้งสองนั้นจะใหญ่เท่ากับแตงโม แต่แบบจำลองเหล่านี้ก็ยังไม่สามารถตอบคำถามได้อย่างแม่นยำ 100% นอกจากนี้ เมื่อถูกขอให้นับจำนวนวงกลมในโลโก้โอลิมปิก ก็ยากที่จะอธิบายประสิทธิภาพของวงกลมเหล่านั้น
สิ่งที่น่าสนใจกว่านั้นคือ นักวิจัยยังพบว่า VLM เหล่านี้ดูเหมือนจะชอบหมายเลข 5 เป็นพิเศษเมื่อทำการนับ ตัวอย่างเช่น เมื่อจำนวนวงกลมในโลโก้ Olympic เกิน 5 วงกลมเหล่านั้นมักจะตอบว่า "5" อาจเป็นเพราะมี 5 วงกลมในโลโก้ Olympic และคุ้นเคยกับตัวเลขนี้เป็นพิเศษ
เอาล่ะ พวกคุณมีความเข้าใจใหม่เกี่ยวกับ VLM ที่ดูเหมือนสูงเหล่านี้แล้วหรือยัง จริงๆ แล้วพวกมันยังมีข้อจำกัดมากมายในการทำความเข้าใจด้วยภาพ ซึ่งยังห่างไกลจากระดับมนุษย์ของเรา ดังนั้น ครั้งต่อไปที่คุณได้ยินใครพูดว่า AI สามารถแทนที่มนุษย์ได้อย่างสมบูรณ์ คุณก็จะหัวเราะได้
ที่อยู่กระดาษ: https://arxiv.org/pdf/2407.06581
หน้าโครงการ: https://vlmsareblind.github.io/
โดยสรุป แม้ว่า VLM จะมีความก้าวหน้าอย่างมากในด้านการรับรู้ภาพ แต่ความสามารถของพวกเขาในการให้เหตุผลเชิงพื้นที่ที่แม่นยำยังคงมีข้อบกพร่องที่สำคัญ การศึกษานี้เตือนเราว่าการประเมินเทคโนโลยี AI ไม่สามารถอาศัยคะแนนสูงเพียงอย่างเดียว แต่ยังต้องอาศัยความเข้าใจอย่างลึกซึ้งเกี่ยวกับข้อจำกัดของมันเพื่อหลีกเลี่ยงการมองโลกในแง่ดีโดยไม่ตั้งใจ เรารอคอยที่ VLM จะสร้างความก้าวหน้าในการทำความเข้าใจด้วยภาพในอนาคต!