ปัจจุบัน ด้วยการพัฒนาอย่างรวดเร็วของเทคโนโลยี AI โมเดลภาษาขนาดเล็ก (SLM) ได้รับความสนใจอย่างมาก เนื่องจากความสามารถในการทำงานบนอุปกรณ์ที่มีทรัพยากรจำกัด ทีมงาน Nvidia เพิ่งเปิดตัว Llama-3.1-Minitron4B ซึ่งเป็นโมเดลภาษาขนาดเล็กที่ยอดเยี่ยมซึ่งอิงจากการบีบอัดของโมเดล Llama 3 ใช้เทคโนโลยีการตัดแต่งกิ่งและการกลั่นแบบจำลองเพื่อแข่งขันกับโมเดลขนาดใหญ่ในด้านประสิทธิภาพ ขณะเดียวกันก็มีข้อดีด้านการฝึกอบรมและการใช้งานที่มีประสิทธิภาพ ซึ่งนำความเป็นไปได้ใหม่ๆ มาสู่แอปพลิเคชัน AI บรรณาธิการของ Downcodes จะพาคุณไปทำความเข้าใจอย่างลึกซึ้งเกี่ยวกับความก้าวหน้าทางเทคโนโลยีนี้
ในยุคที่บริษัทเทคโนโลยีกำลังไล่ตามปัญญาประดิษฐ์บนอุปกรณ์ต่างๆ โมเดลภาษาขนาดเล็ก (SLM) ก็มีเพิ่มมากขึ้นเรื่อยๆ และสามารถทำงานบนอุปกรณ์ที่มีทรัพยากรจำกัดได้ เมื่อเร็วๆ นี้ ทีมวิจัยของ Nvidia ใช้เทคโนโลยีการตัดแต่งกิ่งและการกลั่นแบบจำลองที่ล้ำสมัยเพื่อเปิดตัว Llama-3.1-Minitron4B ซึ่งเป็นเวอร์ชันบีบอัดของรุ่น Llama3 รุ่นใหม่นี้ไม่เพียงแต่สามารถเทียบเคียงได้ในด้านประสิทธิภาพกับรุ่นใหญ่เท่านั้น แต่ยังแข่งขันกับรุ่นเล็กที่มีขนาดเท่ากัน ในขณะที่มีประสิทธิภาพมากขึ้นในการฝึกอบรมและการใช้งาน
การตัดแต่งกิ่งและการกลั่นเป็นเทคนิคสำคัญสองประการในการสร้างแบบจำลองภาษาที่มีขนาดเล็กลงและมีประสิทธิภาพมากขึ้น การตัดแต่งกิ่งหมายถึงการลบส่วนที่ไม่สำคัญของแบบจำลอง รวมถึง "การตัดเชิงลึก" - การลบเลเยอร์ทั้งหมดออก และ "การตัดความกว้าง" - การลบองค์ประกอบเฉพาะ เช่น เซลล์ประสาทและส่วนหัวของความสนใจ ในทางกลับกัน การกลั่นแบบจำลองเป็นการถ่ายทอดความรู้และความสามารถจากแบบจำลองขนาดใหญ่ (เช่น "แบบจำลองครู") ไปยัง "แบบจำลองนักเรียน" ที่เล็กกว่าและง่ายกว่า
