ในช่วงไม่กี่ปีที่ผ่านมา นวัตกรรมในโมเดลภาษาขนาดใหญ่ (LLM) ได้เกิดขึ้นทีละตัว ซึ่งท้าทายขีดจำกัดของสถาปัตยกรรมที่มีอยู่อย่างต่อเนื่อง บรรณาธิการของ Downcodes ได้เรียนรู้ว่านักวิจัยจาก Stanford, UCSD, UC Berkeley และ Meta ได้ร่วมกันเสนอสถาปัตยกรรมใหม่ที่เรียกว่า TTT (Test-Time-Training Layers) ด้วยการออกแบบที่ก้าวล้ำนี้ คาดว่าจะเปลี่ยนความเข้าใจในภาษาของเราไปอย่างสิ้นเชิง โมเดลได้รับการยอมรับและนำไปใช้แล้ว ด้วยการรวมข้อดีของ RNN และ Transformer อย่างชาญฉลาด สถาปัตยกรรม TTT ช่วยปรับปรุงความสามารถในการแสดงออกของโมเดลได้อย่างมาก ขณะเดียวกันก็รับประกันความซับซ้อนเชิงเส้น โดยเฉพาะอย่างยิ่งเมื่อประมวลผลข้อความขนาดยาว โดยนำข้อมูลเชิงลึกใหม่ๆ มาสู่สาขาต่างๆ เช่น ความเป็นไปได้ในการสร้างแบบจำลองวิดีโอขนาดยาว
ในโลกของ AI การเปลี่ยนแปลงมักเกิดขึ้นอย่างไม่คาดคิดเสมอ เมื่อไม่นานมานี้ สถาปัตยกรรมใหม่ที่เรียกว่า TTT ได้รับการเสนอร่วมกันโดยนักวิจัยจาก Stanford, UCSD, UC Berkeley และ Meta โดยได้ล้มล้าง Transformer และ Mamba ในชั่วข้ามคืนและนำมาซึ่งการเปลี่ยนแปลงครั้งยิ่งใหญ่ในโมเดลภาษา
TTT หรือชื่อเต็มของเลเยอร์ Test-Time-Training เป็นสถาปัตยกรรมใหม่ล่าสุดที่บีบอัดบริบทผ่านการไล่ระดับสี และแทนที่กลไกความสนใจแบบเดิมโดยตรง วิธีการนี้ไม่เพียงแต่ปรับปรุงประสิทธิภาพเท่านั้น แต่ยังปลดล็อกสถาปัตยกรรมเชิงเส้นที่ซับซ้อนด้วยหน่วยความจำที่แสดงออก ซึ่งช่วยให้เราสามารถฝึกอบรม LLM ที่มีโทเค็นนับล้านหรือหลายพันล้านในบริบท

ข้อเสนอของเลเยอร์ TTT ขึ้นอยู่กับข้อมูลเชิงลึกเกี่ยวกับสถาปัตยกรรม RNN และ Transformer ที่มีอยู่ แม้ว่า RNN จะมีประสิทธิภาพสูง แต่ก็ถูกจำกัดด้วยความสามารถในการแสดงออก ในขณะที่ Transformer มีความสามารถในการแสดงออกที่แข็งแกร่ง แต่ต้นทุนการคำนวณจะเพิ่มขึ้นเป็นเส้นตรงตามความยาวของบริบท เลเยอร์ TTT ผสมผสานข้อดีของทั้งสองอย่างชาญฉลาด โดยรักษาความซับซ้อนเชิงเส้นและเพิ่มความสามารถในการแสดงออก
ในการทดลอง ทั้งสองตัวแปร TTT-Linear และ TTT-MLP แสดงให้เห็นถึงประสิทธิภาพที่ยอดเยี่ยม ซึ่งเหนือกว่า Transformer และ Mamba ทั้งในบริบทระยะสั้นและระยะยาว โดยเฉพาะอย่างยิ่งในสถานการณ์บริบทที่ยาว ข้อดีของเลเยอร์ TTT จะชัดเจนยิ่งขึ้น ซึ่งให้ศักยภาพอย่างมากสำหรับสถานการณ์แอปพลิเคชัน เช่น การสร้างแบบจำลองวิดีโอขนาดยาว
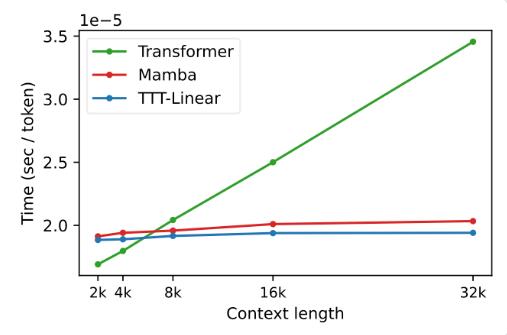
ข้อเสนอของเลเยอร์ TTT ไม่เพียงแต่เป็นนวัตกรรมทางทฤษฎีเท่านั้น แต่ยังแสดงให้เห็นถึงศักยภาพที่ยอดเยี่ยมในการใช้งานจริงอีกด้วย ในอนาคต เลเยอร์ TTT คาดว่าจะนำไปใช้กับการสร้างแบบจำลองวิดีโอขนาดยาวเพื่อให้ข้อมูลที่สมบูรณ์ยิ่งขึ้นโดยการสุ่มตัวอย่างเฟรมที่หนาแน่น นี่เป็นภาระสำหรับ Transformer แต่เป็นพรสำหรับเลเยอร์ TTT
งานวิจัยนี้เป็นผลมาจากการทำงานหนักเป็นเวลาห้าปีของทีมงาน และได้เริ่มดำเนินการมาตั้งแต่ช่วงหลังปริญญาเอกของดร. ยู ซุน พวกเขาพากเพียรในการสำรวจและพยายาม และในที่สุดก็บรรลุผลที่ก้าวหน้านี้ ความสำเร็จของระดับ TTT เป็นผลมาจากความพยายามอย่างไม่หยุดยั้งและจิตวิญญาณแห่งนวัตกรรมของทีม
การถือกำเนิดของเลเยอร์ TTT ได้นำความมีชีวิตชีวาและความเป็นไปได้ใหม่ๆ มาสู่สนาม AI ไม่เพียงแต่เปลี่ยนความเข้าใจของเราเกี่ยวกับโมเดลภาษาเท่านั้น แต่ยังเปิดเส้นทางใหม่สำหรับแอปพลิเคชัน AI ในอนาคตอีกด้วย ให้เราตั้งตารอการใช้งานและการพัฒนาเลเยอร์ TTT ในอนาคต และเป็นสักขีพยานถึงความก้าวหน้าและความก้าวหน้าของเทคโนโลยี AI
ที่อยู่กระดาษ: https://arxiv.org/abs/2407.04620
การเกิดขึ้นของสถาปัตยกรรม TTT ได้เพิ่มความก้าวหน้าในด้าน AI อย่างไม่ต้องสงสัย มารอดูกันว่าสถาปัตยกรรม TTT จะเปลี่ยนโลกของเราไปไกลแค่ไหน