บรรณาธิการของ Downcodes นำเสนอข่าวใหญ่มาให้คุณ! Cerebras Systems เปิดตัวบริการการอนุมาน AI ที่เร็วที่สุดในโลก - Cerebras Inference ซึ่งเปลี่ยนกฎของเกมในด้านการอนุมาน AI ไปอย่างสิ้นเชิง ด้วยความเร็วที่น่าทึ่งและราคาที่แข่งขันได้อย่างมาก ทำงานได้ดีในการประมวลผลโมเดล AI ต่างๆ โดยเฉพาะโมเดลภาษาขนาดใหญ่ (LLM) และเร็วกว่าระบบ GPU แบบดั้งเดิมถึง 20 เท่าในราคาที่ต่ำถึงหนึ่งในสิบหรือหนึ่งร้อยด้วยซ้ำ สิ่งนี้จะส่งผลต่อการพัฒนาแอพพลิเคชั่น AI ในอนาคตอย่างไร? มาดูกันดีกว่า
Cerebras Systems ผู้บุกเบิกด้านการประมวลผล AI ประสิทธิภาพสูง ได้เปิดตัวโซลูชันที่ก้าวล้ำที่จะปฏิวัติการอนุมาน AI เมื่อวันที่ 27 สิงหาคม 2567 บริษัทได้ประกาศเปิดตัว Cerebras Inference ซึ่งเป็นบริการอนุมาน AI ที่เร็วที่สุดในโลก ตัวบ่งชี้ประสิทธิภาพของ Cerebras Inference มีขนาดเล็กกว่าระบบที่ใช้ GPU แบบเดิม โดยให้ความเร็วมากกว่า 20 เท่าด้วยต้นทุนที่ต่ำมาก ถือเป็นการสร้างมาตรฐานใหม่สำหรับการประมวลผล AI
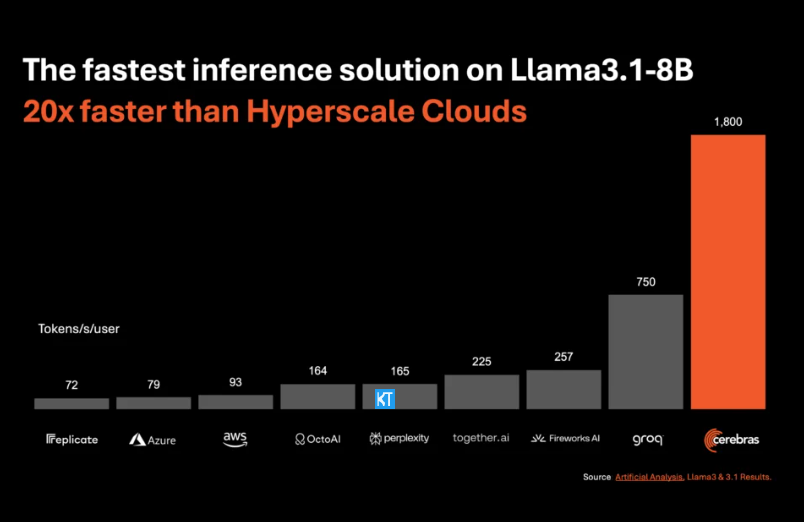
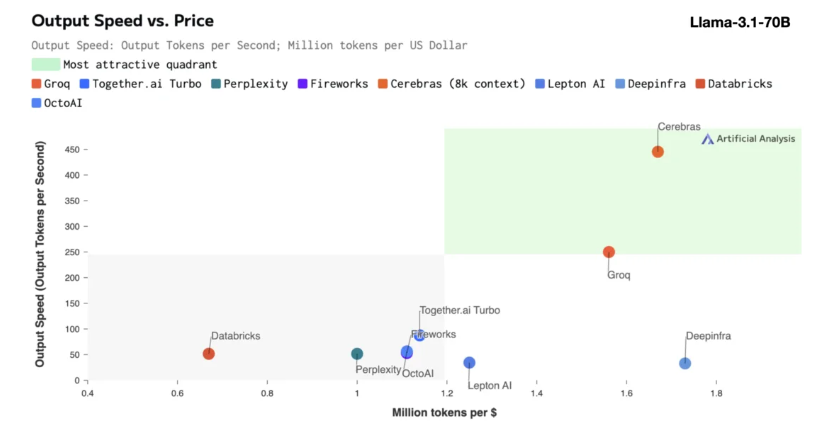
การอนุมานของ Cerebras เหมาะอย่างยิ่งสำหรับการประมวลผลโมเดล AI ประเภทต่างๆ โดยเฉพาะอย่างยิ่ง "โมเดลภาษาขนาดใหญ่" (LLM) ที่พัฒนาอย่างรวดเร็ว ยกตัวอย่างโมเดล Llama3.1 ล่าสุด โดยเวอร์ชัน 8B สามารถประมวลผลโทเค็นได้ 1,800 โทเค็นต่อวินาที ในขณะที่เวอร์ชัน 70B สามารถประมวลผลโทเค็นได้ 450 รายการ ไม่เพียงแต่เร็วกว่าโซลูชัน NVIDIA GPU ถึง 20 เท่าเท่านั้น แต่ยังมีราคาที่แข่งขันได้มากกว่าอีกด้วย ราคาของ Cerebras Inference เริ่มต้นที่เพียง 10 เซนต์ต่อล้านโทเค็น และเวอร์ชัน 70B อยู่ที่ 60 เซนต์ เมื่อเทียบกับผลิตภัณฑ์ GPU ที่มีอยู่ อัตราส่วนราคา/ประสิทธิภาพได้รับการปรับปรุงขึ้น 100 เท่า
เป็นเรื่องที่น่าประทับใจที่ Cerebras Inference บรรลุความเร็วนี้โดยยังคงรักษาความแม่นยำระดับชั้นนำของอุตสาหกรรมไว้ได้ ไม่เหมือนกับโซลูชันที่เน้นความเร็วอื่นๆ Cerebras ทำการอนุมานในโดเมน 16 บิตเสมอ เพื่อให้มั่นใจว่าการปรับปรุงประสิทธิภาพจะไม่ต้องแลกกับคุณภาพเอาต์พุตของโมเดล AI Micha Hill-Smith ซีอีโอของ Artificial Analytics กล่าวว่า Cerebras มีความเร็วมากกว่า 1,800 โทเค็นเอาท์พุตต่อวินาทีบนโมเดล Llama3.1 ของ Meta ซึ่งสร้างสถิติใหม่