การกลั่นมีสองวิธีหลัก วิธีแรกคือผ่าน "การฝึกอบรม SGD" ซึ่งช่วยให้โมเดลนักเรียนเรียนรู้ข้อมูลและการตอบสนองของโมเดลครู วิธีที่สองคือ "การกลั่นความรู้แบบคลาสสิก" ในที่นี้ นอกเหนือจากผลการเรียนรู้ โมเดลนักเรียนยังต้องการการเปิดใช้งานโมเดลครูการเรียนรู้ภายในด้วย
ในการศึกษาก่อนหน้านี้ นักวิจัยของ Nvidia ประสบความสำเร็จในการลดโมเดล Nemotron15B เหลือโมเดลพารามิเตอร์ 800 ล้านตัวผ่านการตัดแต่งกิ่งและการกลั่น และในที่สุดก็ลดเหลือพารามิเตอร์อีก 400 ล้านพารามิเตอร์ในที่สุด กระบวนการนี้ไม่เพียงเพิ่มประสิทธิภาพขึ้น 16% จากเกณฑ์มาตรฐาน MMLU ที่มีชื่อเสียง แต่ยังใช้ข้อมูลการฝึกอบรมน้อยกว่าการฝึกอบรมตั้งแต่เริ่มต้นถึง 40 เท่า
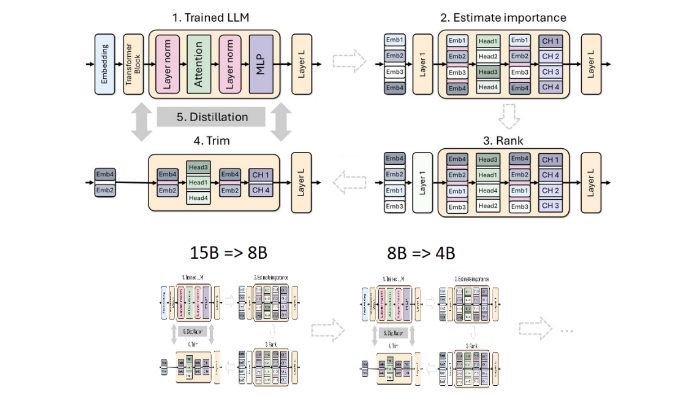
ครั้งนี้ ทีมงาน Nvidia ใช้วิธีการเดียวกันในการสร้างแบบจำลองพารามิเตอร์ 400 ล้านตัวตามรุ่น Llama3.18B ขั้นแรก พวกเขาปรับแต่งโมเดล 8B ที่ยังไม่ได้ตัดบนชุดข้อมูลที่มีโทเค็น 94 พันล้านโทเค็น เพื่อรับมือกับความแตกต่างในการกระจายระหว่างข้อมูลการฝึกและชุดข้อมูลที่กลั่นแล้ว จากนั้นจึงใช้วิธีการตัดความลึกและความกว้างสองวิธี และสุดท้ายก็ได้ Llama-3.1-Minitron4B สองเวอร์ชันที่แตกต่างกัน
นักวิจัยได้ปรับแต่งโมเดลที่ถูกตัดออกอย่างละเอียดผ่าน NeMo-Aligner และประเมินความสามารถในการปฏิบัติตามคำสั่ง การสวมบทบาท การสร้างเสริมการดึงข้อมูล (RAG) และการเรียกใช้ฟังก์ชัน
