บรรณาธิการของ Downcodes จะพาคุณไปเรียนรู้เกี่ยวกับการวิจัยที่ก้าวล้ำโดย Google DeepMind: Mixture of Experts (MoE) งานวิจัยนี้ได้ทำให้เกิดความก้าวหน้าในการปฏิวัติสถาปัตยกรรม Transformer โดยมีแกนหลักอยู่ที่กลไกการดึงข้อมูลจากผู้เชี่ยวชาญที่มีประสิทธิภาพซึ่งใช้เทคโนโลยีคีย์ผลิตภัณฑ์เพื่อสร้างสมดุลระหว่างต้นทุนการคำนวณและจำนวนพารามิเตอร์ ซึ่งจะช่วยปรับปรุงศักยภาพของโมเดลได้อย่างมากในขณะที่ยังคงรักษาประสิทธิภาพไว้ การวิจัยนี้ไม่เพียงสำรวจการตั้งค่า MoE ที่รุนแรงเท่านั้น แต่ยังพิสูจน์เป็นครั้งแรกว่าโครงสร้างดัชนีการเรียนรู้สามารถส่งไปยังผู้เชี่ยวชาญมากกว่าหนึ่งล้านคนได้อย่างมีประสิทธิภาพ ซึ่งนำความเป็นไปได้ใหม่ๆ มาสู่สาขา AI
โมเดล Mixture ผู้เชี่ยวชาญล้านคนที่เสนอโดย Google DeepMind เป็นงานวิจัยที่ได้ดำเนินขั้นตอนการปฏิวัติในสถาปัตยกรรม Transformer
ลองนึกภาพแบบจำลองที่สามารถดึงข้อมูลแบบกระจัดกระจายจากผู้เชี่ยวชาญรายย่อยนับล้านได้ ฟังดูคล้ายกับโครงเรื่องในนิยายวิทยาศาสตร์หรือไม่ แต่นั่นคือสิ่งที่การวิจัยล่าสุดของ DeepMind แสดงให้เห็น แกนหลักของการวิจัยนี้คือกลไกการดึงข้อมูลจากผู้เชี่ยวชาญที่มีประสิทธิภาพด้านพารามิเตอร์ ซึ่งใช้เทคโนโลยีหมายเลขผลิตภัณฑ์เพื่อแยกต้นทุนการคำนวณออกจากการนับพารามิเตอร์ ซึ่งจะช่วยปลดปล่อยศักยภาพที่มากขึ้นของสถาปัตยกรรม Transformer ในขณะที่ยังคงรักษาประสิทธิภาพในการคำนวณ
จุดเด่นของงานนี้คือ ไม่เพียงแต่สำรวจการตั้งค่า MoE ที่รุนแรงเท่านั้น แต่ยังแสดงให้เห็นเป็นครั้งแรกว่าโครงสร้างดัชนีที่เรียนรู้สามารถกำหนดเส้นทางไปยังผู้เชี่ยวชาญกว่าล้านคนได้อย่างมีประสิทธิภาพ นี่เหมือนกับการค้นหาผู้เชี่ยวชาญเพียงไม่กี่คนอย่างรวดเร็วที่สามารถแก้ไขปัญหาในกลุ่มคนจำนวนมาก และทั้งหมดนี้ทำภายใต้สมมติฐานของต้นทุนการประมวลผลที่ควบคุมได้
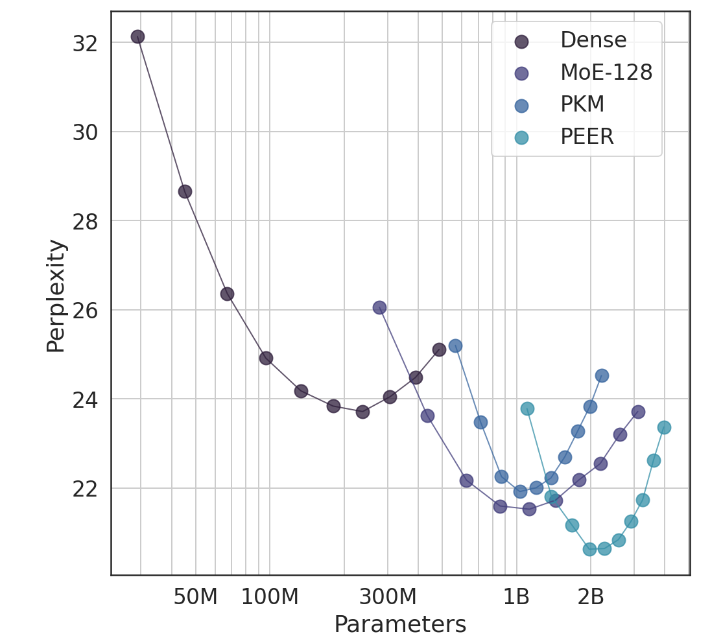
ในการทดลอง สถาปัตยกรรม PEER แสดงให้เห็นถึงประสิทธิภาพการประมวลผลที่เหนือกว่า และมีประสิทธิภาพมากกว่าเลเยอร์ FFW ที่หนาแน่น, MoE แบบหยาบ และหน่วยความจำคีย์ผลิตภัณฑ์ (PKM) นี่ไม่ใช่แค่ชัยชนะทางทฤษฎีเท่านั้น แต่ยังเป็นการก้าวกระโดดครั้งใหญ่ในการใช้งานจริงอีกด้วย จากผลลัพธ์เชิงประจักษ์ เราสามารถมองเห็นประสิทธิภาพที่เหนือกว่าของ PEER ในงานการสร้างแบบจำลองภาษา ไม่เพียงแต่จะมีความซับซ้อนน้อยลงเท่านั้น แต่ยังรวมถึงการทดลองระเหยด้วย โดยการปรับจำนวนผู้เชี่ยวชาญและจำนวนผู้เชี่ยวชาญที่กระตือรือร้น ประสิทธิภาพของ PEER โมเดลได้รับการปรับปรุงอย่างมาก
ผู้เขียนงานวิจัยนี้ Xu He (Owen) เป็นนักวิทยาศาสตร์การวิจัยที่ Google DeepMind การสำรวจด้วยมือเดียวของเขาได้นำการเปิดเผยใหม่ๆ มาสู่สาขา AI อย่างไม่ต้องสงสัย ตามที่เขาแสดงให้เห็น เราสามารถปรับปรุงอัตราคอนเวอร์ชั่นและรักษาผู้ใช้ไว้ได้อย่างมาก ผ่านวิธีการเฉพาะบุคคลและชาญฉลาด ซึ่งมีความสำคัญอย่างยิ่งในด้าน AIGC
ที่อยู่กระดาษ: https://arxiv.org/abs/2407.04153
โดยรวมแล้ว การวิจัยโมเดลไฮบริดโดยผู้เชี่ยวชาญหลายล้านคนของ Google DeepMind มอบแนวคิดใหม่สำหรับการสร้างแบบจำลองภาษาขนาดใหญ่ กลไกการดึงข้อมูลผู้เชี่ยวชาญที่มีประสิทธิภาพและผลการทดลองที่ยอดเยี่ยมบ่งบอกถึงศักยภาพที่ยอดเยี่ยมสำหรับการพัฒนาโมเดล AI ในอนาคต บรรณาธิการของ Downcodes หวังว่าจะได้รับผลการวิจัยที่ก้าวหน้าคล้ายกันนี้มากขึ้น!