การอนุมาน AI คือส่วนที่เติบโตเร็วที่สุดของการประมวลผล AI โดยคิดเป็นประมาณ 40% ของตลาดฮาร์ดแวร์ AI ทั้งหมด การอนุมาน AI ความเร็วสูง เช่น ที่ Cerebras ให้บริการนั้น เปรียบเสมือนการเกิดขึ้นของอินเทอร์เน็ตบรอดแบนด์ การเปิดโอกาสใหม่ๆ และการเปิดศักราชใหม่สำหรับแอปพลิเคชัน AI นักพัฒนาสามารถใช้ Cerebras Inference เพื่อสร้างแอปพลิเคชัน AI ยุคถัดไปที่ต้องการประสิทธิภาพแบบเรียลไทม์ที่ซับซ้อน เช่น เอเจนต์อัจฉริยะและระบบอัจฉริยะ
Cerebras Inference เสนอระดับบริการที่มีราคาสมเหตุสมผลสามระดับ ได้แก่ ระดับฟรี ระดับนักพัฒนา และระดับองค์กร Free Tier ให้การเข้าถึง API พร้อมขีดจำกัดการใช้งานที่กว้างขวาง ทำให้เหมาะสำหรับผู้ใช้ในวงกว้าง ระดับนักพัฒนามีตัวเลือกการปรับใช้แบบไร้เซิร์ฟเวอร์ที่ยืดหยุ่น ในขณะที่ระดับองค์กรให้บริการและการสนับสนุนที่กำหนดเองสำหรับองค์กรที่มีปริมาณงานต่อเนื่อง
ในแง่ของเทคโนโลยีหลัก Cerebras Inference ใช้ระบบ CerebrasCS-3 ซึ่งขับเคลื่อนโดย Wafer Scale Engine3 (WSE-3) ชั้นนำของอุตสาหกรรม โปรเซสเซอร์ AI นี้ไม่มีใครเทียบได้ทั้งในด้านขนาดและความเร็ว โดยให้แบนด์วิธหน่วยความจำมากกว่า NVIDIA H100 ถึง 7,000 เท่า
Cerebras Systems ไม่เพียงแต่เป็นผู้นำกระแสในด้านการประมวลผล AI เท่านั้น แต่ยังมีบทบาทสำคัญในหลายอุตสาหกรรม เช่น การแพทย์ พลังงาน รัฐบาล คอมพิวเตอร์ทางวิทยาศาสตร์ และบริการทางการเงิน ด้วยการพัฒนานวัตกรรมทางเทคโนโลยีอย่างต่อเนื่อง Cerebras กำลังช่วยเหลือองค์กรในสาขาต่างๆ รับมือกับความท้าทายด้าน AI ที่ซับซ้อน
ไฮไลท์:
ความเร็วการให้บริการของ Cerebras Systems เพิ่มขึ้น 20 เท่า ราคาสามารถแข่งขันได้มากขึ้น และเปิดยุคใหม่ของการให้เหตุผลด้วย AI
รองรับโมเดล AI ต่างๆ โดยเฉพาะอย่างยิ่งทำงานได้ดีกับโมเดลภาษาขนาดใหญ่ (LLM)
มีการให้บริการสามระดับเพื่ออำนวยความสะดวกให้กับนักพัฒนาและผู้ใช้ระดับองค์กรในการเลือกอย่างยืดหยุ่น
โดยรวมแล้ว การเกิดขึ้นของ Cerebras Inference ถือเป็นก้าวสำคัญในด้านการอนุมาน AI ประสิทธิภาพที่ยอดเยี่ยมและความประหยัดของมันจะส่งเสริมความนิยมในวงกว้างและการพัฒนานวัตกรรมของแอปพลิเคชัน AI และสมควรได้รับความสนใจและความคาดหวังจากอุตสาหกรรม! เครื่องมือแก้ไขของ Downcodes จะยังคงนำเสนอข้อมูลเทคโนโลยีที่ล้ำสมัยมากขึ้นแก่คุณต่อไป