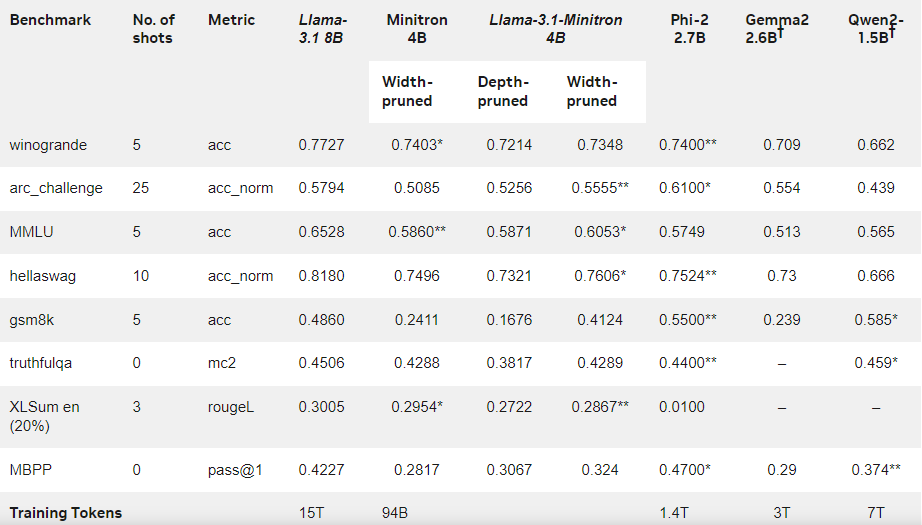
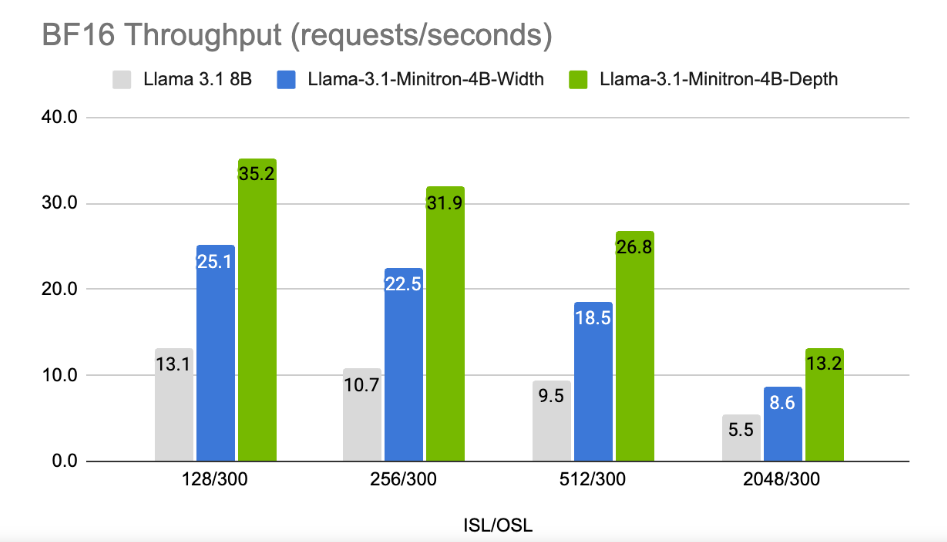
ผลการวิจัยพบว่าแม้จะมีข้อมูลการฝึกเพียงเล็กน้อย แต่ประสิทธิภาพของ Llama-3.1-Minitron4B ยังคงใกล้เคียงกับรุ่นขนาดเล็กอื่นๆ และทำงานได้ดี โมเดลเวอร์ชันลดความกว้างได้รับการเผยแพร่บน Hugging Face แล้ว ทำให้สามารถนำไปใช้ในเชิงพาณิชย์เพื่อช่วยให้ผู้ใช้และนักพัฒนาจำนวนมากขึ้นได้รับประโยชน์จากประสิทธิภาพและประสิทธิภาพที่ยอดเยี่ยม
บล็อกอย่างเป็นทางการ: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
ไฮไลท์:
Llama-3.1-Minitron4B เป็นรูปแบบภาษาขนาดเล็กที่เปิดตัวโดย Nvidia โดยอิงจากเทคโนโลยีการตัดแต่งกิ่งและการกลั่น พร้อมการฝึกอบรมและความสามารถในการปรับใช้ที่มีประสิทธิภาพ
จำนวนมาร์กเกอร์ที่ใช้ในกระบวนการฝึกของรุ่นนี้ลดลง 40 เท่าเมื่อเทียบกับการฝึกตั้งแต่เริ่มต้น แต่ประสิทธิภาพได้รับการปรับปรุงอย่างมาก
? รุ่นตัดความกว้างได้รับการเผยแพร่บน Hugging Face เพื่ออำนวยความสะดวกให้ผู้ใช้นำไปใช้ในเชิงพาณิชย์และการพัฒนา
โดยรวมแล้ว การเกิดขึ้นของ Llama-3.1-Minitron4B ถือเป็นหลักชัยสำคัญในการพัฒนาโมเดลภาษาขนาดเล็ก ประสิทธิภาพที่มีประสิทธิภาพและวิธีการใช้งานที่สะดวกสบายของ Llama-3.1-Minitron4B จะนำข่าวดีมาสู่นักพัฒนาและผู้ใช้จำนวนมากขึ้น และเร่งให้เกิดความนิยมและการประยุกต์ใช้เทคโนโลยี AI บรรณาธิการของ Downcodes รอคอยที่จะมีนวัตกรรมที่คล้ายกันมากขึ้นในอนาคต